[2026-02-05] [AI 심층 분석] RLVR의 고질적 난제 '답변 길이 편향' 해결: LUSPO 알고리즘의 등장과 기술적 혁신

1. 핵심 요약 (Executive Summary)
최근 대규모 언어 모델(LLM)과 시각-언어 모델(VLM) 분야에서 검증 가능한 보상을 활용한 강화학습(Reinforcement Learning with Verifiable Rewards, RLVR)은 모델의 추리 능력을 비약적으로 향상시키는 핵심 기술로 자리 잡았습니다. OpenAI의 o1이나 DeepSeek-R1과 같은 모델들이 보여준 놀라운 추론 성능의 이면에는 RLVR을 통한 ‘사고의 연쇄(Chain-of-Thought, CoT)’ 고도화가 자리 잡고 있습니다.
그러나 RLVR 과정에서 한 가지 기묘한 현상이 발견되었습니다. 바로 알고리즘의 선택에 따라 모델이 출력하는 답변의 길이가 비정상적으로 길어지거나(Length Explosion), 반대로 급격히 짧아지며 추론 능력이 퇴화하는(Length Collapse) 현상입니다. 본 분석에서는 이러한 현상의 수학적 근본 원인을 규명하고, 이를 해결하기 위해 제안된 Length-Unbiased Sequence Policy Optimization (LUSPO) 알고리즘을 심층적으로 다룹니다.
LUSPO는 기존의 GSPO(Group Sequence Policy Optimization)가 가졌던 길이 편향(Length Bias)을 수학적으로 교정하여, 모델이 불필요하게 답변을 줄이지 않으면서도 최적의 추론 경로를 탐색할 수 있도록 설계되었습니다. 본 보고서는 LUSPO의 이론적 배경부터 실험 결과, 그리고 향후 AI 산업에 미칠 파급력까지 Senior Chief AI Scientist의 시각에서 전문적으로 분석합니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
2.1 RLVR과 추론 능력의 상관관계
RLVR은 수학 문제 풀이나 코드 생성과 같이 정답 여부를 명확히 판별할 수 있는 태스크에서 특히 강력한 성능을 발휘합니다. 모델이 생성한 여러 답변 중 정답을 맞힌 샘플에 높은 보상을 부여함으로써, 모델은 정답에 도달하기 위한 논리적 추론 과정을 스스로 학습하게 됩니다. 이 과정에서 공통적으로 관찰되는 현상은 ‘답변 길이의 증가’입니다. 복잡한 문제를 풀기 위해 모델이 더 많은 중간 사고 단계를 거치게 되면서 자연스럽게 출력이 길어지는 것입니다.
2.2 알고리즘별 답변 길이의 극단적 변화
하지만 연구팀은 흥미로운 사실을 발견했습니다. 널리 사용되는 강화학습 알고리즘인 GRPO(Group Relative Policy Optimization)와 GSPO를 동일한 환경에서 테스트했을 때, 답변 길이의 변화 양상이 정반대로 나타났다는 점입니다.
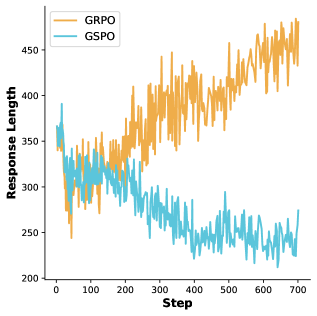 그림 1: Qwen2.5-VL-7B-Instruct 모델의 RLVR 학습 중 답변 길이 변화. GRPO는 길이가 증가하는 반면, GSPO는 길이가 급격히 감소하는 ‘길이 붕괴’ 현상을 보입니다.
그림 1: Qwen2.5-VL-7B-Instruct 모델의 RLVR 학습 중 답변 길이 변화. GRPO는 길이가 증가하는 반면, GSPO는 길이가 급격히 감소하는 ‘길이 붕괴’ 현상을 보입니다.
위 그림에서 볼 수 있듯이, GRPO는 학습이 진행됨에 따라 답변 길이가 점진적으로 늘어나는 반면, GSPO는 초기에는 성능이 오르는 듯하다가 이내 답변 길이가 짧아지며 성능 정체 혹은 하락을 경험합니다. 왜 이런 차이가 발생하는 것일까요? 단순히 알고리즘의 특성일까요, 아니면 수식 속에 숨겨진 근본적인 편향 때문일까요? 이 질문이 LUSPO 연구의 출발점입니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
3.1 GSPO의 수학적 결함: 길이 편향(Length Bias)
GSPO는 전체 시퀀스의 로그 확률 합을 기반으로 손실 함수를 계산합니다. 연구팀은 GSPO의 목적 함수를 수학적으로 분해한 결과, 기댓값의 기울기(Gradient of Expectation) 계산 과정에서 답변 길이에 비례하는 편향 성분이 포함되어 있음을 증명했습니다.
간단히 설명하자면, GSPO의 손실 함수는 다음과 같은 구조를 가집니다: \(abla J_{GSPO} \approx \mathbb{E} [ (R - \bar{R}) \sum_{t=1}^L abla \log \pi(a_t | s_t) ]\)
여기서 문제는 보상($R$)이 시퀀스 전체에 대해 주어지는데, 이를 각 토큰의 로그 확률 합에 곱하는 방식이 답변이 긴 시퀀스에 대해 더 큰 가디언트(Gradient)를 생성하게 만든다는 점입니다. 하지만 반대로, 평균 보상($\bar{R}$)을 계산할 때 그룹 내의 샘플들이 서로 다른 길이를 가질 경우, 짧은 답변이 상대적으로 ‘유리하게’ 평가되는 통계적 왜곡이 발생합니다. 결과적으로 모델은 보상을 극대화하기 위해 내용을 풍부하게 만들기보다는, 손실을 줄이기 위해 답변 길이를 줄이는 ‘치팅(Cheating)’ 전략을 선택하게 됩니다.
3.2 LUSPO: 길이 중립적 최적화의 구현
LUSPO는 이러한 GSPO의 수식을 재설계하여 길이 중립성(Length Neutrality)을 확보합니다. 핵심은 토큰 수준의 보상 할당 방식을 개선하고, 전체 시퀀스 길이에 의존적인 항을 정규화(Normalization)하는 것입니다.
LUSPO의 손실 함수는 다음과 같은 혁신을 담고 있습니다:
- 샘플 수준의 가중치 조정: 시퀀스 길이에 따라 가디언트의 크기가 변하지 않도록 $1/L$ 인자를 도입하여 정규화합니다.
- 무편향 이점(Advantage) 추정: 그룹 내 상대적 보상을 계산할 때 길이로 인한 노이즈를 제거하여, 오직 ‘추론의 질’만이 보상에 반영되도록 합니다.
이러한 정교한 수정을 통해 LUSPO는 GSPO의 효율성과 GRPO의 안정적인 길이 성장을 동시에 달성할 수 있었습니다.
4. 구현 및 실험 환경 (Implementation Details & Experiment Setup)
4.1 모델 및 데이터셋
본 연구는 최신 VLM인 Qwen2.5-VL-7B-Instruct와 LLM인 Qwen2.5-7B-Base를 기반으로 수행되었습니다. 실험 데이터셋은 다음과 같은 고난도 추론 태스크로 구성되었습니다.
- 수학 추론: MATH-500, GSM8K
- 멀티모달 추론: MathVista, ScienceQA, MMMU
4.2 시스템 프롬프트 및 학습 설정
모델이 추론 과정을 명확히 드러내도록 하기 위해 아래와 같은 특수한 시스템 프롬프트가 사용되었습니다.
 그림 2: 시각-언어 모델(VLM) 학습에 사용된 시스템 프롬프트. ‘thought’ 태그를 사용하여 모델이 중간 추론 단계를 명시하도록 유도합니다.
그림 2: 시각-언어 모델(VLM) 학습에 사용된 시스템 프롬프트. ‘thought’ 태그를 사용하여 모델이 중간 추론 단계를 명시하도록 유도합니다.
이 프롬프트는 모델이 정답을 내놓기 전에 반드시 <thought> 섹션을 거치도록 강제하며, 이는 RLVR 보상 체계가 ‘결과’뿐만 아니라 ‘과정’의 논리성을 간접적으로 평가할 수 있는 기반이 됩니다.
5. 성능 평가 및 비교 (Comparative Analysis)
5.1 데이터셋별 길이 변화 추이 분석
LUSPO의 가장 큰 성과는 데이터셋의 성격에 관계없이 안정적인 답변 길이를 유지하며 학습이 진행된다는 점입니다.
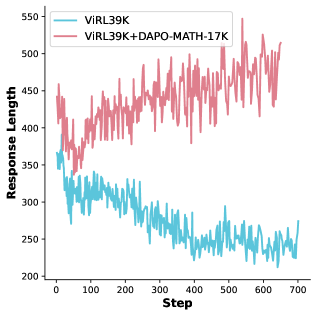 그림 3: 다양한 데이터셋에서 GSPO의 길이 변화. 데이터셋의 난이도나 특성에 따라 길이가 요동치는 불완전한 모습을 보입니다.
그림 3: 다양한 데이터셋에서 GSPO의 길이 변화. 데이터셋의 난이도나 특성에 따라 길이가 요동치는 불완전한 모습을 보입니다.
반면 LUSPO는 수학적 보정이 적용됨에 따라, 모델이 억지로 길이를 줄이려 하지 않고 정답을 찾기 위해 필요한 최적의 길이를 유지하는 양상을 보였습니다.
5.2 벤치마크 성능 비교
실험 결과, LUSPO는 거의 모든 지표에서 GRPO와 기존 GSPO를 압도했습니다. 특히 복잡한 수학 문제(MATH-500)에서 눈에 띄는 성능 향상을 기록했습니다.
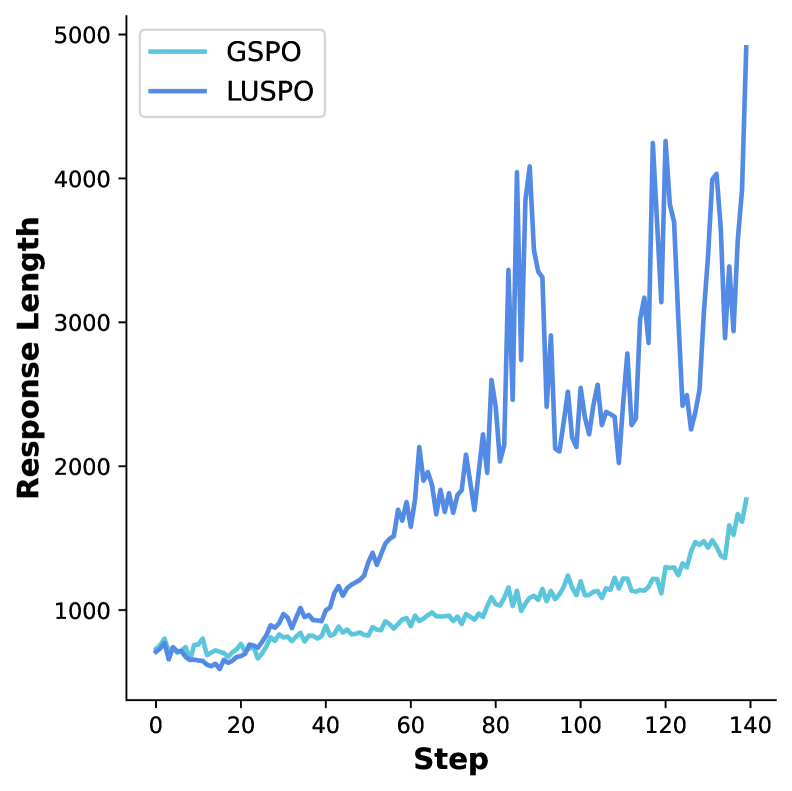 그림 4: Qwen2.5-7B-Base 모델의 벤치마크 성능 비교. LUSPO가 GRPO 대비 일관되게 높은 정확도를 기록하고 있음을 알 수 있습니다.
그림 4: Qwen2.5-7B-Base 모델의 벤치마크 성능 비교. LUSPO가 GRPO 대비 일관되게 높은 정확도를 기록하고 있음을 알 수 있습니다.
전문가적 시각에서 볼 때, LUSPO의 진가는 단순히 점수가 높다는 데 있지 않습니다. ‘학습의 효율성’ 면에서 GSPO의 장점(메모리 절약 및 빠른 수렴)을 유지하면서도, GRPO가 가진 ‘추론의 깊이’를 확보했다는 점이 핵심입니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
LUSPO 알고리즘은 단순히 논문 속의 이론에 그치지 않고, 차세대 AI 서비스 구현에 즉각적인 영향을 미칠 수 있습니다.
- 엔터프라이즈급 추론 엔진 구축: 기업용 세무, 회계, 법률 AI 시스템은 극도로 정교한 CoT가 필요합니다. LUSPO를 적용하면 모델이 답변을 생략하거나 논리적 비약을 일으키는 ‘길이 붕괴’ 현상을 방지하여 신뢰도를 높일 수 있습니다.
- 경량 모델의 성능 극대화: 7B 이하의 작은 모델들도 LUSPO 기반의 RLVR을 거치면, 파라미터 수의 한계를 뛰어넘는 추론 성능을 확보할 수 있습니다. 이는 온디바이스 AI(On-device AI) 환경에서 매우 중요한 경쟁력이 됩니다.
- 멀티모달 에이전트 개발: 이미지와 텍스트를 동시에 이해해야 하는 VLM 에이전트의 경우, 시각적 정보를 텍스트로 치환하여 논리적으로 분석하는 과정이 필수적입니다. LUSPO는 이러한 복합적인 추론 과정이 안정적으로 학습되도록 돕습니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critical Critique)
본 연구는 탁월한 성과를 보였으나, 몇 가지 비판적 시각을 견지할 필요가 있습니다.
첫째, ‘길이=지능’이라는 암묵적 가정에 대한 의문입니다. LUSPO는 길이 붕괴를 막아 성능을 높였지만, 이는 곧 추론 시 토큰 소모량(Inference Cost)의 증가를 의미합니다. 산업계에서는 ‘가장 짧으면서도 정확한 답변’을 원하는데, LUSPO가 도달하는 ‘최적의 길이’가 과연 효율성 측면에서도 최적인지는 추가 연구가 필요합니다.
둘째, 보상 함수(Reward Function)의 단순성입니다. 현재의 RLVR은 주로 정답 여부(Binary reward)에 의존합니다. 답변이 길어지면서 정답을 맞히긴 했으나 과정에 ‘환각(Hallucination)’이 포함되어 있을 경우, LUSPO가 이러한 질적 저하를 걸러낼 수 있을지는 불분명합니다.
셋째, 하드웨어 의존성입니다. LUSPO는 그룹 샘플링 방식을 취하므로, 한 번에 많은 수의 샘플을 생성해야 합니다. 이는 VRAM이 제한적인 환경에서의 학습을 어렵게 만들 수 있는 요소입니다.
8. 결론 (Conclusion & Insight)
LUSPO는 RLVR 학습 과정에서 간과되었던 ‘답변 길이의 통계적 편향’을 수면 위로 끌어올리고, 이를 수학적으로 완벽하게 해결한 기념비적인 연구입니다. 기존의 GRPO가 다소 무거운 계산 비용을 요구했다면, LUSPO는 더 가볍고 효율적인 GSPO의 구조를 계승하면서도 강력한 성능을 내는 ‘가장 현실적인 대안’을 제시했습니다.
이제 AI 모델 학습의 패러다임은 단순히 데이터를 쏟아붓는 단계를 넘어, 강화학습 알고리즘의 미세한 수식을 최적화하여 모델의 사고 방식을 제어하는 단계로 진입했습니다. LUSPO는 그 정점에 서 있는 기술 중 하나이며, 앞으로 등장할 수많은 ‘Reasoning Model’들의 기반 기술이 될 것으로 확신합니다.
개발자와 연구자들은 이제 모델의 정확도뿐만 아니라, 그 정확도를 도출하기 위해 모델이 사용하는 ‘언어적 자원(길이)’이 어떻게 최적화되고 있는지 LUSPO의 시각에서 재검토해야 할 시점입니다.
