[2026-03-24] 몬스터 헌터가 AI 월드 모델을 구원한다고? 픽셀의 한계를 부수는 WildWorld 데이터셋 해부

[Paper Metadata]
- Project Page: https://shandaai.github.io/wildworld-project/
- ArXiv ID: 2603.23497
- Authors: Shanda AI, etc.
요즘 쏟아지는 비디오 생성 AI들, 겉보기엔 정말 화려하죠? 텍스트 몇 줄 치면 영화 같은 장면이 뚝딱 나옵니다. 근데 막상 이걸로 ‘인터랙티브 게임’이나 ‘물리 엔진’을 대체하려고 하면 숨이 턱 막히는 걸 경험하셨을 겁니다. 왜 그럴까요?
이 녀석들은 그저 ‘이전 픽셀이 이러니까 다음 픽셀은 대충 이러겠지?’ 하고 때려 맞추는 통계적 앵무새에 불과하거든요. 캐릭터가 검을 휘두를 때 뼈대가 어떻게 움직이는지, 카메라 앵글이 어떻게 돌아가는지, 즉 ‘상태(State)’와 ‘액션(Action)’의 인과관계 따위는 안중에도 없습니다. 그래서 3초만 지나면 캐릭터 팔다리가 3개로 늘어나는 복사 버그가 터지는 거죠.
이 지긋지긋한 ‘픽셀 환각(Pixel Hallucination)’ 문제를 해결하겠다고 AAA급 게임의 심장부를 뜯어온 미친 연구가 등장했습니다. 바로 몬스터 헌터: 와일즈(Monster Hunter: Wilds)에서 1억 8천만 프레임을 추출해 만든 WildWorld 데이터셋입니다.
💡 TL;DR: 단순 픽셀 변화에 의존하던 기존 월드 모델의 멱살을 잡고, 깊이(Depth), 뼈대(Skeleton), 카메라 포즈 등 ‘명시적 상태(Explicit State)’를 강제 주입해 진짜 물리 법칙과 액션을 학습시키는 초거대 게임 기반 데이터셋입니다.
⚙️ 픽셀 쪼가리가 아닌 ‘상태(State)’를 연성하는 파이프라인
기존 비디오 데이터셋(Kinetics, Ego4D 등)은 그냥 유튜브 영상 긁어와서 텍스트 캡션 달아놓은 게 전부였습니다. 모델 입장에서는 ‘행동(Action)’이 어떻게 ‘결과(Pixel)’로 이어지는지 추론하기가 지옥 같았죠.
하지만 WildWorld는 게임 엔진의 메모리에서 직접 데이터를 후킹(Hooking)해버립니다. 아래 파이프라인을 볼까요?
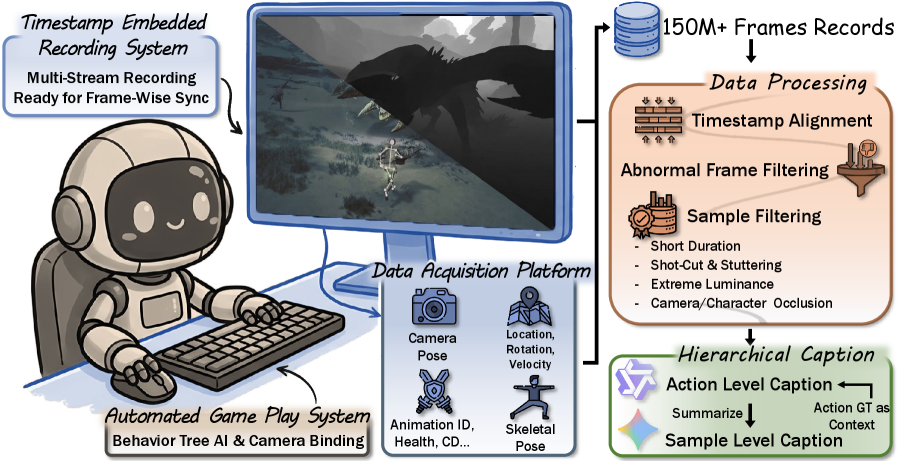
- [그림 설명] 게임 엔진에서 단순히 화면만 녹화하는 게 아니라, 내부 스테이트 머신(State Machine)과 렌더링 파이프라인에서 뼈대, 뎁스, 카메라 정보를 실시간으로 뽑아내는 WildWorld의 데이터 수집 아키텍처입니다.
이 파이프라인을 거치면 단순한 .mp4 파일이 아니라, 완벽하게 동기화된 멀티모달 텐서 덩어리가 탄생합니다. 이걸 코드로 까보면 대략 이런 형태의 데이터를 다루게 된다는 뜻입니다.
1
2
3
4
5
6
7
8
9
10
11
class WildWorldDataset(Dataset):
def __getitem__(self, idx):
# 단순 RGB가 아니라 액션과 상태가 완벽히 매핑된 딕셔너리 리턴
return {
"rgb": load_image(f"frame_{idx}.png"), # [3, 256, 256]
"depth": load_exr(f"depth_{idx}.exr"), # [1, 256, 256]
"camera_pose": load_json(f"cam_{idx}.json"), # [4, 4] Extrinsics matrix
"skeleton": load_tensor(f"skel_{idx}.pt"), # [Num_Joints, 3]
"action_id": 204, # 대검 내려찍기 (Discrete Action)
"state_vector": [0.8, 1.2, ...] # 캐릭터의 물리적 상태값
}
핵심은 행동(Action) -> 상태(State) -> 관측(Observation/Pixel) 으로 이어지는 동역학(Dynamics)을 모델이 명시적으로 학습할 수 있다는 겁니다. 기존 프롬프트 기반 생성 모델이 text_encoder(prompt) 결과를 어텐션 레이어에 태웠다면, 이제는 action_embedding과 state_embedding이 그 자리를 대체하게 됩니다. 모델이 공간 지각 능력을 가질 수밖에 없는 구조죠.
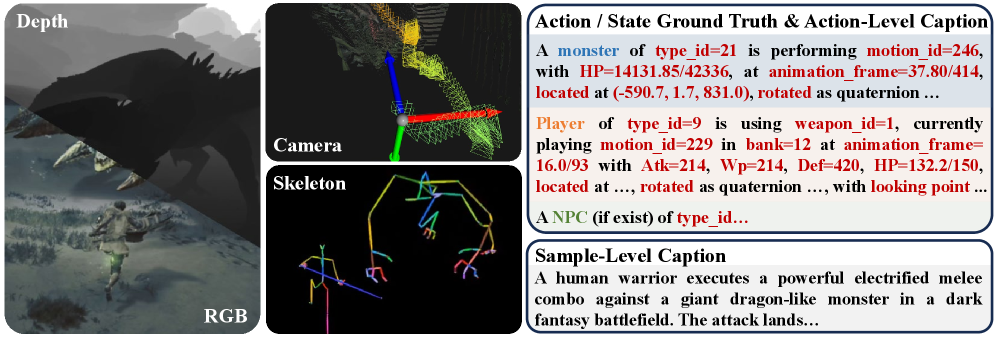
- [그림 설명] 단순 텍스트 캡션을 넘어, 카메라 포즈와 3D 스켈레톤, 그리고 프레임 단위의 액션 라벨이 어떻게 하나의 타임라인으로 묶여 있는지 보여주는 핵심 데이터 구조입니다.
⚔️ 기존 데이터셋 vs WildWorld: 진짜 쓸모가 있을까?
솔직히 데이터셋 논문들, 벤치마크 점수 자랑만 하고 막상 다운로드 받아보면 노이즈 덩어리인 경우가 태반이죠. 기존 SOTA 비디오 데이터셋들과 스펙을 냉정하게 비교해 보겠습니다.
| 데이터셋 | 주 목적 | Action Space | State Annotation | Camera Pose | 훈련 시 I/O 병목 위험 |
|---|---|---|---|---|---|
| Ego4D | 1인칭 행동 인식 | Vague (Text-based) | ❌ 없음 | ❌ 부정확함 | 낮음 (일반 비디오 IO) |
| OpenVid-1M | Text-to-Video | None (Prompt only) | ❌ 없음 | ❌ 없음 | 낮음 |
| WildWorld | Generative ARPG | 450+ Explicit IDs | ✅ 3D Skeleton & Depth | ✅ Exact Matrix | 매우 높음 (멀티모달 로딩) |
표를 보면 알겠지만, WildWorld는 차원이 다릅니다. 특히 450개가 넘는 ‘명시적 액션 ID(이동, 공격, 스킬 캐스팅 등)’가 프레임 단위로 꽂혀 있다는 건, 강화학습(RL) 에이전트를 학습시키거나 조이패드 입력에 반응하는 AI 게임 엔진을 만들 때 엄청난 무기가 됩니다.
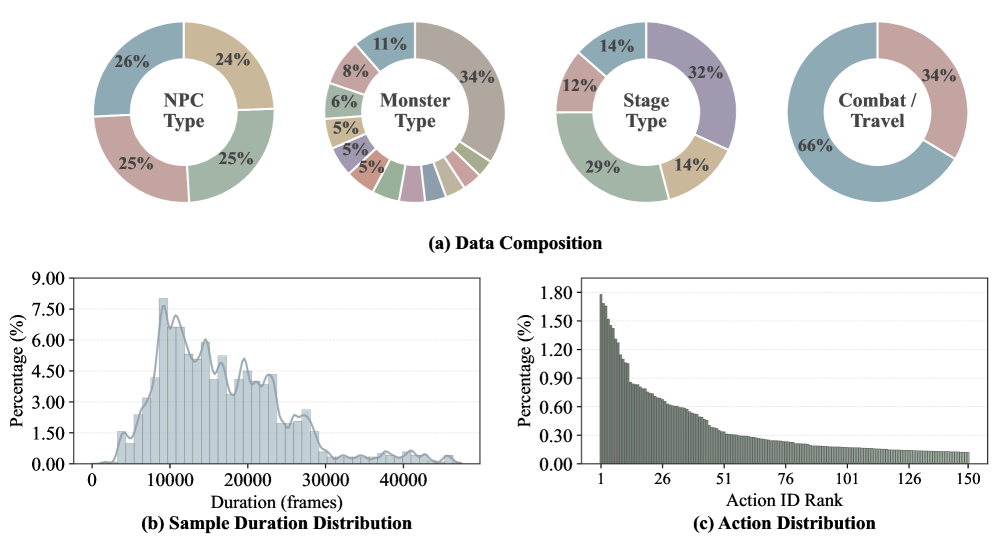
- [그림 설명] 1억 8천만 프레임의 데이터 분포입니다. 특정 액션에 치우치지 않고 이동, 전투 등 롱테일(Long-tail) 액션들이 촘촘하게 분포되어 있어 모델의 과적합(Overfitting)을 방지합니다.
하지만 표 마지막 열의 ‘I/O 병목 위험’을 주목해야 합니다. 일반적인 비디오 디코딩만 해도 CPU 터지는데, 프레임마다 EXR 뎁스 맵과 JSON 스켈레톤 데이터를 메모리에 같이 올려야 합니다. 데이터로더(DataLoader) 최적화 제대로 안 하면 GPU는 팽팽 놀고 CPU만 비명 지르는 꼴을 보게 될 겁니다.
🚀 내일 당장 프로덕션에 도입한다면?
이 미친 데이터셋을 우리 인프라에 끌고 온다면 어떤 시나리오가 가능할까요?
1. 조이패드로 조종하는 Generative ARPG 엔진 구축 더 이상 언리얼이나 유니티 엔진의 렌더링 파이프라인에 의존하지 않고, 모델 자체가 물리 엔진 역할을 하는 겁니다. 유저가 ‘X 버튼(회피)’을 누르면 그 액션 ID가 조건부(Condition)로 입력되어, 다음 프레임의 캐릭터 뼈대와 배경이 렌더링되는 구조죠.
2. 로보틱스 및 Sim-to-Real 프리트레이닝 비록 도메인은 ‘몬스터 헌터’라는 판타지 게임이지만, ‘복잡한 3D 환경에서의 동적 움직임과 카메라 시점 변화’를 학습한다는 점은 로보틱스 시뮬레이터와 완벽히 일치합니다. 대규모 State-Action 매핑을 프리트레이닝(Pre-training)하는 용도로는 이만한 장난감이 없습니다.

- [그림 설명] WildWorld 데이터로 학습된 다양한 모델들의 생성 결과 비교입니다. 단순 비디오 예측을 넘어 유저의 액션 명령에 따라 일관성 있게 월드가 변화하는 모습을 확인할 수 있습니다.
🧐 Tech Lead’s Honest Verdict
👍 Pros (좋은 점):
- 픽셀과 텍스트의 느슨한 결합을 끊고, ‘액션’과 ‘상태’라는 하드코어한 제약조건을 걸어버렸습니다. 비디오 생성 모델이 환각을 멈추고 진짜 ‘월드 모델’로 진화할 수 있는 강력한 초석입니다.
- 뎁스와 카메라 포즈가 완벽히 동기화되어 있어 NeRF나 3D Gaussian Splatting 연구자들에게도 군침 도는 재료입니다.
👎 Cons (아쉬운 점):
- 스토리지와 I/O의 압박: 1억 8천만 프레임의 멀티모달 데이터입니다. S3에 올려놓고 쓸 생각이라면 AWS 청구서 볼 때 청심환부터 챙기세요.
- 도메인 편향성: 아무리 방대해도 결국 ‘몬스터 헌터’라는 특정 게임 환경(그래픽, 물리법칙)에 과적합될 위험이 큽니다. 이 모델이 실사 환경이나 다른 장르의 게임에서도 Generalization이 될지는 심각한 의문입니다.
🔥 최종 판정: [부분적 클론 후 R&D 테스트 권장] 당장 프로덕션 레벨의 파운데이션 모델을 처음부터 굽는 건 자본 낭비입니다. 하지만 10만 프레임 규모의 서브셋(Subset)만 샘플링해서, State-Conditioned Diffusion 모델의 PoC(Proof of Concept)를 진행해 보는 것은 강력히 추천합니다. 픽셀 너머의 진짜 ‘세계’를 모델링하고 싶은 엔지니어라면 이 데이터셋 구조는 반드시 뜯어보셔야 합니다.
