[2026-02-12] 🎥 AI가 여러 사람의 목소리와 얼굴을 동시에 통제한다면? DreamID-Omni 완벽 분석

📖 논문: DreamID-Omni: Unified Framework for Controllable Human-Centric Audio-Video Generation 🖥️ 프로젝트/Github: 공식 코드 공개 예정
생성형 AI로 완벽한 홍보 영상이나 버추얼 휴먼(Virtual Human) 콘텐츠를 만들려다, 다중 인물의 얼굴이 바뀌거나 목소리가 섞이는 ‘환각(Hallucination)’ 현상을 겪어보신 적 있으신가요?
상용 AI 비디오 모델조차 여러 명의 화자가 등장할 때 누가 어떤 목소리를 내야 하는지(Speaker Confusion) 헷갈려 하는 경우가 빈번합니다. 하지만 오늘 리뷰할 DreamID-Omni는 이러한 한계를 완전히 부수며, 사람 중심의 오디오-비디오 생성(Human-Centric Audio-Video Generation)의 새로운 표준을 제시합니다.
💡 한 마디로? 비디오 생성(R2AV), 비디오 편집(RV2AV), 오디오 기반 애니메이션(RA2V)을 단일 Diffusion Transformer 모델로 통합하고, 다중 인물의 얼굴과 목소리를 완벽하게 분리 제어하는 차세대 올인원(All-in-One) A/V 생성 프레임워크입니다.
[1] 🎯 Executive Summary
바쁜 C-Level과 연구자 분들을 위한 핵심 요약입니다.
- 🚀 단일 프레임워크 통합: 기존에는 개별적으로 다루어지던 비디오 생성, 편집, 립싱크(RA2V) 파이프라인을 하나의 모델로 완벽히 통합했습니다.
- 🧠 Symmetric Conditional DiT: 시각적/청각적 조건 신호를 대칭적으로 주입하는 혁신적인 Diffusion Transformer 구조를 채택했습니다.
- 🔥 이중 레벨 분리 제어(Dual-Level Disentanglement): 다중 인물 환경에서 얼굴과 목소리가 꼬이는 문제를 해결하기 위해, 신호 레벨(Syn-RoPE)과 의미 레벨(Structured Captions)에서 제어력을 극대화했습니다.
- 📈 상용 모델 압도: SOTA(State-of-the-Art) 달성은 물론, 막대한 자본이 투입된 주요 상용 모델들의 성능을 능가하며 코드를 오픈소스로 공개할 예정입니다.
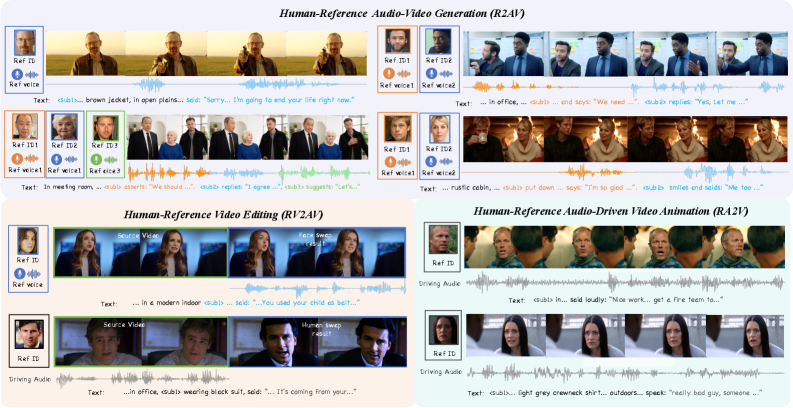 그림 1: DreamID-Omni 쇼케이스. 참조 기반 생성(R2AV), 비디오 편집(RV2AV), 오디오 기반 애니메이션(RA2V)을 단일 프레임워크에서 매끄럽게 처리합니다.
그림 1: DreamID-Omni 쇼케이스. 참조 기반 생성(R2AV), 비디오 편집(RV2AV), 오디오 기반 애니메이션(RA2V)을 단일 프레임워크에서 매끄럽게 처리합니다.
[2] 🤔 Research Background & Problem Statement
“왜 아직도 완벽한 다중 인물 AI 비디오는 어려울까요?”
최근 Foundation Model들이 크게 발전했지만, 기존의 접근 방식은 치명적인 비즈니스 및 기술적 한계를 안고 있었습니다.
| 📌 구분 | 기존 시스템의 한계 (Before) | DreamID-Omni (After) |
|---|---|---|
| 파이프라인 파편화 | 생성, 편집, 애니메이션(립싱크) 각각 다른 모델 사용 (유지보수 비용 극대화) | 단일 프레임워크 (Unified Framework) 통합으로 파이프라인 간소화 |
| 다중 인물 제어 | 얼굴과 목소리(Identity-Timbre) 바인딩 실패, 화자 혼동 빈번 | 이중 레벨 분리 제어로 화자와 목소리를 완벽히 매핑 |
| 학습 안정성 | 상충하는 Objective로 인한 Overfitting 및 성능 저하 | Multi-Task Progressive Training으로 안정적인 학습 |
특히 영상 속에 두 명 이상의 인물이 등장할 때, A의 얼굴에 B의 목소리가 입혀지거나 화자의 입모양이 엉뚱하게 움직이는 Identity-Timbre Binding Failure는 기업이 이 기술을 B2B AI SaaS로 상용화하는 데 가장 큰 걸림돌이었습니다.
[3] 🔥 Core Methodology & Architecture
DreamID-Omni는 이 문제를 해결하기 위해 Symmetric Conditional Diffusion Transformer (대칭적 조건부 DiT)를 도입했습니다. 어려운 수식 대신, 직관적인 비유로 이해해 볼까요?
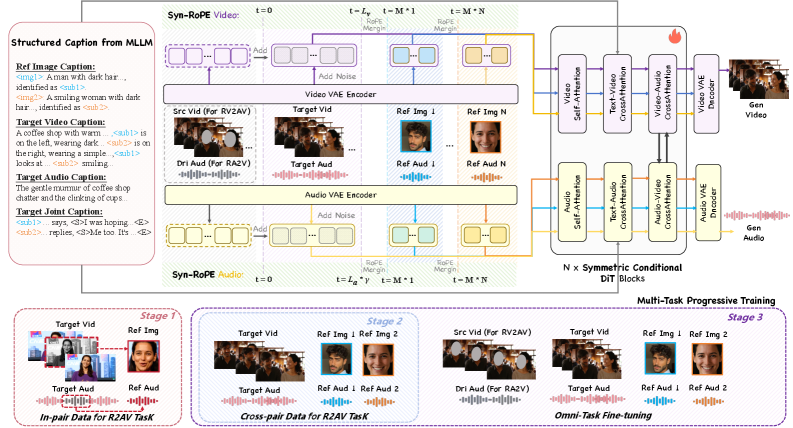 그림 2: DreamID-Omni의 전체 아키텍처. Symmetric Conditional DiT를 기반으로 하며 Structured Caption과 Syn-RoPE를 결합해 이중 레벨의 통제력을 갖췄습니다.
그림 2: DreamID-Omni의 전체 아키텍처. Symmetric Conditional DiT를 기반으로 하며 Structured Caption과 Syn-RoPE를 결합해 이중 레벨의 통제력을 갖췄습니다.
🛠️ 1. Symmetric Conditional Injection (오케스트라 지휘자)
시각 정보(캐릭터의 외모)와 청각 정보(목소리 톤과 발화)는 서로 완전히 다른 형태의 데이터(Heterogeneous)입니다. DreamID-Omni는 이 둘을 편향 없이 대칭적으로 모델에 주입합니다. 마치 뛰어난 오케스트라 지휘자가 현악기(비주얼)와 관악기(오디오) 중 어느 한쪽에 치우치지 않고 완벽한 하모니를 만들어내는 것과 같습니다.
🛠️ 2. Dual-Level Disentanglement (이름표와 지정석)
다중 인물의 정보가 섞이지 않게 하는 이 논문의 가장 빛나는 핵심 기여입니다.
- 신호 레벨 (Synchronized RoPE): 모델의 Attention 공간에서 캐릭터와 목소리에 ‘절대적인 지정석’을 부여합니다 (Rigid binding).
- 의미 레벨 (Structured Captions): 텍스트 프롬프트를 명확하게 구조화하여, “A 속성은 A 인물에게만 적용된다”는 ‘명확한 이름표’를 달아줍니다 (Attribute-subject mappings).
🛠️ 3. Multi-Task Progressive Training (점진적 과부하 학습)
강하게 제약된(Strongly-constrained) 태스크와 약하게 제약된(Weakly-constrained) 태스크를 한 번에 학습시키면 모델이 무너집니다. 연구진은 점진적 학습 체계를 도입하여, 모델이 범용적인 생성 능력(Prior)을 먼저 갖춘 뒤 복잡한 개별 태스크를 정교하게 수행하도록 유도해 Overfitting을 방지했습니다.
[4] 💼 Practical Application & Market Impact
DreamID-Omni의 등장은 단순한 연구 성과를 넘어, 콘텐츠 제작 패러다임과 Tech Investment 관점에서 거대한 시장 기회를 시사합니다.
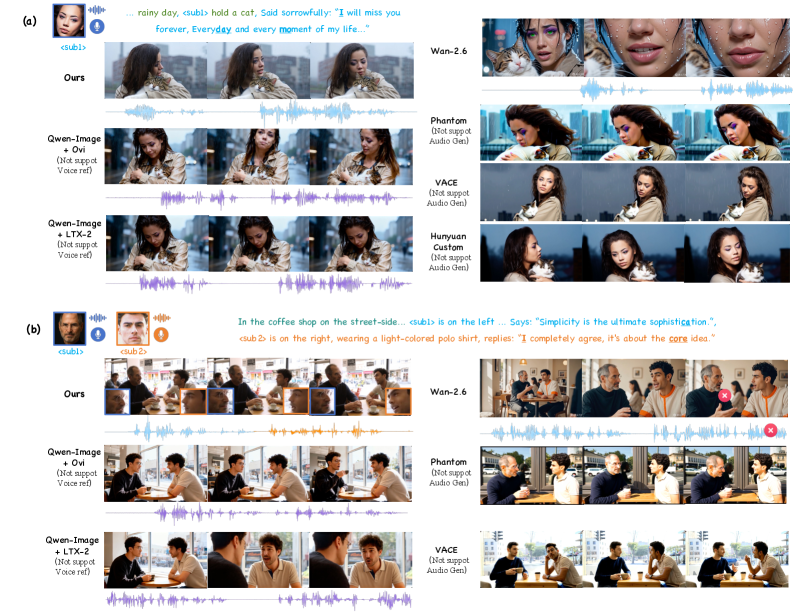 그림 3: SOTA R2AV 모델들과의 정성적 비교. 다중 인물 상황에서도 압도적인 디테일을 유지합니다.
그림 3: SOTA R2AV 모델들과의 정성적 비교. 다중 인물 상황에서도 압도적인 디테일을 유지합니다.
- 🚀 B2B AI SaaS 최적화: 그동안 생성, 편집, 립싱크를 위해 여러 개의 무거운 모델을 파이프라인에 얹어야 했습니다. 이제 단일 모델 인퍼런스로 통합되어 Cloud Infrastructure의 GPU 서빙 비용이 기하급수적으로 감소(ROI 증대)합니다.
- 🎬 초개인화 자동 더빙 & 버추얼 스튜디오: 글로벌 다국어 영상 콘텐츠 제작 시, 입모양(립싱크)과 목소리 톤을 완벽하게 맞추면서 원본 배우의 미세한 감정선까지 그대로 가져갈 수 있습니다.
- 💰 엔터프라이즈 마케팅 자동화: 다수의 아바타가 등장하는 기업 교육용 영상이나 홍보물을 프롬프트와 오디오 스크립트만으로 대량 생산할 수 있는 길을 열었습니다.
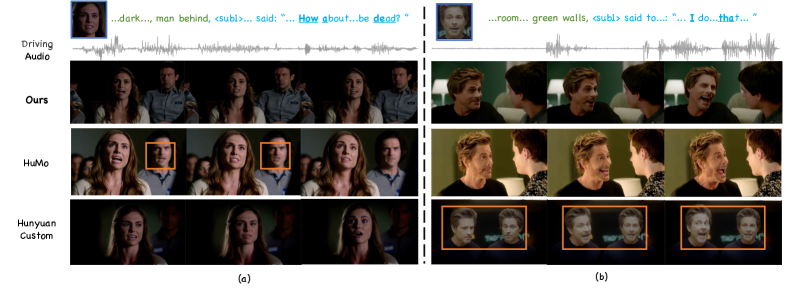 그림 5: 오디오 기반 비디오 애니메이션(RA2V) SOTA 비교. 입모양과 얼굴 표정의 자연스러운 동기화가 돋보입니다.
그림 5: 오디오 기반 비디오 애니메이션(RA2V) SOTA 비교. 입모양과 얼굴 표정의 자연스러운 동기화가 돋보입니다.
[5] 🧑💻 Expert’s Touch (Critique & Implementation)
현업 AI 스타트업 리드이자 연구자의 시선에서 본 DreamID-Omni의 인사이트입니다.
⚡ 한 줄 평: “A/V 파운데이션 모델의 파편화를 끝내고, ‘제어 가능성(Controllability)’이라는 마지막 퍼즐을 맞춘 기념비적 통합 아키텍처.”
🚧 Technical Limitations & Scaling Challenges
- VRAM 압박과 Edge Computing의 한계: 비디오와 고음질 오디오를 동시에 처리하는 DiT 구조의 특성상 파라미터 수가 막대할 것입니다. 실시간 렌더링이 필요한 Edge Computing이나 On-Device AI 환경에 적용하기에는 경량화(Quantization/Pruning) 및 Model Optimization 연구가 추가로 필요합니다.
- 오디오 레이턴시: 실시간 대화형 AI(예: 화상회의 아바타)에 직접 적용하기 위해서는 단일 프레임워크의 생성 속도 최적화가 필수적일 것입니다.
🛠️ Practical Tips for Developers
- 파이프라인 통합: 기업 내 영상 생성 파이프라인을 구축 중이라면, 기존의
Stable Video Diffusion + Wav2Lip같은 분리형 시스템을 폐기하고 추후 공개될 DreamID-Omni 기반의 단일 엔드포인트로 마이그레이션하는 것을 적극 고려하세요. - 오픈소스 대비: 논문에서 코드를 오픈소스로 공개하겠다고 명시한 만큼, 공식 GitHub 릴리스 즉시 LoRA (Low-Rank Adaptation) 파인튜닝을 통해 자사 브랜드 캐릭터에 특화(Domain-adaptation)하는 PoC(개념 증명)를 빠르게 시도해 보시길 권장합니다.
AI 영상 생성이 단순한 ‘화질 경쟁’을 넘어 완벽한 ‘제어’의 시대로 진입하고 있습니다. DreamID-Omni가 열어갈 새로운 비디오 커머스와 콘텐츠 시장의 혁신을 기대해 봅니다! 🚀
Additional Figures
 Figure 4:Qualitative comparisonwith SOTA methods on RV2AV. Please zoom in for more details.
Figure 4:Qualitative comparisonwith SOTA methods on RV2AV. Please zoom in for more details.
