[2026-02-11] DeepImageSearch: 이미지 검색의 패러다임 시프트, 에이전틱 추론과 시각적 맥락의 결합

DeepImageSearch: 이미지 검색의 패러다임 시프트, 에이전틱 추론과 시각적 맥락의 결합
1. 핵심 요약 (Executive Summary)
전통적인 이미지 검색 시스템은 텍스트 쿼리와 이미지 간의 개별적인 ‘시각적 유사도(Semantic Matching)’에만 집중해 왔습니다. 하지만 우리가 일상에서 마주하는 시각적 정보는 단편적인 스냅샷이 아니라, 시간과 공간이 얽힌 시각적 이력(Visual Histories)의 형태를 띱니다. 본 보고서에서 분석할 DeepImageSearch는 이러한 한계를 돌파하기 위해 제안된 혁신적인 에이전틱(Agentic) 검색 패러다임입니다.
DeepImageSearch는 이미지 검색을 단순한 매칭 작업에서 ‘자율적 탐색 및 다단계 추론’ 작업으로 재정의합니다. 이를 위해 연구진은 새로운 벤치마크인 DISBench를 구축하고, 시각적 맥락(Context)을 이해하고 탐색할 수 있는 모듈형 에이전트 프레임워크를 제시했습니다. 본 분석을 통해 이미지 검색 기술이 ‘무엇(What)’을 찾는 단계에서 ‘어떻게 그리고 왜(How & Why)’를 추론하는 단계로 어떻게 진화하고 있는지 심층적으로 분석합니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
기존 패러다임의 한계: 고립된 이미지 검색
지금까지의 이미지 검색(Image Retrieval)은 CLIP(Contrastive Language-Image Pre-training)과 같은 모델을 기반으로 한 벡터 검색이 주류를 이루었습니다. 사용자가 “빨간색 코트를 입은 여자”라고 검색하면, 모델은 데이터베이스의 각 이미지를 독립적으로 평가하여 가장 유사한 이미지를 반환합니다.
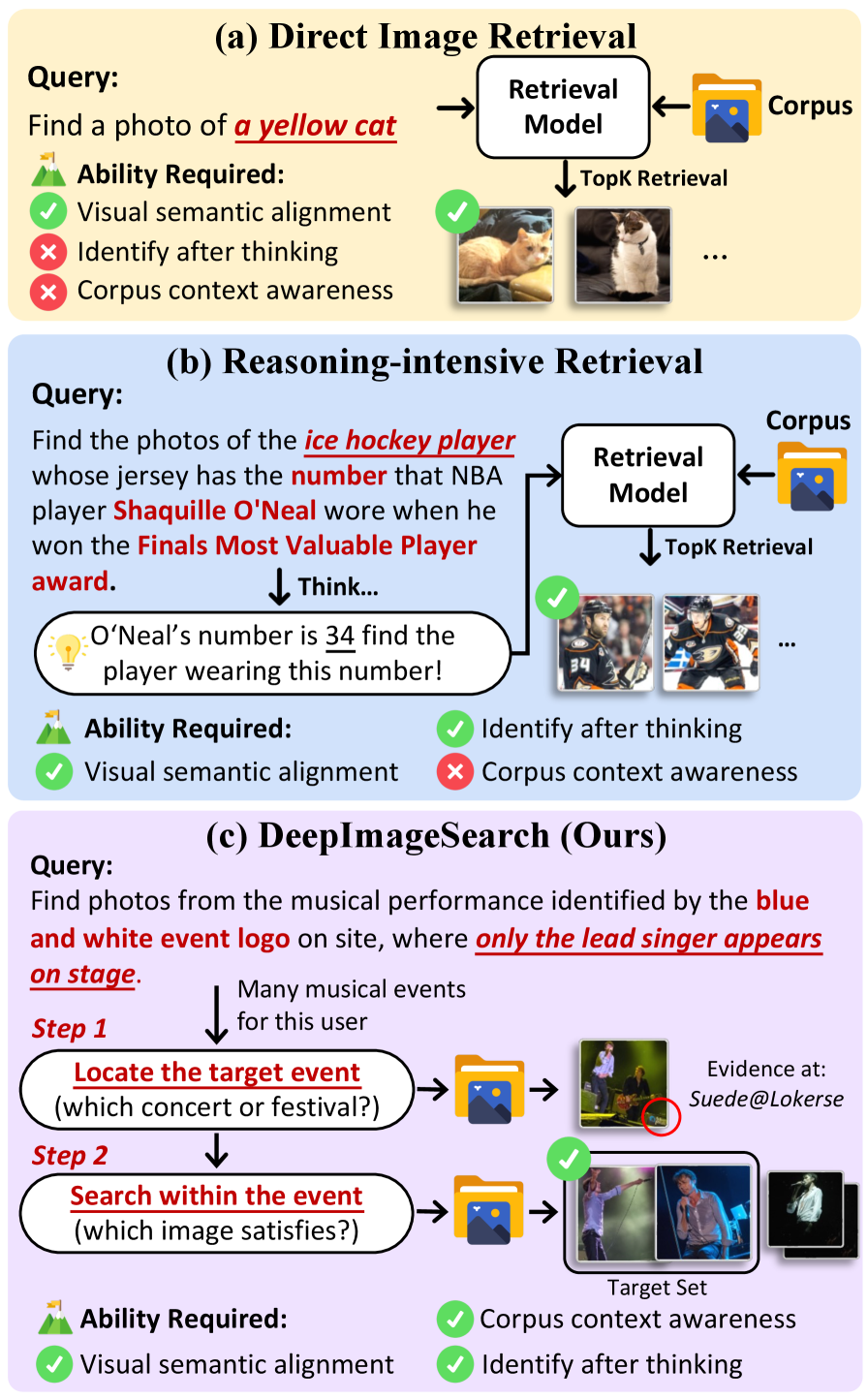 Figure 1: 이미지 검색 패러다임의 진화. (a) 직접 검색 (b) 지식 기반 추론 검색 (c) DeepImageSearch (맥락 인식 검색)
Figure 1: 이미지 검색 패러다임의 진화. (a) 직접 검색 (b) 지식 기반 추론 검색 (c) DeepImageSearch (맥락 인식 검색)
하지만 위 그림에서 볼 수 있듯이, 현실 세계의 검색 요구는 훨씬 더 복잡합니다. 예를 들어, “오늘 아침 회의에서 발표했던 사람이 오후에 커피숍에서 누구와 있었는지 찾아줘”라는 쿼리는 단일 이미지에 대한 묘사가 아니라, 연속된 시각적 흐름 속에서 특정 이벤트를 먼저 식별하고 그 전후 맥락을 추론해야만 해결할 수 있는 문제입니다. 기존 시스템은 각 이미지를 독립적으로 처리하기 때문에 이러한 ‘맥락적 의존성(Contextual Dependency)’을 포착하는 데 근본적인 한계를 지닙니다.
DeepImageSearch의 핵심 질문
본 연구는 다음과 같은 질문에서 시작됩니다.
“모델이 단순한 시각적 특징 매칭을 넘어, 방대한 시각적 이력 데이터 속에서 능동적으로 정보를 탐색하고 다단계 추론을 수행할 수 있는가?”
이를 해결하기 위해 연구진은 이미지 검색을 에이전트가 수행하는 자율 탐색 작업으로 전환하였습니다. 이는 단순히 DB를 스캔하는 것이 아니라, 에이전트가 툴을 사용해 정보를 수집하고, 가설을 세우며, 이력을 거슬러 올라가며 정답을 찾아가는 과정을 의미합니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
3.1 DISBench: 시각적 맥락 인식을 위한 새로운 벤치마크
연구진은 에이전트의 능력을 평가하기 위해 DISBench를 구축했습니다. 이 데이터셋은 단순히 많은 이미지를 모은 것이 아니라, 이미지 간의 시간적/공간적 관계를 정교하게 설계했습니다.
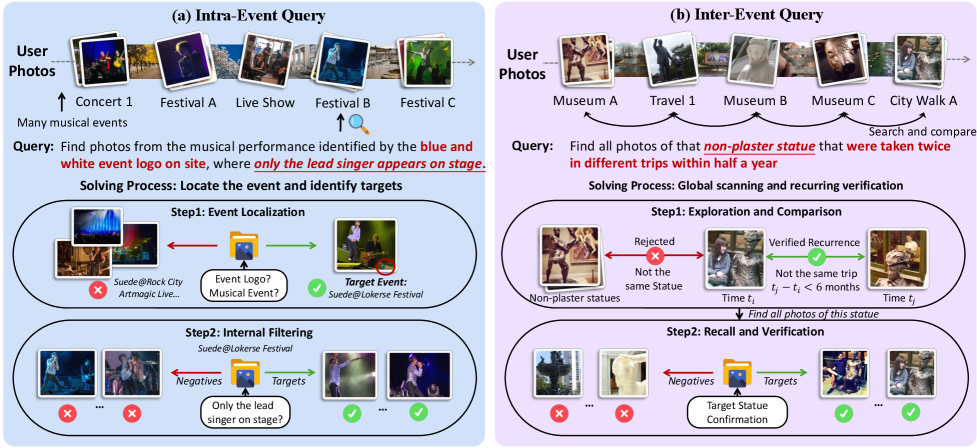 Figure 2: DISBench의 두 가지 쿼리 유형. (a) 이벤트 내(Intra-Event) 쿼리 (b) 이벤트 간(Inter-Event) 쿼리
Figure 2: DISBench의 두 가지 쿼리 유형. (a) 이벤트 내(Intra-Event) 쿼리 (b) 이벤트 간(Inter-Event) 쿼리
DISBench는 크게 두 종류의 도전적인 쿼리를 포함합니다:
- Intra-Event Queries: 특정 이벤트 내에서 세부적인 필터링을 요구합니다. (예: “공원에서 요가하던 사람들 중 파란 매트를 쓴 사람을 찾아줘”)
- Inter-Event Queries: 여러 이벤트에 걸쳐 반복되는 요소나 시공간적 제약을 확인해야 합니다. (예: “오전에 마트에서 본 남자가 저녁에 식당에서도 나타났는지 확인하고 해당 장면을 찾아줘”)
3.2 데이터 구축 파이프라인: 인간-모델 협업 (VLM-Assisted Pipeline)
맥락 의존적인 쿼리를 대규모로 생성하는 것은 매우 어려운 작업입니다. 연구진은 이를 위해 메모리 그래프(Memory Graph) 기반의 자동화 파이프라인을 제안했습니다.
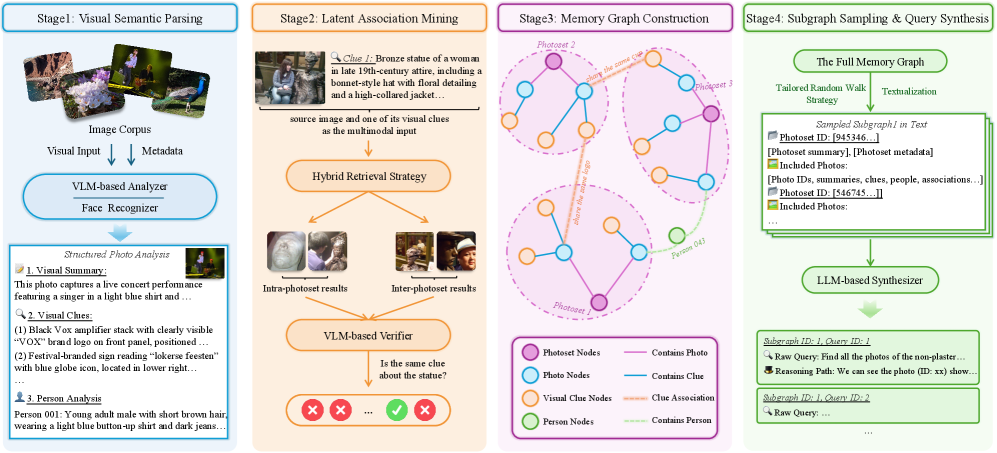 Figure 3: 반자동 데이터 구축 파이프라인. 시각적 속성 추출부터 메모리 그래프 구축, 그리고 인간의 검증까지의 과정.
Figure 3: 반자동 데이터 구축 파이프라인. 시각적 속성 추출부터 메모리 그래프 구축, 그리고 인간의 검증까지의 과정.
- 시각적 속성 추출: VLM을 사용하여 이미지 내 객체의 속성, 행위, 인물 특징을 정교하게 캡셔닝합니다.
- 메모리 그래프 구성: 추출된 정보를 바탕으로 인물이나 장소의 연관 관계를 그래프 형태로 조직화합니다.
- 랜덤 워크(Random Walk) 및 쿼리 생성: 그래프 상에서 경로를 탐색하며 복잡한 맥락을 포함하는 쿼리 초안을 생성합니다.
- 인간 검증: 생성된 쿼리가 논리적으로 타당한지 사람이 최종 확인하여 데이터의 품질을 보장합니다.
3.3 모듈형 에이전트 프레임워크 (Modular Agent Framework)
DeepImageSearch의 핵심은 에이전트가 어떻게 행동하느냐에 있습니다. 연구진은 다음 세 가지 핵심 요소를 갖춘 에이전트를 구축했습니다.
- Fine-grained Tools: 검색(Search), 필터링(Filter), 검증(Verify) 등 세분화된 도구를 사용하여 거대한 이미지 뭉치 속에서 정보를 좁혀 나갑니다.
- Dual-Memory System: 현재 작업 중인 정보를 담는 ‘작업 메모리’와 전체 시각적 이력을 참조하는 ‘장기 메모리’를 구분하여 긴 시계열 데이터 처리를 가능케 합니다.
- Multi-step Reasoning: 한 번의 검색으로 끝내지 않고, 첫 번째 검색 결과에서 얻은 단서를 바탕으로 다음 검색 계획을 수립합니다.
4. 구현 및 실험 환경 (Implementation Details & Experiment Setup)
데이터셋 통계
DISBench는 실제 세계를 모사한 다양한 테마의 이미지를 포함하고 있습니다.
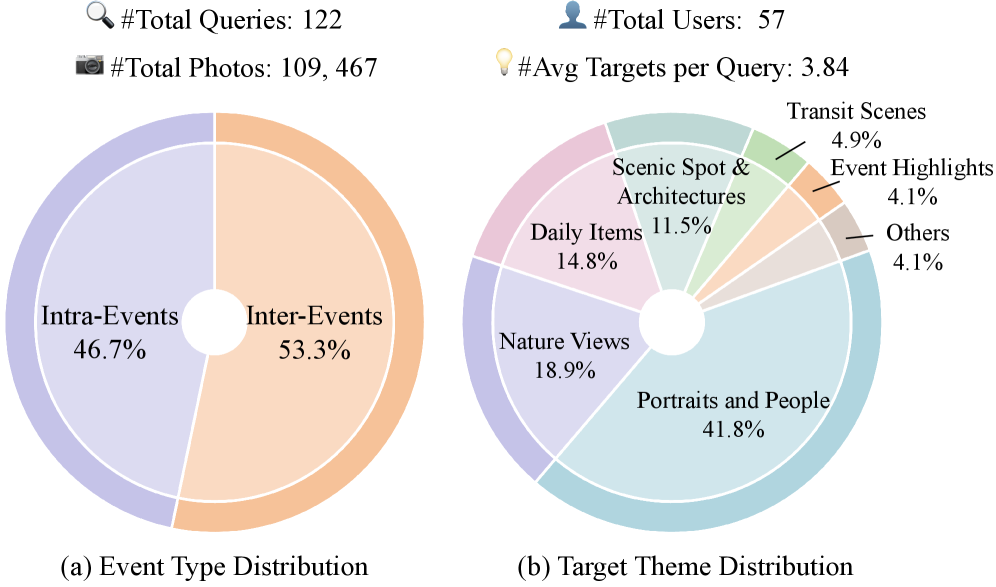 Figure 4: DISBench 데이터셋 통계. 쿼리 유형과 타겟 이미지 테마의 분포.
Figure 4: DISBench 데이터셋 통계. 쿼리 유형과 타겟 이미지 테마의 분포.
실험은 GPT-4o, Gemini-1.5-Pro, 그리고 LLaVA 계열의 오픈 소스 모델들을 대상으로 진행되었습니다. 에이전트 프레임워크는 ReAct(Reasoning and Acting) 스타일의 프롬프팅을 사용하였으며, 에이전트가 사용할 수 있는 도구(Tool)로는 텍스트 기반 검색 엔진과 속성 필터링 엔진을 제공했습니다.
특히 주목할 점은 ‘Test-time Scaling’ 전략입니다. 에이전트가 더 많은 추론 단계를 거치거나 여러 경로를 탐색할 때 성능이 어떻게 변하는지 분석하기 위해 Best-of-N 샘플링과 Beam Search 기법이 적용되었습니다.
5. 성능 평가 및 비교 (Comparative Analysis)
실험 결과는 충격적이었습니다. 현존하는 최강의 멀티모달 모델인 GPT-4o조차도 DISBench의 복잡한 맥락 쿼리 앞에서는 성능 저하를 보였습니다.
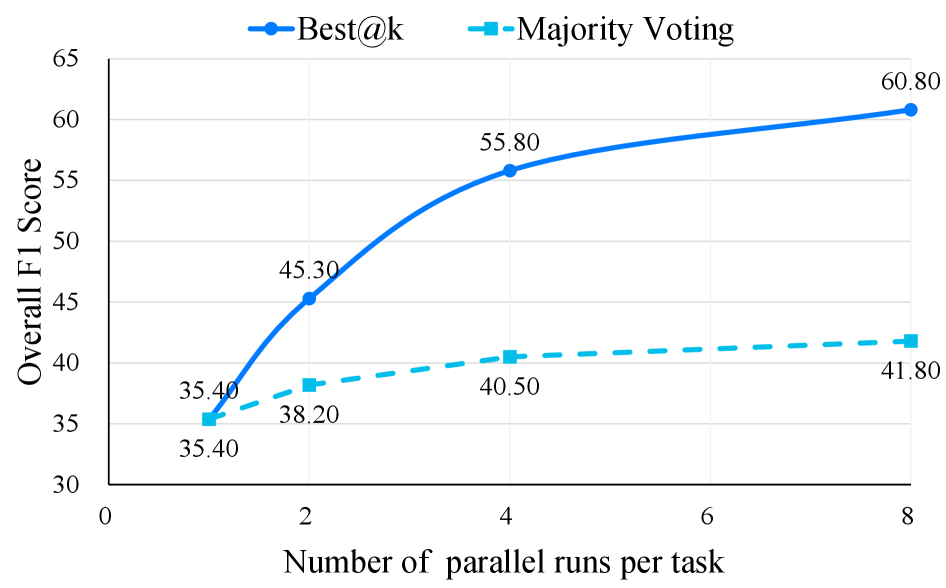 Figure 5: 테스트 시간 스케일링(Test-time Scaling) 전략에 따른 성능 변화.
Figure 5: 테스트 시간 스케일링(Test-time Scaling) 전략에 따른 성능 변화.
주요 분석 결과는 다음과 같습니다:
- 에이전틱 접근의 우위: 단순한 Single-turn 검색 모델보다 여러 번의 추론과 도구 사용을 거치는 에이전트 방식이 압도적으로 높은 성공률을 기록했습니다.
- 추론 비용과 성능의 트레이드오프: 그림 5에서 보듯, 더 많은 추론 단계를 거칠수록(Scaling up) 성능은 향상되지만 일정 수준 이후에는 수렴하는 경향을 보입니다. 이는 무작정 추론 횟수를 늘리는 것보다 ‘효율적인 탐색 경로’를 찾는 것이 중요함을 시사합니다.
- 오픈 소스 모델의 한계: 폐쇄형 모델(GPT-4o)에 비해 오픈 소스 LMM들은 복잡한 도구 호출 및 상태 유지 능력에서 큰 격차를 보였습니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
이 연구는 단순한 벤치마크 공개를 넘어, 산업계에 엄청난 파급력을 미칠 것으로 예상됩니다.
1) 지능형 CCTV 및 보안 시스템 (Smart Surveillance)
현재의 보안 시스템은 단순히 ‘사람’이나 ‘차량’을 감지하는 수준입니다. DeepImageSearch 기술을 적용하면, “빨간 가방을 든 남자가 건물에 들어온 뒤 어디로 이동했는지 추적해줘”와 같은 복잡한 보안 쿼리를 실시간으로 해결할 수 있습니다. 이는 실종자 수색이나 범죄 예방에 혁신적인 도구가 될 것입니다.
2) 개인용 디지털 비서 (Personal AI Lifelogging)
우리의 스마트폰에는 수만 장의 사진이 저장되어 있습니다. 이제 “작년 제주도 여행 때 갔던 카페에서 먹었던 디저트 사진 찾아줘”라는 쿼리에 대해, AI는 단순히 ‘디저트’ 사진을 다 보여주는 것이 아니라, ‘제주도 여행’이라는 시각적 흐름을 먼저 파악하고 그 안에서 해당 카페 이벤트를 찾아 정확한 정답을 제시할 수 있게 됩니다.
3) 로보틱스 및 자율 주행 (Robotics & Autonomous Navigation)
가정용 서비스 로봇은 집안의 물건 위치 변화를 기억해야 합니다. “아까 거실에 있던 리모컨이 지금은 어디 있니?”라는 질문에 답하기 위해 로봇은 자신의 시각적 이력을 탐색하고 물건의 이동 궤적을 추론해야 합니다. 본 연구의 에이전틱 프레임워크는 로봇의 ‘시각적 기억 장치’를 구현하는 핵심 로직이 될 수 있습니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critical Critique)
본 연구가 매우 훌륭한 통찰을 제공하지만, Senior Chief AI Scientist의 시각에서 본 몇 가지 비판적 한계점은 다음과 같습니다.
- 계산 비용과 지연 시간(Latency): 에이전트가 다단계 추론을 수행하고 매번 VLM을 호출하는 방식은 실제 서비스에 적용하기에 너무 무겁습니다. 특히 수백만 장의 이미지 데이터베이스에서 실시간으로 ‘에이전틱 탐색’을 수행하는 것은 현재 하드웨어 구조상 큰 도전입니다.
- 도구 의존성(Tool Dependency): 성능이 모델의 추론 능력뿐만 아니라 제공된 ‘검색 도구’의 성능에 크게 의존합니다. 만약 초기 단계의 검색 도구가 중요한 단서를 놓친다면, 에이전트의 추론 능력이 아무리 뛰어나도 정답을 찾을 수 없는 ‘Error Propagation’ 문제가 발생합니다.
- 데이터의 인위성: DISBench는 구조화된 메모리 그래프에서 생성되었기 때문에, 실제 세계의 비구조적이고 노이즈가 많은 시각적 데이터 흐름(예: 매우 혼잡한 거리의 무작위 카메라 앵글)에서도 동일한 추론 성능이 나올지는 미지수입니다.
8. 결론 및 인사이트 (Conclusion)
DeepImageSearch는 이미지 검색의 정의를 ‘정적인 매칭’에서 ‘동적인 추론’으로 확장한 중대한 이정표입니다. 이제 AI 모델은 단일 이미지의 픽셀을 분석하는 것을 넘어, 시간의 흐름 속에서 인과 관계와 공간적 맥락을 연결하는 ‘시각적 서사(Visual Narrative)’를 이해해야 하는 숙제를 안게 되었습니다.
개발자들과 비즈니스 리더들은 이제 ‘단순 검색’ 솔루션에 머무르지 말고, 사용자의 복잡한 맥락을 이해하고 스스로 탐색하는 ‘검색 에이전트’ 도입을 진지하게 고려해야 할 때입니다. DeepImageSearch가 제시한 에이전틱 패러다임은 향후 멀티모달 AI가 인간의 조력자로서 한 단계 도약하는 데 핵심적인 역할을 할 것입니다.
전문가 의견: “결국 승부는 누가 더 똑똑한 에이전트를 만드느냐가 아니라, 누가 더 효율적으로 ‘장기 시각 메모리’를 압축하고 탐색하게 하느냐에 달려 있습니다. DeepImageSearch는 그 방향성을 정확히 짚어냈습니다.”
