[2026-01-29] VTC-R1: 텍스트를 이미지로 압축하는 '광학 메모리' 혁신 - 롱 컨텍스트 추론의 병목을 해결하는 새로운 패러다임

VTC-R1: Vision-Text Compression을 통한 효율적 롱 컨텍스트 추론의 새 지평
1. Executive Summary (핵심 요약)
인공지능 추론 능력의 비약적 발전은 곧 ‘추론 토큰(Reasoning Tokens)’의 폭발적인 증가를 의미합니다. OpenAI의 o1이나 DeepSeek-R1과 같은 모델들은 복잡한 문제를 해결하기 위해 수만 토큰에 달하는 사고 과정(Chain-of-Thought, CoT)을 생성하며, 이는 고스란히 연산 비용과 지연 시간(Latency)의 증가로 이어집니다. 본 고문에서는 이러한 롱 컨텍스트(Long-context) 추론의 효율성 문제를 근본적으로 해결하기 위해 제안된 VTC-R1(Vision-Text Compression for Efficient Long-Context Reasoning) 프레임워크를 심층 분석합니다.
VTC-R1의 핵심 아이디어는 간단하지만 혁신적입니다. 길게 늘어지는 텍스트 추론 과정을 시각적인 ‘이미지’로 렌더링하여 모델의 ‘광학 메모리(Optical Memory)’로 활용하는 것입니다. 이를 통해 기존 텍스트 기반 방식 대비 3.4배의 토큰 압축률과 2.7배의 추론 속도 향상을 달성함과 동시에, MATH500, AIME25 등 주요 벤치마크에서 기존 롱 컨텍스트 모델을 능가하는 성능을 입증했습니다. 이는 시각-언어 모델(VLM)이 단순히 이미지를 이해하는 도구를 넘어, 자체적인 효율적 추론 엔진으로 진화할 수 있음을 시사합니다.
2. Introduction & Problem Statement (연구 배경 및 문제 정의)
2.1. 롱 컨텍스트 추론의 역설
현대 LLM은 ‘생각하는 시간’을 늘림으로써 복잡한 추론 문제를 해결하는 능력을 갖추게 되었습니다. 그러나 이 과정에서 발생하는 수천, 수만 개의 중간 추론 토큰은 두 가지 치명적인 문제를 야기합니다.
- 연산 복잡도: Transformer 아키텍처의 셀프 어텐션(Self-attention) 메커니즘은 시퀀스 길이에 따라 연산량이 제곱(Quadratic) 혹은 선형적(Flash Attention 적용 시)으로 증가하지만, KV 캐시(Key-Value Cache)의 크기가 비대해지면서 메모리 대역폭 한계에 부딪힙니다.
- 정보 밀도 부족: 텍스트 형태의 추론 과정에는 불필요한 수식 전개나 반복적인 설명이 포함되어 정보 밀도가 낮습니다. 인간은 복잡한 논증을 볼 때 전체적인 구조를 시각적으로 파악하지만, LLM은 모든 텍스트 토큰을 개별적으로 처리해야 합니다.
2.2. 기존 압축 방식의 한계
기존의 효율적 추론 기법들은 크게 KV 캐시 프루닝(Pruning), 토큰 병합(Merging), 혹은 별도의 요약 모델(Summary model)을 사용하는 방식으로 나뉩니다. 하지만 이러한 방식들은 다음과 같은 문제점이 있습니다.
- 미세 정보 손실: 중요한 논리적 연결 고리가 프루닝 과정에서 제거될 위험이 큼.
- 추가 학습의 복잡성: 압축을 위한 별도의 인코더나 외부 모델이 필요하여 확장성이 떨어짐.
- 확장성 부재: 모델의 크기가 커질수록 압축 메커니즘을 튜닝하는 비용이 기하급수적으로 증가함.
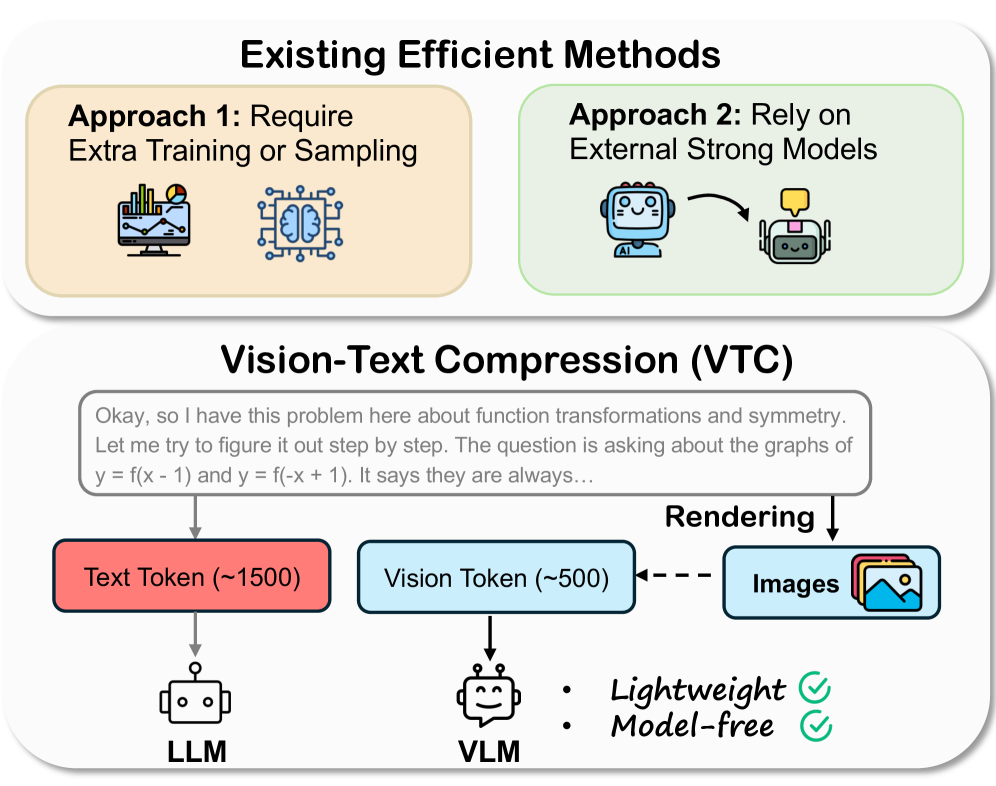 그림 1: 기존의 복잡한 압축 방식들과 달리, VTC는 가벼운 렌더링을 통해 텍스트를 이미지로 변환하여 모델 프리(Model-free)한 방식으로 고효율 압축을 달성합니다.
그림 1: 기존의 복잡한 압축 방식들과 달리, VTC는 가벼운 렌더링을 통해 텍스트를 이미지로 변환하여 모델 프리(Model-free)한 방식으로 고효율 압축을 달성합니다.
3. Core Methodology (핵심 기술 및 아키텍처 심층 분석)
3.1. Vision-Text Compression (VTC) 패러다임
VTC-R1은 추론 과정을 텍스트 시퀀스가 아닌 반복적인 이미지 피드백 루프로 재정의합니다. 이 과정은 다음과 같은 단계로 이루어집니다.
- 세그먼트 생성 (Segment Generation): 모델이 주어진 문제에 대해 첫 번째 추론 단계(Segment)를 텍스트로 생성합니다.
- 시각적 렌더링 (Visual Rendering): 생성된 텍스트 세그먼트를 고해상도 이미지로 렌더링합니다. 이때 LaTeX 수식이나 논리적 구조가 시각적으로 보존됩니다.
- 광학 메모리 통합 (Optical Memory Integration): 렌더링된 이미지는 다음 추론 단계에서 모델의 입력으로 다시 들어갑니다. 모델은 이전 단계의 ‘이미지’와 현재의 ‘질문’을 동시에 보며 다음 텍스트 세그먼트를 생성합니다.
- 반복 (Iteration): 정답에 도달할 때까지 위 과정을 반복합니다.
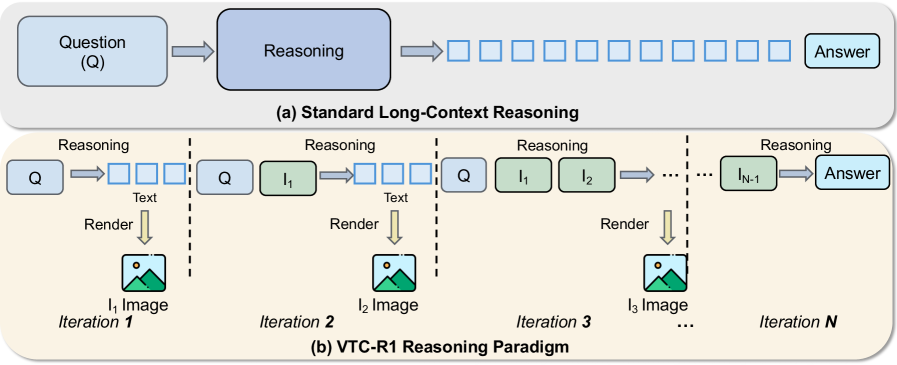 그림 2: 표준적인 롱 컨텍스트 추론과 VTC-R1의 비교. VTC-R1은 이전 추론 단계를 이미지(광학 메모리)로 압축하여 컨텍스트 창의 부담을 획기적으로 줄입니다.
그림 2: 표준적인 롱 컨텍스트 추론과 VTC-R1의 비교. VTC-R1은 이전 추론 단계를 이미지(광학 메모리)로 압축하여 컨텍스트 창의 부담을 획기적으로 줄입니다.
3.2. 왜 이미지가 텍스트보다 효율적인가?
이론적으로 텍스트 토큰은 추상적이지만, 긴 문맥에서는 어텐션 맵이 분산됩니다. 반면, 잘 설계된 Vision Transformer(ViT)는 이미지 내의 공간적 관계를 통해 정보를 효율적으로 인코딩합니다. VTC-R1 연구진은 텍스트를 이미지로 렌더링할 경우, 동일한 정보를 전달하는 데 필요한 비전 토큰 수가 텍스트 토큰 수보다 약 3~4배 적다는 점을 발견했습니다. 이는 컨텍스트 길이에 따른 연산량 증가 곡선을 완만하게 만드는 결정적인 요인이 됩니다.
3.3. 데이터셋 구축: OpenR1-Math-220K의 변환
VTC-R1의 학습을 위해 연구진은 기존의 고품질 추론 데이터셋인 OpenR1-Math-220K를 활용했습니다. 이 데이터셋의 추론 과정을 여러 개의 세그먼트로 나누고, 각 단계별로 “이전 단계 이미지 + 현재 질문 -> 다음 단계 텍스트”의 형태로 가공했습니다.
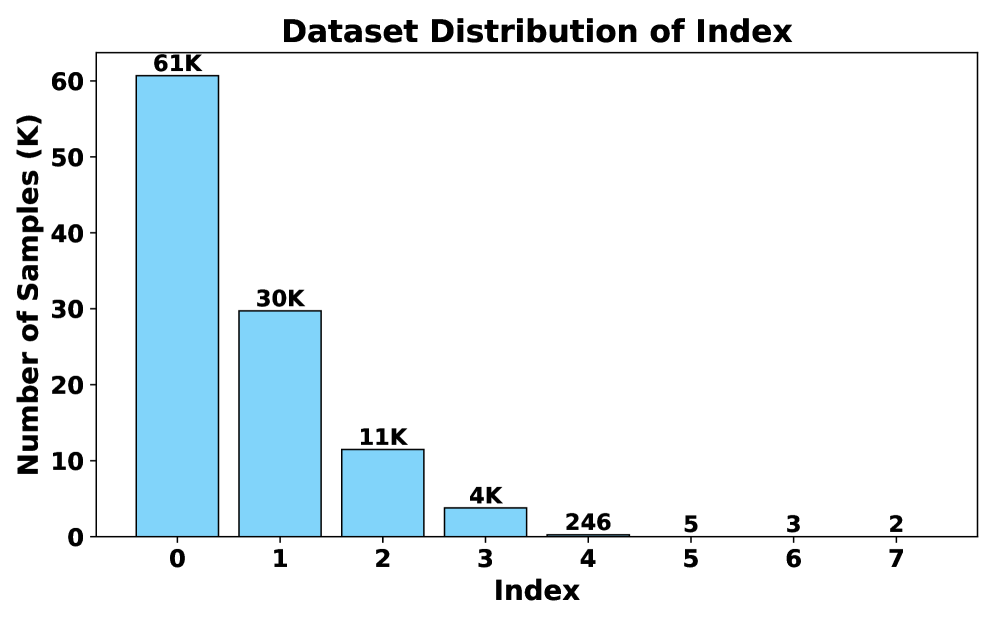 그림 3: 데이터 인덱스 분포. 대부분의 추론은 초기 단계에서 완료되지만, 복잡한 문제일수록 다단계의 이미지-텍스트 피드백 루프가 생성됨을 알 수 있습니다.
그림 3: 데이터 인덱스 분포. 대부분의 추론은 초기 단계에서 완료되지만, 복잡한 문제일수록 다단계의 이미지-텍스트 피드백 루프가 생성됨을 알 수 있습니다.
4. Implementation Details & Experiment Setup (구현 및 실험 환경)
4.1. 모델 아키텍처
VTC-R1은 시각적 이해 능력이 뛰어난 두 가지 대표적 VLM을 기반으로 구현되었습니다.
- Glyph-ByT5 기반 VLM: 텍스트 렌더링 및 OCR 능력에 특화된 모델.
- Qwen3-VL: 최신 멀티모달 벤치마크에서 압도적인 성능을 보이는 모델.
학습 과정에서는 SFT(Supervised Fine-Tuning)가 적용되었으며, 모델이 이미지 속에 담긴 수식과 논리적 맥락을 정확히 읽어내어 다음 단계로 이어가도록 학습되었습니다.
4.2. 렌더링 파이프라인
텍스트를 이미지로 바꿀 때 중요한 것은 ‘가독성’입니다. 연구진은 Pygame과 PIL 라이브러리를 사용하여 텍스트를 고정된 너비의 이미지로 렌더링했습니다. 수식은 LaTeX 스타일을 유지하여 모델이 수식의 구조적 특성을 시각적으로 파악할 수 있도록 설계했습니다.
5. Comparative Analysis (성능 평가 및 비교)
5.1. 추론 정확도 (Accuracy)
MATH500, AIME25, GPQA-D 등의 고난도 벤치마크에서 VTC-R1은 놀라운 결과를 보여주었습니다. 특히, 단순히 텍스트를 입력하는 표준 모델보다 높은 정확도를 기록했는데, 이는 이미지를 통한 ‘광학 메모리’가 오히려 긴 텍스트에서 발생할 수 있는 ‘Lost in the Middle’ 현상(문맥 중간의 정보를 놓치는 현상)을 방지하는 효과가 있음을 입증합니다.
5.2. 효율성 (Efficiency)
- 토큰 압축률: 평균 3.4x. 기존 1,000 토큰 분량의 텍스트 추론이 약 300개 미만의 비전 토큰으로 대체되었습니다.
- 추론 속도 (Latency): 엔드-투-엔드 지연 시간이 2.7배 단축되었습니다. 이는 실시간 응답이 중요한 서비스 환경에서 엄청난 이점입니다.
- KV 캐시 절감: 메모리 점유율이 획기적으로 낮아져, 동일 GPU 자원에서 더 많은 동시 요청(Throughput)을 처리할 수 있게 되었습니다.
6. Real-World Application & Impact (실제 적용 분야 및 파급력)
전문가로서 필자는 VTC-R1이 단순한 연구 논문을 넘어 산업계에 미칠 영향이 매우 클 것으로 전망합니다.
- 에지 컴퓨팅 및 모바일 AI: 메모리 제약이 심한 모바일 기기에서 롱 컨텍스트 추론을 수행할 때, VTC 기술은 필수적인 요소가 될 것입니다. 텍스트를 이미지로 캐싱하는 방식은 메모리 관리 측면에서 매우 효율적입니다.
- 복잡한 STEM 교육 플랫폼: 수학 문제 풀이나 과학적 증명 과정은 시각적 구조가 중요합니다. VTC-R1은 단계별 풀이 과정을 시각적으로 요약하고 관리함으로써, 사용자에게 더 직관적인 피드백을 제공하는 AI 튜터 시스템에 적합합니다.
- 코드 리뷰 및 대규모 프로젝트 분석: 수천 줄의 코드를 분석할 때, 코드의 구조(Structure)를 이미지화하여 ‘광학 맵’으로 활용한다면 어텐션의 한계를 극복하고 전체 프로젝트의 맥락을 유지하며 정교한 추론이 가능해질 것입니다.
7. Discussion: Limitations & Critical Critique (한계점 및 기술적 비평)
물론 VTC-R1이 완벽한 것은 아닙니다. 기술적 관점에서 몇 가지 비판적 시각을 제기할 수 있습니다.
- OCR 성능에 대한 의존도: 모델이 이미지 내의 텍스트를 잘못 읽을 경우(Hallucination), 전체 추론 사슬이 붕괴될 위험이 있습니다. 즉, 비전 인코더의 품질이 전체 시스템의 신뢰도를 결정하는 병목이 됩니다.
- 렌더링 오버헤드: 텍스트를 이미지로 변환하는 CPU/GPU 연산 비용이 추가됩니다. 비록 전체 추론 시간에 비하면 미미할 수 있으나, 아주 짧은 추론에서는 오히려 배보다 배꼽이 더 클 수 있습니다.
- 정보 밀도의 한계: 매우 복잡하고 빽빽한 텍스트를 한 장의 이미지로 압축할 때, 폰트 크기가 작아지면서 발생하는 에일리어싱(Aliasing) 문제가 정보 손실을 야기할 수 있습니다. 이를 해결하기 위해 동적 해상도(Dynamic Resolution) 기술이 추가로 필요할 것입니다.
- 추론 단계의 이산화(Discretization): 어느 시점에서 이미지를 렌더링하고 넘길 것인가에 대한 기준이 모호합니다. 문장 단위인가, 문단 단위인가? 이 최적의 지점을 찾는 알고리즘이 부족합니다.
8. Conclusion (결론 및 인사이트)
VTC-R1은 텍스트 중심의 AI 추론 패러다임을 ‘시각적 메모리’로 확장한 매우 영리한 접근법입니다. 이는 단순히 토큰을 줄이는 기술이 아니라, 인간이 정보를 인지하고 기억하는 방식(시각적 요약)을 머신러닝 아키텍처에 이식한 사례로 평가할 수 있습니다.
앞으로의 추론 모델은 단순히 텍스트 토큰을 쏟아내는 것이 아니라, 스스로 자신의 사고 과정을 시각적으로 요약하고 이를 고도로 압축된 형태의 ‘지식 맵’으로 관리하게 될 것입니다. VTC-R1은 그 거대한 변화의 시작점이며, 효율성과 성능이라는 두 마리 토끼를 잡으려는 모든 AI 개발자와 연구자들에게 강력한 영감을 제공합니다.
핵심 한 줄 평: “텍스트의 늪에서 허우적대던 LLM에게 ‘이미지’라는 고속도로를 깔아준 혁신적 시도.”
