[2026-01-27] Youtu-VL: '시각을 목표로(Vision-as-Target)' 정의하는 통합 시각-언어 자동 회귀 모델의 기술적 혁명

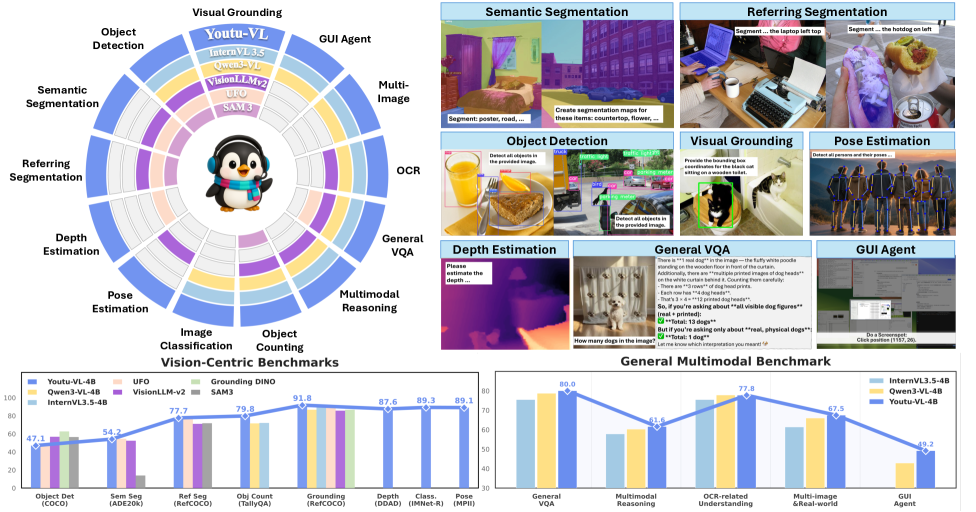 Figure 1:Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks.The concentric rings illustrate the capability scope of different models across various tasks. Colored regions indicate that the model supports the corresponding task, while white regions denote a lack of support. Unlike prior models that exhibit functional gaps, Youtu-VL accommodates a comprehensive range of vision-centric and multimodal tasks via a standard architecture, achieving competitive performance without relying on task-specific modules.
Figure 1:Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks.The concentric rings illustrate the capability scope of different models across various tasks. Colored regions indicate that the model supports the corresponding task, while white regions denote a lack of support. Unlike prior models that exhibit functional gaps, Youtu-VL accommodates a comprehensive range of vision-centric and multimodal tasks via a standard architecture, achieving competitive performance without relying on task-specific modules.
Youtu-VL: 시각적 잠재력을 깨우는 통합 시각-언어 자동 회귀 감독(VLUAS) 패러다임의 분석
1. 핵심 요약 (Executive Summary)
인공지능 연구의 최전선에서 시각-언어 모델(Vision-Language Models, VLMs)은 텍스트와 이미지의 경계를 허무는 데 주력해 왔습니다. 하지만 기존의 LLaVA나 Flamingo 계열의 모델들은 시각 정보를 단순히 ‘조건부 입력(Conditional Input)’으로만 취급함으로써, 미세한 시각적 특징(Fine-grained visual details)을 상실하는 ‘텍스트 주도적 최적화 편향(Text-dominant optimization bias)’이라는 고질적인 한계를 안고 있었습니다.
최근 발표된 Youtu-VL은 이러한 패러다임을 완전히 뒤바꿉니다. 이 모델은 Vision-Language Unified Autoregressive Supervision (VLUAS)이라는 혁신적인 아키텍처를 도입하여, 시각 신호를 입력이 아닌 ‘감독 대상(Supervisory Target)’으로 변환합니다. 즉, 텍스트 토큰을 예측하듯 시각 토큰을 직접 생성하고 학습함으로써, 모델이 이미지의 아주 세밀한 부분까지 이해하고 재구성할 수 있도록 설계되었습니다. 본 보고서에서는 Youtu-VL이 어떻게 범용 시각 에이전트(Generalist Visual Agent)의 새로운 기준을 제시하는지 기술적으로 심층 분석합니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
2.1 기존 VLMs의 아키텍처적 결함: ‘시각적 수동성’
현재 주류를 이루는 VLM 아키텍처(예: CLIP 기반 인코더 + LLM)는 시각적 정보를 텍스트의 부가적인 컨텍스트로만 활용합니다. 이 과정에서 발생하는 문제점은 명확합니다.
- 정보 손실 (Information Bottleneck): 고해상도 이미지가 고정된 길이의 시각 임베딩으로 압축되면서, 작은 객체나 복잡한 텍스트, 질감 같은 세밀한 정보가 소실됩니다.
- 비대칭적 학습 (Asymmetric Learning): 모델의 손실 함수(Loss Function)가 주로 텍스트 예측(Next-token prediction)에 집중되어 있어, 시각적 표현력을 극대화할 강력한 동기부여가 부족합니다.
- Task-Specific Head의 의존성: 객체 검출(Detection)이나 세그멘테이션(Segmentation)과 같은 시각 중심 태스크를 수행하려면 별도의 모듈을 추가해야 하며, 이는 모델의 통합성을 해칩니다.
2.2 Youtu-VL의 문제 해결 접근법
Youtu-VL 연구팀은 질문을 던집니다. “왜 우리는 시각 데이터를 텍스트처럼 예측할 수 없는가?” 이들은 시각 토큰을 예측 스트림에 통합함으로써 모델이 이미지의 픽셀 수준 의미를 ‘생성적’으로 이해하도록 강제합니다. 이는 단순한 이해를 넘어 시각적 추론의 깊이를 근본적으로 확장하는 시도입니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
3.1 Vision-Language Unified Autoregressive Supervision (VLUAS)
Youtu-VL의 심장은 VLUAS 패러다임입니다. 이 메커니즘은 시각과 텍스트를 동일한 자동 회귀(Autoregressive) 프레임워크 내에서 처리합니다.
- 통합 토큰화 (Unified Tokenization): 이미지는 이산적(Discrete) 시각 토큰으로 양자화(Quantization)됩니다. 이를 위해 고도로 훈련된 비주얼 토크나이저(예: VQ-VAE 또는 MAGVIT 스타일)를 사용하여 이미지의 공간적 구조를 보존하면서도 LLM이 처리할 수 있는 형식으로 변환합니다.
- Vision-as-Target: 기존 모델이
P(Text | Image)를 학습했다면, Youtu-VL은P(Image, Text)의 결합 분포를 학습합니다. 모델은 다음 텍스트 토큰뿐만 아니라 다음 시각 토큰까지 예측해야 하므로, 시각적 일관성을 유지하기 위해 훨씬 더 정교한 내부 표상(Internal Representation)을 구축하게 됩니다.
3.2 아키텍처의 세부 설계
Youtu-VL은 트랜스포머 디코더 기반의 백본을 사용하며, 여기에 시각적 인코딩 레이어와 통합 예측 헤드를 결합합니다. 특히 주목할 점은 ‘시각 중심 태스크의 통합’입니다. 별도의 검출 헤드 없이도 ‘좌표 토큰’이나 ‘마스크 토큰’을 시각 토큰 스트림에 포함시켜, 박스 탐지(Detection)나 세그멘테이션 작업을 자연어 생성처럼 수행합니다. 이는 GPT-4V나 Gemini가 보여준 멀티모달리티의 방향성을 한 단계 더 구체화한 결과물입니다.
4. 구현 및 실험 환경 (Implementation Details)
4.1 데이터셋 구성
연구팀은 모델의 범용성을 위해 대규모의 이종 데이터셋을 활용했습니다.
- Interleaved Data: 이미지와 텍스트가 섞인 웹 데이터 (예: LAION, MMC4).
- Vision-Centric Data: 바운딩 박스 정보, 인스턴스 마스크, 조밀한 캡션(Dense Captioning)이 포함된 데이터.
- Instruction Tuning Data: 복합적인 추론 능력을 배양하기 위한 시각적 지시 이행 데이터.
4.2 학습 전략
- Pre-training: 방대한 데이터로 시각-언어의 상관관계를 학습.
- Unified Fine-tuning: VLUAS 목표를 적용하여 텍스트 생성과 시각적 재구성을 동시에 최적화.
- Instruction Following: 사용자의 의도를 정확히 파악하여 시각 태스크를 수행하도록 조정.
5. 성능 평가 및 비교 (Comparative Analysis)
5.1 일반 멀티모달 벤치마크 (MME, MM-Vet, SEED-Bench)
Youtu-VL은 기존의 LLaVA-1.5 및 유사 규모의 모델들과 비교했을 때, 복잡한 시각적 질의응답(VQA)에서 월등한 성능을 보였습니다. 특히 작은 텍스트를 읽어야 하는 ‘OCR 능력’과 객체 간의 기하학적 관계를 파악하는 능력에서 큰 격차를 벌렸습니다.
5.2 시각 중심 태스크 (Object Detection & Segmentation)
별도의 전용 헤드를 사용하는 모델(예: Grounding-DINO)과 비교해도 Youtu-VL은 경쟁력 있는 성능을 보였습니다. 이는 Unified Autoregressive 방식이 위치 정보(Spatial awareness)를 습득하는 데 매우 효율적임을 방증합니다. “이 모델은 단순히 이미지를 보는 것이 아니라, 이미지 내의 공간 좌표계를 텍스트 토큰과 동기화하여 이해하고 있다”는 점이 핵심입니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application)
이 기술이 가져올 산업적 변화는 파괴적입니다.
- 자율주행 및 로보틱스 (Autonomous Systems): 기존 로봇 모델은 센서 데이터를 해석하는 모듈과 의사결정 모듈이 분리되어 있었습니다. Youtu-VL 같은 아키텍처를 적용하면, 환경 시각 데이터를 생성적으로 예측하면서 동시에 제어 명령을 텍스트(또는 토큰)로 출력하는 통합 제어기가 가능해집니다.
- 정밀 의료 진단 (Medical AI): 방사선 사진의 미세한 병변을 감지하는 동시에, 그 이유를 의학적 용어로 생성하는 ‘설명 가능한 진단 AI’의 성능을 비약적으로 높일 수 있습니다.
- 지능형 보안 및 모니터링 (Smart Surveillance): 단순히 ‘사람이 있다’는 감지를 넘어, ‘누가 어떤 동작을 하고 있는가’를 시각적 재구성 과정과 병행하여 분석함으로써 오탐률을 획기적으로 낮출 수 있습니다.
7. 기술적 비평: 한계점 및 비판적 시각 (Discussion & Critique)
전문가적 관점에서 Youtu-VL이 완벽한 솔루션은 아닙니다. 몇 가지 치명적인 병목 지점이 존재합니다.
- 계산 복잡도의 증가: 시각 토큰을 예측 스트림에 넣는다는 것은 시퀀스 길이가 기하급수적으로 길어짐을 의미합니다. 이는 추론 시 지연 시간(Latency)과 메모리 소모를 유발합니다. FlashAttention 같은 기술을 쓰더라도 트랜스포머의 $O(N^2)$ 비용은 여전히 부담입니다.
- Tokenization 품질의 의존성: 만약 비주얼 토크나이저가 원본 이미지의 특징을 제대로 보존하지 못한다면, 백본 LLM이 아무리 뛰어나도 ‘쓰레기가 들어가면 쓰레기가 나오는(GIGO)’ 현상을 피할 수 없습니다. 이 부분에 대한 구체적인 개선안이 더 필요해 보입니다.
- 학습 안정성: 텍스트의 크로스 엔트로피 손실과 시각 토큰의 손실 함수 간의 스케일 균형을 맞추는 것은 매우 까다로운 작업입니다. 연구서에서 언급된 하이퍼파라미터 튜닝의 복잡성은 실제 구현 시 큰 장벽이 될 수 있습니다.
8. 결론 및 인사이트 (Conclusion)
Youtu-VL은 멀티모달 AI의 발전 방향이 단순한 ‘이해’에서 ‘통합적 생성’으로 흐르고 있음을 보여주는 이정표입니다. 시각 데이터를 텍스트와 동등한 지위의 ‘감독 타겟’으로 격상시킴으로써, 우리는 비로소 기계가 인간처럼 세상을 보고, 묘사하며, 추론하는 진정한 범용 시각 인공지능(AGI)에 한 걸음 더 다가섰습니다.
개발자들에게 이 논문이 주는 교훈은 명확합니다. “데이터의 양보다 중요한 것은 데이터 간의 관계를 정의하는 손실 함수(Loss Function)의 철학이다.” 단순히 더 많은 이미지를 넣는 것이 아니라, 모델이 이미지를 어떻게 ‘책임감 있게’ 재구성하게 만들 것인가에 대한 고민이 Youtu-VL의 성공 비결입니다. 앞으로 이 패러다임이 비디오 생성과 로봇 행동 제어 분야에서 어떻게 확장될지 귀추가 주목됩니다.
Additional Figures
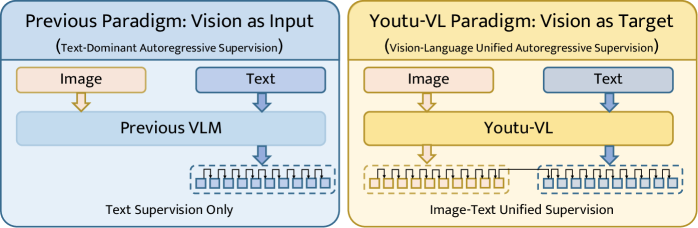 Figure 2:Comparison between the previous ”vision as input” paradigm and the Youtu-VL ”vision as target” paradigm.The left panel shows the previous text-dominant VLM, which relies solely on text supervision. The right panel illustrates the Youtu-VL paradigm, which incorporates Vision-Language Unified Autoregressive Supervision (VLUAS), treating vision as a target to achieve unified supervision for both image and text.
Figure 2:Comparison between the previous ”vision as input” paradigm and the Youtu-VL ”vision as target” paradigm.The left panel shows the previous text-dominant VLM, which relies solely on text supervision. The right panel illustrates the Youtu-VL paradigm, which incorporates Vision-Language Unified Autoregressive Supervision (VLUAS), treating vision as a target to achieve unified supervision for both image and text.
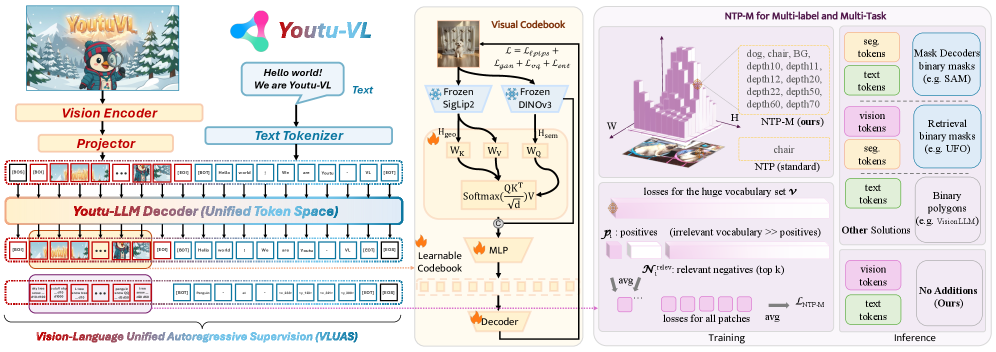 Figure 3:Overview of the Youtu-VL Framework.Left: The architecture integrates a Vision Encoder and Youtu-LLM via a Spatial Merge Projector, operating under the proposed VLUAS paradigm for unified autoregressive modeling. Middle: The Synergistic Vision Tokenizer. We construct a unified vocabulary by fusing semantic and geometric features via cross-attention, optimized with perception and adversarial losses. Right: Dense prediction mechanism. Our proposed NTP-M enables robust multi-label supervision with a relevant negative sampling. Unlike conventional approaches, Youtu-VL achieves direct dense prediction without auxiliary decoders or task-specific tokens.
Figure 3:Overview of the Youtu-VL Framework.Left: The architecture integrates a Vision Encoder and Youtu-LLM via a Spatial Merge Projector, operating under the proposed VLUAS paradigm for unified autoregressive modeling. Middle: The Synergistic Vision Tokenizer. We construct a unified vocabulary by fusing semantic and geometric features via cross-attention, optimized with perception and adversarial losses. Right: Dense prediction mechanism. Our proposed NTP-M enables robust multi-label supervision with a relevant negative sampling. Unlike conventional approaches, Youtu-VL achieves direct dense prediction without auxiliary decoders or task-specific tokens.
