[2026-02-25] 로봇은 어떻게 미래를 그리는가? VLA의 판도를 바꿀 WoG 분석

📖 논문: arXiv:2602.22010 🖥️ Github/Project: Project Page 📅 발표일: 2026년 2월 ✍️ 저자/기관: WoGNet Research Team
요즘 VLA (Vision-Language-Action) 모델이 로보틱스 판을 다 씹어먹고 있다는 거, 다들 알고 계시죠? RT-2 오픈소스 버전들이 쏟아지면서 로봇에게 “사과 집어줘”라고 말하면 척척 해내는 시대가 왔습니다.
하지만 실무에서 로봇을 굴려본 분들은 아실 겁니다. “대충은 잘 하는데, 디테일이 너무 떨어진다”는 것을요. 1mm의 오차가 실패로 이어지는 정밀 조작에서는 기존 VLA 모델들이 픽픽 쓰러집니다. 왜 그럴까요? 모델이 ‘현재 상태’만 보고 ‘다음 행동’을 찍어내기 바빠서, 자신의 행동이 만들어낼 ‘미래의 결과’를 명확하게 상상하지 못하기 때문입니다.
오늘 리뷰할 WoG (World Guidance)는 이 문제를 굉장히 우아하고 실용적인 방법으로 풀어냈습니다. 솔직히 논문을 읽으면서 “아, 구조를 이렇게 뺄 수도 있구나” 하고 감탄했습니다.
💡 한 마디로? 로봇이 마주할 ‘미래의 시각적 결과’를 가벼운 ‘조건(Condition)’으로 압축해, 정밀한 행동 생성을 유도하는 새로운 2단계 학습 프레임워크입니다.
🤔 1. 그래서 WoG가 대체 뭔데요?
골프 칠 때를 생각해 볼까요? 초보자는 당장 눈앞의 공(현재 상태)을 보고 클럽을 휘두릅니다(행동). 반면, 프로는 공이 날아가서 홀컵에 떨어지는 궤적(미래 상태)을 머릿속으로 시뮬레이션한 뒤 그 ‘감각(Condition)’을 바탕으로 스윙하죠.
WoG는 VLA 모델에게 바로 이 ‘프로의 감각’을 가르칩니다.
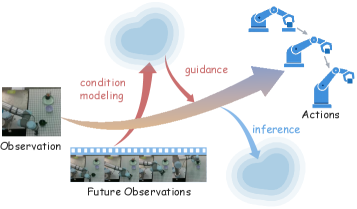 설마 미래를 전부 픽셀 단위로 상상하려는 건가? 싶었는데, 그걸 ‘조건 공간(Condition Space)’으로 압축해버린 아이디어가 돋보입니다.
설마 미래를 전부 픽셀 단위로 상상하려는 건가? 싶었는데, 그걸 ‘조건 공간(Condition Space)’으로 압축해버린 아이디어가 돋보입니다.
기존에도 미래를 예측하려는 시도는 있었습니다. 하지만 대부분 무거운 비디오 생성(Video Generation) 모델을 붙여 픽셀 단위로 미래를 그리려고 했죠. 연산량은 폭발하고, 노이즈도 심해서 실시간 제어에는 무리가 있었습니다.
WoG의 접근법은 다릅니다. 🔹 미래를 압축한다: 미래의 이미지 특징을 고차원 픽셀이 아니라, 작고 단단한 잠재 공간(Latent Condition Space)으로 압축합니다. 🔹 행동과 함께 예측한다: 모델이 다음 행동을 내뱉을 때, 이 ‘압축된 미래 조건’도 같이 예측하도록 학습시킵니다. 🔹 인간의 비디오로 배운다: 로봇 데이터가 부족해도, 인간의 조작 비디오(UMI 데이터 등)에서 미래 조건에 대한 감을 잡아버립니다.
🆚 2. 핵심 기능 및 비교 (이게 왜 실무에서 중요한가?)
연구실 장난감 수준을 넘어 현업에 적용하려면 비용(Cost)과 속도(Speed)가 핵심입니다. WoG가 기존 방식들과 어떻게 다른지 비교해 볼까요?
| 비교 항목 | 기존 Standard VLA | 픽셀 기반 미래 예측 (Video-based) | 🌟 WoG (World Guidance, 본 논문) |
|---|---|---|---|
| 동작 방식 | 현재 상태 ➡️ 행동 | 현재 상태 ➡️ 미래 픽셀 예측 ➡️ 행동 | 현재 상태 ➡️ 미래 조건 압축/예측 ➡️ 행동 |
| 정밀 조작 능력 | 낮음 (디테일 부족) | 중간 (노이즈로 인한 오차 발생) | 매우 높음 (Fine-grained 정보 보존) |
| 연산 효율 (Inference) | 매우 빠름 | 매우 느림 (실시간 제어 불가) | 빠름 (VLM 내부에서 처리) |
| OOD 일반화 능력 | 낮음 | 중간 | 우수함 |
특히 데이터 활용성 측면에서 엄청난 강점을 보입니다.
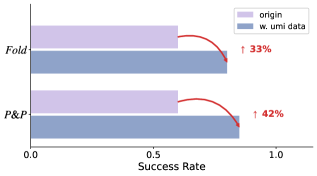 UMI(Universal Manipulation Interface) 데이터, 즉 인간의 조작 비디오를 섞어 썼더니 Pick&Place는 42%, Fold 태스크는 33%나 성능이 뛴 건 실무진 입장에선 환호할 만한 결과네요.
UMI(Universal Manipulation Interface) 데이터, 즉 인간의 조작 비디오를 섞어 썼더니 Pick&Place는 42%, Fold 태스크는 33%나 성능이 뛴 건 실무진 입장에선 환호할 만한 결과네요.
로봇 팔로 직접 텔레오퍼레이션(Teleoperation) 데이터를 모으는 건 피가 마르는 작업입니다. 하지만 WoG는 단순히 사람의 조작 비디오를 던져주면, 거기서 ‘미래의 조건’을 추출해 모델을 똑똑하게 만듭니다. 데이터 수집의 병목을 크게 줄여줄 수 있다는 뜻이죠.
🛠️ 3. 기술 딥다이브 (어떻게 돌아가는 건데?)
아키텍처를 뜯어보면 저자들이 꽤나 고민한 흔적이 보입니다. 전체 학습은 2단계(2-stage)로 나뉩니다.
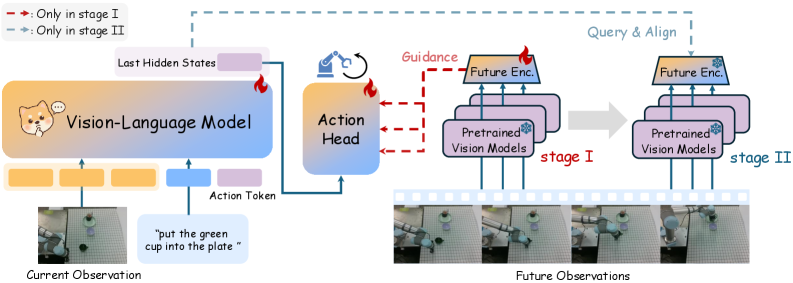 2-Stage 구조가 학습 파이프라인을 복잡하게 만들긴 하지만, VLM의 부담을 덜어주기 위한 훌륭한 타협점이라고 생각합니다.
2-Stage 구조가 학습 파이프라인을 복잡하게 만들긴 하지만, VLM의 부담을 덜어주기 위한 훌륭한 타협점이라고 생각합니다.
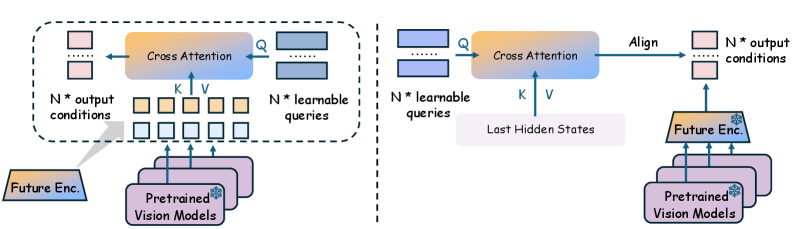 이 논문의 백미인 Q-former 기반의 쿼리 메커니즘. Cross-attention을 통해 모델이 무거운 비전 태스크에 매몰되지 않고 핵심 ‘액션 조건’만 쏙쏙 뽑아냅니다.
이 논문의 백미인 Q-former 기반의 쿼리 메커니즘. Cross-attention을 통해 모델이 무거운 비전 태스크에 매몰되지 않고 핵심 ‘액션 조건’만 쏙쏙 뽑아냅니다.
- Stage 1 (Condition Space 형성과 행동 학습): Q-former 기반의
Future Encoder가 미래 이미지를 압축하여 조건 표현(Condition Representation)을 만듭니다. 모델은 현재 이미지, 텍스트 명령어, 그리고 이 ‘미래 조건’을 모두 보고 정답 행동을 학습합니다. - Stage 2 (VLM 내부로의 지식 증류): 이제 미래를 미리 볼 수 없으니(추론 환경), 비전 인코더를 얼려버립니다. 대신 VLM 백본이 다음 행동을 예측하면서 동시에 Stage 1에서 만들었던 ‘미래 조건’까지 스스로 예측하도록 학습합니다.
실제 코드로 구현한다면 손실 함수(Loss) 계산부는 대략 이런 느낌일 겁니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# Stage 2: Pseudo-code for WoG Loss Calculation
def forward(current_obs, instruction, target_actions, future_obs_features):
# 1. 얼어있는 Future Encoder로 '정답' 미래 조건 추출
with torch.no_grad():
target_conditions = future_encoder.compress(future_obs_features)
# 2. VLM을 통해 행동 예측 및 '미래 조건' 예측
vlm_outputs = vlm_backbone(current_obs, instruction)
predicted_actions = vlm_outputs.actions
predicted_conditions = vlm_outputs.condition_queries # Cross-attention 적용된 예측값
# 3. 행동 손실 + 조건 예측 손실 (MSE 등)
action_loss = compute_action_loss(predicted_actions, target_actions)
condition_loss = F.mse_loss(predicted_conditions, target_conditions)
# Total Loss (Weighting applied)
total_loss = action_loss + alpha * condition_loss
return total_loss
🔥 에디터의 생각 (Editor’s Verdict)
 실제 로봇 환경 테스트 결과가 인상적입니다. 특히 조명이 바뀌거나 장애물이 추가된 OOD(Out-of-Distribution) 환경에서의 방어력이 놀랍네요.
실제 로봇 환경 테스트 결과가 인상적입니다. 특히 조명이 바뀌거나 장애물이 추가된 OOD(Out-of-Distribution) 환경에서의 방어력이 놀랍네요.
로봇 공학과 AI가 만나는 지점에서, 우리는 늘 “표현력(Representation)과 효율성(Efficiency) 사이의 줄다리기”를 합니다. WoG는 그 균형을 정말 잘 잡은 논문입니다.
✅ 장점 (Pros):
- 미래를 픽셀 단위로 그리는 바보 같은 짓을 멈추고, 잠재 공간(Condition Space)에서 해결한 것은 신의 한 수입니다.
- 인간의 조작 비디오(Human manipulation video)를 통해 사전 학습을 쉽게 부스팅할 수 있다는 점은 실무적으로 엄청난 매력입니다.
- OOD(Out-of-Distribution) 환경에서의 강건함(Generalization)이 훌륭합니다.
⚠️ 아쉬운 점 / 한계 (Cons):
- 2-stage 학습 방식은 파이프라인 관리 측면에서 엔지니어들에게 다소 부담을 줍니다. 하이퍼파라미터 튜닝이 꽤나 까다로울 것 같네요.
- 실제 100Hz 이상의 고속 제어가 필요한 태스크에서 VLM 백본의 추론 속도(Latency)가 얼마나 방어될지에 대한 구체적인 프로파일링이 더 있으면 좋겠습니다.
🎯 최종 평가: “단순히 행동만 베끼는 Behavior Cloning을 넘어, 로봇에게 ‘목적지’를 상상하게 만드는 훌륭한 접근. 로보틱스 엔지니어나 VLA 연구자라면 이번 주말 시간을 내서라도 반드시 읽어보셔야 할 논문입니다.”
