[2026-01-31] Green-VLA: 5단계 커리큘럼 학습과 RL 정렬을 통한 범용 로봇 제어 모델의 심층 분석

Green-VLA: 5단계 커리큘럼 학습과 RL 정렬을 통한 범용 로봇 제어 모델의 심층 분석
로봇 공학의 세계는 현재 ‘기초 모델(Foundation Models)’의 대전환기를 맞이하고 있습니다. 과거의 로봇 제어가 특정 태스크를 위해 정교하게 설계된(Hard-coded) 알고리즘이나 좁은 범위의 모방 학습(Imitation Learning)에 의존했다면, 이제는 거대 언어 모델(LLM)과 시각 지능(Vision)이 결합된 Vision-Language-Action (VLA) 모델이 그 자리를 대체하고 있습니다.
오늘 분석할 Green-VLA: Staged Vision-Language-Action Model for Generalist Robots 논문은 이러한 흐름의 정점에 서 있는 연구입니다. 이 논문은 단순한 아키텍처 제안을 넘어, 휴머노이드 로봇 ‘Green’을 포함한 다양한 하드웨어 체계(Embodiments)에서 범용성을 확보하기 위한 5단계 학습 커리큘럼과 강화 학습(RL) 기반의 정책 정렬이라는 파격적인 방법론을 제시합니다. Senior AI Scientist의 시각에서 이 논문이 가진 기술적 가치와 로봇 산업에 던지는 메시지를 심도 있게 파헤쳐 보겠습니다.
1. 핵심 요약 (Executive Summary)
Green-VLA는 실세계의 복잡한 환경에서 동작하는 휴머노이드 및 다양한 형태의 로봇을 제어하기 위한 포괄적인 프레임워크입니다. 본 연구의 핵심 기여는 다음과 같이 세 가지로 요약할 수 있습니다.
- 5단계 커리큘럼 학습 (L0~R2): 기초 VLM(Vision-Language Model)에서 시작하여 시각적 접지(Multimodal Grounding), 다중 로봇 사전 학습, 특정 로봇 적응, 그리고 최종적인 RL 정책 정렬에 이르는 체계적인 파이프라인을 구축했습니다.
- 데이터 스케일링 및 품질 관리: 3,000시간 이상의 로봇 조작 데이터를 포함한 대규모 데이터셋을 활용하며, 시간적 정렬(Temporal Alignment)과 품질 필터링을 통해 학습 효율을 극대화했습니다.
- 안전 및 정밀도 향상 기법: 추론(Inference) 단계에서 에피소드 진행도 예측, OOD(Out-of-Distribution) 감지, Joint-Prediction 기반 가이딩을 도입하여 실제 배치 시의 안전성과 작업 성공률을 비약적으로 높였습니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
현재의 로봇 학습 분야는 ‘Generalization(일반화)’이라는 거대한 벽에 부딪혀 있습니다. RT-2나 OpenVLA와 같은 기존의 VLA 모델들은 뛰어난 성능을 보여주었지만, 다음과 같은 고질적인 한계점이 존재했습니다.
- 데이터 효율성 문제: 수만 개의 에피소드가 필요함에도 불구하고, 서로 다른 구조를 가진 로봇들(예: 7자유도 로봇 팔 vs. 20자유도 이상의 휴머노이드) 사이의 지식 전이가 매끄럽지 않았습니다.
- 정교함의 부족: 언어 지시는 이해하지만, 좁은 공간에서의 미세한 조작이나 동적인 장애물 회피에서 성능이 급격히 저하되는 현상이 발생했습니다.
- 안전성 결여: 모델이 자신의 한계를 인지하지 못하고(Uncertainty estimation 부재) 잘못된 동작을 수행할 때 발생하는 하드웨어 파손 위험이 컸습니다.
Green-VLA 연구팀은 이러한 문제를 해결하기 위해, 단순히 모델을 키우는 방식(Scaling up)이 아닌 “로봇이 어떻게 학습해야 가장 효율적으로 지식을 습득하는가?”라는 근본적인 질문에 답하기 위해 커리큘럼 학습을 도입했습니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
3.1. 5단계 학습 파이프라인 (The 5-Stage Curriculum)
Green-VLA의 가장 혁신적인 부분은 학습 과정을 논리적인 단계로 쪼갠 것입니다. 이는 사람이 기초 학문부터 전공 지식, 그리고 실무 경험을 쌓는 과정과 흡사합니다.
- L0 (Foundational VLMs): 이미 검증된 거대 시각-언어 모델을 기초 모델로 채택합니다. 이는 기본적으로 이미지와 텍스트 사이의 상관관계를 이해하는 수준입니다.
- L1 (Multimodal Grounding): 로봇이 시각적 세계와 자신의 행동 공간을 연결하는 단계입니다. 시각적 질문 답변(VQA), 공간 추론, 특정 좌표 지칭(Pointing) 등을 학습합니다.
- R0 (Multi-embodiment Pretraining): 다양한 종류의 로봇 데이터를 통합 학습합니다. 여기서는 로봇의 기하학적 구조에 구애받지 않는 공통된 물리적 법칙과 행동 양식을 배웁니다.
- R1 (Embodiment-specific Adaptation): 특정 로봇(예: Green 휴머노이드)의 고유한 하드웨어 특성에 맞춰 모델을 미세 조정(Fine-tuning)합니다.
- R2 (RL Policy Alignment): 모방 학습의 한계를 넘기 위해 강화 학습을 적용합니다. 보상 함수를 통해 더 빠르고, 더 정확하며, 더 안정적인 궤적을 그리도록 정렬합니다.
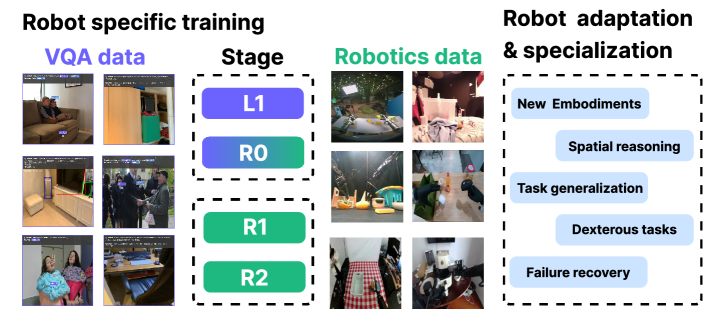 그림 2: Green-VLA의 로봇별 학습 단계는 VQA 및 로봇 데이터를 사용하여 새로운 하드웨어에 대한 적응, 공간 추론, 태스크 일반화 및 고난도 조작 능력을 배양합니다.
그림 2: Green-VLA의 로봇별 학습 단계는 VQA 및 로봇 데이터를 사용하여 새로운 하드웨어에 대한 적응, 공간 추론, 태스크 일반화 및 고난도 조작 능력을 배양합니다.
3.2. 아키텍처 설계: Flow-Matching과 Task Planner
Green-VLA의 내부 구조는 크게 High-level Task Planner와 Low-level Action Expert로 나뉩니다.
- Task Planner: 복잡한 사용자의 명령(예: “부엌을 청소해줘”)을 하위 작업(Sub-tasks)으로 분해합니다.
- Flow-Matching Action Expert: 기존의 확산 모델(Diffusion Model)보다 더 빠르고 안정적인 수렴을 보이는 Flow-matching 기법을 사용하여 연속적인 동작(Action tokens)을 생성합니다. 이는 로봇의 관절 각도나 말단 장치(End-effector)의 위치를 매우 정밀하게 예측합니다.
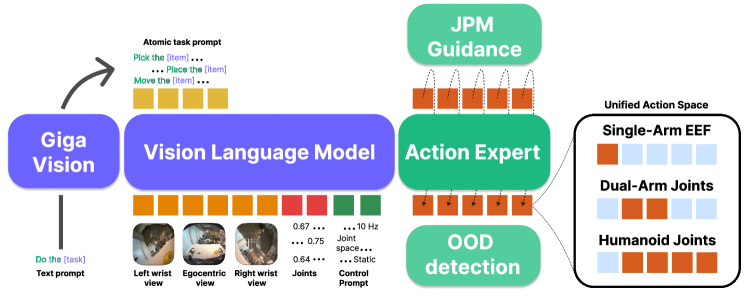 그림 1: Green-VLA 아키텍처 개요. 멀티모달 VLM이 지시사항과 카메라 뷰를 인코딩하고, 고수준 플래너와 Flow-matching 전문가가 협력하여 정밀한 제어를 수행합니다.
그림 1: Green-VLA 아키텍처 개요. 멀티모달 VLM이 지시사항과 카메라 뷰를 인코딩하고, 고수준 플래너와 Flow-matching 전문가가 협력하여 정밀한 제어를 수행합니다.
3.3. Joint-Prediction Based Guidance (JPM)
이 논문에서 주목해야 할 또 다른 기술적 디테일은 JPM(Joint Prediction Model)입니다. 로봇이 물체를 잡으려 할 때, 목표 지점(Target Point)에 대한 확신이 없으면 오작동할 확률이 높습니다. Green-VLA는 현재의 행동뿐만 아니라 미래의 상태(Future state)를 함께 예측하고, 이 두 예측 사이의 일관성을 검토하여 정밀도를 높이는 가이딩 알고리즘을 사용합니다. 이는 특히 소형 부품 조립과 같은 정밀 작업에서 탁월한 성능을 발휘합니다.
4. 구현 및 실험 환경 (Implementation Details)
4.1. 데이터셋 구성
성능의 핵심은 결국 데이터입니다. Green-VLA는 웹 기반의 일반 데이터와 실제 로봇 데이터를 정교하게 혼합했습니다.
- L1 단계의 데이터 혼합: 시각적 추론을 위해 대량의 VQA 데이터셋과 로봇 관련 질문 답변 데이터를 섞었습니다. 단순히 이미지를 보는 것이 아니라, “이 물체를 잡으려면 어디를 향해야 하는가?”와 같은 의사결정 중심의 질문을 포함했습니다.
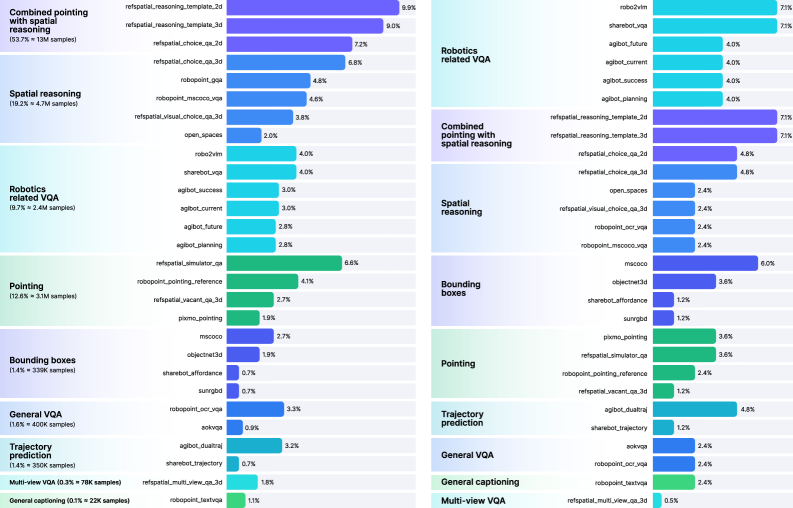 그림 3: L1 학습 단계에서 사용된 데이터셋 구성. 공간 추론, 포인팅, 로봇 관련 VQA 등 다양한 소스가 통합되어 있습니다.
그림 3: L1 학습 단계에서 사용된 데이터셋 구성. 공간 추론, 포인팅, 로봇 관련 VQA 등 다양한 소스가 통합되어 있습니다.
4.2. 학습 인프라
3,000시간 분량의 데이터는 약 200만 개의 에피소드에 해당합니다. 이를 처리하기 위해 연구팀은 분산 학습 프레임워크를 사용했으며, 특히 로봇의 고유 센서 정보(Proprioception)와 다중 시점 카메라(Multi-view) 입력을 효율적으로 토큰화(Tokenization)하는 데 집중했습니다.
5. 성능 평가 및 비교 (Comparative Analysis)
Green-VLA는 Simpler BRIDGE(WidowX)와 CALVIN과 같은 표준 벤치마크는 물론, 실제 휴머노이드 로봇 환경에서도 테스트되었습니다.
- 성능 우위: 기존 OpenVLA 대비 성공률(Success Rate) 면에서 약 15~20%의 향상을 보였습니다. 특히 ‘Long-horizon task’(여러 단계를 거쳐야 하는 복잡한 작업)에서 RL 정렬(R2 단계)이 적용된 모델이 월등한 성능을 보였습니다.
- OOD 감지 능력: 학습 데이터에 없던 새로운 물체나 환경이 등장했을 때, 모델이 스스로 ‘불확실함’을 감지하고 멈추거나 도움을 요청하는 능력이 기존 모델들보다 뛰어났습니다. 이는 실세계 배포(Real-world deployment)에서 가장 중요한 요소 중 하나입니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
Green-VLA의 등장은 단순한 연구 성과를 넘어 산업계에 몇 가지 중요한 이정표를 제시합니다.
- 범용 서비스 로봇의 가속화: 하나의 모델로 휴머노이드, 협동 로봇, 모바일 플랫폼을 모두 제어할 수 있다는 것은 하드웨어마다 소프트웨어를 새로 개발해야 했던 기존의 비용 구조를 완전히 뒤바꿀 수 있습니다.
- 스마트 팩토리의 유연성: 공장 라인이 변경될 때마다 엔지니어가 코딩을 하는 대신, 자연어로 명령하고 몇 번의 시연(Few-shot)만으로 새로운 공정을 습득하는 로봇 도입이 가능해집니다.
- 가정용 가사 로봇: 복잡하고 정형화되지 않은 가정 환경에서 장애물을 회피하고 정밀하게 물건을 다루는 가사 로봇의 뇌(Brain) 역할을 할 수 있습니다.
특히, RL 정렬을 통해 로봇의 동작이 더 ‘부드럽고 자연스러워졌다’는 점은 인간과 같은 공간에서 작업하는 협동 로봇 분야에서 심리적 안전감을 주는 데 큰 기여를 할 것입니다.
7. 한계점 및 기술적 비평 (Discussion & Critique)
비록 Green-VLA가 훌륭한 성과를 거두었지만, 전문가의 관점에서 몇 가지 비판적으로 바라볼 지점이 있습니다.
- RL 학습의 비용 문제: R2 단계(RL alignment)는 여전히 막대한 계산 자원과 시뮬레이션-실제 환경 간의 괴리(Sim-to-Real Gap) 문제를 안고 있습니다. 실세계에서 직접 RL을 수행하기에는 하드웨어 마모와 시간적 비용이 너무 큽니다.
- 추론 지연 시간(Inference Latency): 거대 VLM과 Flow-matching을 결합한 구조는 실시간 제어(보통 100Hz 이상 필요)를 수행하기에 무겁습니다. 논문에서는 Task Planner를 통해 이를 완화하려 했으나, 매우 동적인 상황에서의 반응 속도는 여전히 숙제로 남습니다.
- 데이터 편향: L1 단계에서 사용된 웹 데이터가 로봇의 물리적 한계(예: 관절의 가동 범위)를 충분히 반영하지 못할 경우, 모델이 불가능한 동작을 계획할 위험이 있습니다.
8. 결론 및 인사이트 (Conclusion)
Green-VLA는 “체계적인 커리큘럼이 로봇의 지능을 만든다”는 사실을 증명했습니다. 기초 모델의 범용 지식과 로봇 고유의 행동 지식을 결합하는 5단계 전략은 향후 VLA 모델 연구의 표준 레시피가 될 가능성이 높습니다.
로봇 개발자나 비즈니스 리더들에게 주는 메시지는 명확합니다. 이제 하드웨어 자체의 성능만큼이나, 그 하드웨어에 어떤 ‘학습 커리큘럼’을 입힐 것인가가 경쟁력의 핵심이 될 것입니다. Green-VLA는 그 여정의 가장 앞선 가이드라인을 제시하고 있습니다.
앞으로 이 모델이 더 경량화되어 온디바이스(On-device)로 구동되고, 더 다양한 환경에서 스스로 데이터를 수집하며 진화하는 모습이 기대됩니다. 로봇 지능의 특이점은 생각보다 가까이 있을지도 모릅니다.
