[2026-03-29] 비전과 오디오를 텍스트처럼 다룬다고? LongCat-Next가 멀티모달의 '프랑켄슈타인 아키텍처'를 박살내는 법

요즘 멀티모달(Multimodal) 모델들의 아키텍처 다이어그램을 뜯어보면 솔직히 한숨부터 나옵니다. 언어 모델(LLM) 뼈대에 비전은 CLIP으로 대충 인코딩해서 붙여놓고, 이미지나 오디오를 ‘생성’하려고 하면 또 어디선가 Diffusion 모델이나 외부 보코더를 끌어와서 덕트 테이프로 칭칭 감아놓은 꼴이죠.
이게 현대적인 아키텍처입니까, 아니면 누더기 프랑켄슈타인 괴물입니까?
파이프라인이 이렇게 파편화되어 있으니 VRAM은 VRAM대로 터져나가고, 모달리티 간의 정렬(Alignment)을 맞추느라 엔지니어들의 피와 땀이 갈려나갑니다. 게다가 이미지를 ‘이해(Understanding)’하는 능력과 ‘생성(Generation)’하는 능력 사이의 성능 간극은 도무지 좁혀지지 않거든요.
그런데 메이투안(Meituan)에서 공개한 LongCat-Next가 이 끔찍한 하이브리드 생태계에 묵직한 돌직구를 던졌습니다. “비전이고 오디오고 나발이고, 그냥 전부 다 텍스트처럼 이산형 토큰(Discrete Tokens)으로 치환해서 Next-Token Prediction으로 끝내버리면 안 돼?”
[Metadata]
- Paper ID: arXiv:2603.27538
- GitHub: https://github.com/meituan-longcat/LongCat-Next
- Authors: Meituan LongCat Team
🔥 The Hook & TL;DR
현재 실무에서 멀티모달 에이전트를 프로덕션에 올려본 분들이라면 다들 공감하실 겁니다. 입력은 LLM으로 처리하고 출력은 Stable Diffusion API를 호출하는 식의 비동기 파이프라인은 유지보수 측면에서 재앙에 가깝습니다. 레이턴시는 늘어지고, 장애 포인트는 두 배가 되죠.
LongCat-Next는 이 문제를 DiNA (Discrete Native Autoregressive)라는 패러다임으로 해결합니다. 이미지, 텍스트, 오디오를 차별하지 않습니다. 전부 동일한 ‘단어(Token)’ 취급을 해버립니다. 마치 우리가 영어와 한국어를 섞어 쓰듯, 트랜스포머가 이미지 픽셀의 패턴과 오디오 파형을 언어처럼 ‘읽고 쓰게’ 만든 겁니다.
TL;DR: 모델 파이프라인에서 Diffusion과 외부 인코더를 싹 다 걷어내고, 임의 해상도의 이미지를 이산형 토큰으로 쪼개는 dNaViT를 도입. 텍스트, 비전, 오디오를 단일 Next-Token Prediction(NTP) 목적 함수로 통합 학습한 진정한 의미의 ‘네이티브’ 멀티모달 파운데이션 모델.
⚙️ 모든 것을 ‘토큰’으로 치환하는 흑마법: DiNA & dNaViT 해부
이 논문의 핵심은 연속적인(Continuous) 비전 신호를 어떻게 손실 없이 이산적인(Discrete) 토큰으로 변환하느냐에 있습니다. 기존에도 VQ-VAE 같은 시도들이 있었지만, 해상도가 고정되어 있거나 토큰 변환 과정에서 중요한 디테일(Low-level signal)이 박살나는 문제가 있었죠.
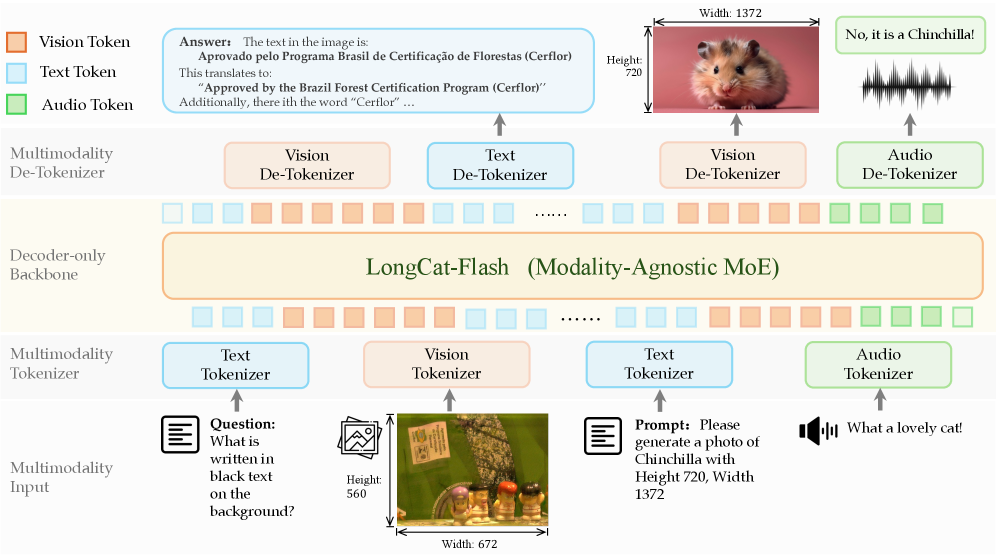
- 기술적 의미: 언어, 비전, 오디오가 별도의 어댑터나 브릿지 없이 완벽히 동일한 트랜스포머 블록을 통과하는 DiNA 패러다임을 보여줍니다. 진정한 의미의 End-to-End 오토레그레시브 아키텍처입니다.
여기서 dNaViT (Discrete Native Any-resolution Visual Transformer)가 등장합니다. 이름 그대로 임의의 해상도(Any-resolution)를 처리할 수 있는 비전 트랜스포머입니다.
작동 방식을 로직 레벨로 뜯어볼까요? 이미지가 들어오면 패치 단위로 쪼개고, 이를 RVQ (Residual Vector Quantization)를 통해 계층적 이산 토큰으로 맵핑합니다. 즉, 거시적인 형태부터 미세한 텍스처까지 여러 겹의 토큰으로 압축해버리는 겁니다.
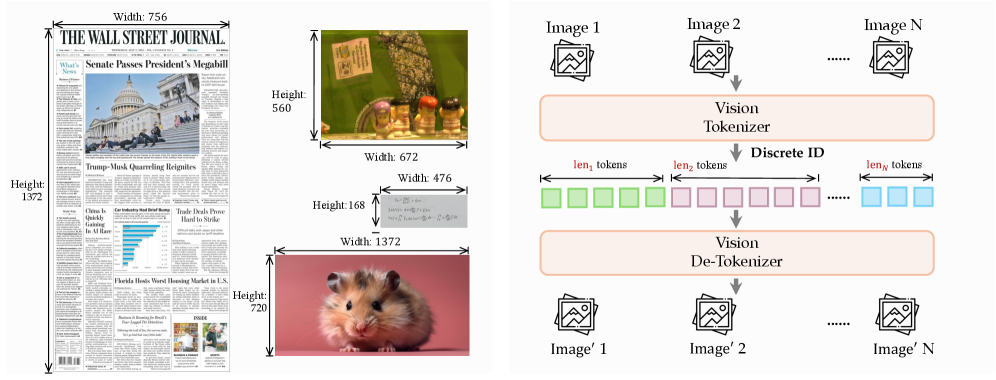
- 기술적 의미: dNaViT가 임의 해상도의 비전 데이터를 동적으로 패치화하고 RVQ를 통해 다중 레벨의 이산형 토큰으로 변환하는 핵심 매커니즘입니다.
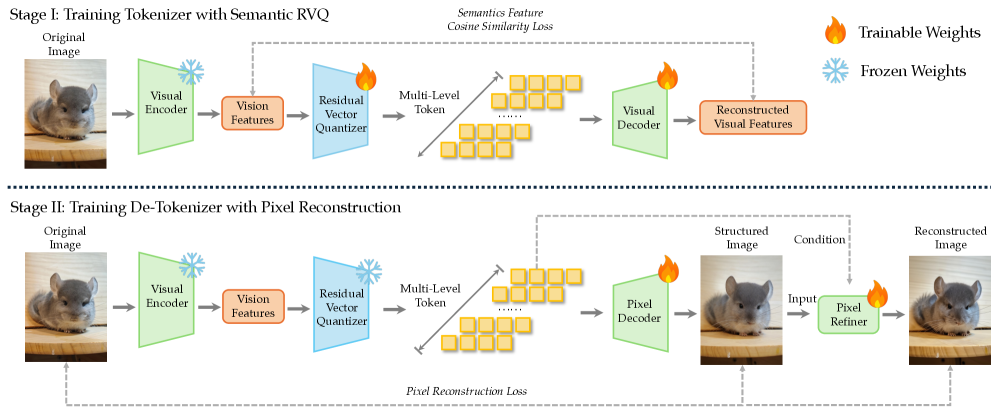
- 기술적 의미: 토크나이저와 디토크나이저의 학습 파이프라인. 경량화된 픽셀 디코더가 이산 토큰을 다시 이미지 공간으로 완벽히 복원(De-tokenize)하는 과정을 증명합니다.
백문이 불여일견이죠. 실제로 이 녀석이 내부적으로 데이터를 어떻게 흘려보내는지 수도 코드(Pseudo-code)로 구성해 봤습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# LongCat-Next: Modality Forward Pass Mock-up
import torch
# 1. 텍스트, 이미지, 오디오가 각각의 토크나이저를 거칩니다.
# 중요한 점: 출력된 텐서의 차원 형태가 [Batch, Seq_Len, Dim]으로 완전히 동일해야 합니다.
text_tokens = bpe_tokenizer(prompt="Draw a cat flying in space", return_tensors="pt")
image_tokens = dNaViT.tokenize(reference_image, resolution="dynamic") # [B, N_img, D]
audio_tokens = audio_tokenizer.tokenize(voice_command) # [B, N_audio, D]
# 2. Modality 구분 없이 무식하게(?) 이어 붙입니다. (Concat)
# 이게 DiNA 패러다임의 핵심입니다. 별도의 cross-attention layer가 없습니다.
unified_context = torch.cat([text_tokens, image_tokens, audio_tokens], dim=1)
# 3. 단일 트랜스포머가 다음 토큰을 예측합니다. (Next-Token Prediction)
# 이 안에서 텍스트를 내뱉을지, 이미지 토큰을 내뱉을지 모델이 스스로 결정합니다.
for _ in range(max_length):
logits = longcat_next_model(unified_context)
next_token = sample(logits)
unified_context = torch.cat([unified_context, next_token], dim=1)
if is_eos(next_token):
break
# 4. 생성된 토큰 스트림을 각 모달리티 디토크나이저로 복원
final_output = dNaViT.detokenize(extract_image_tokens(unified_context))
코드를 보면 아시겠지만, 파이프라인이 소름 돋을 정도로 우아해집니다. 어댑터(Adapter) 코드가 없어요. 프롬프트 엔지니어링 하듯 이미지와 오디오를 배열에 밀어 넣으면 끝납니다.
⚔️ 기존 스택(LLM + Diffusion) vs 새로운 패러다임: 진짜 갈아탈 가치가 있나?
자, “우아한 건 알겠는데, 내 서버 VRAM이랑 API 비용은 어떻게 할 거냐?”라는 질문이 나와야 정상입니다.
기존 산업 표준인 LLaVA + Stable Diffusion 조합과 LongCat-Next를 냉정하게 비교해 봅시다.
| 비교 지표 | 기존 스택 (LLM + Diffusion 하이브리드) | LongCat-Next (Discrete Native) |
|---|---|---|
| 아키텍처 복잡도 | 🤮 극상 (별도의 텍스트/비전/생성 모델 3개 파이프라인 관리) | 😍 최하 (단일 트랜스포머, 1개의 체크포인트) |
| 학습 목적 함수 | Cross-Entropy (LLM) + MSE (Diffusion) 충돌 | 통합 Next-Token Prediction (NTP) 단일화 |
| 이해-생성 일치도 | 낮음 (본 본델은 이해만, 생성은 Diffusion에 외주) | 매우 높음 (이해와 생성의 Latent Space가 동일함) |
| 추론 VRAM (생성시) | 중간~높음 (Diffusion 모델을 VRAM에 별도 적재해야 함) | 💥 폭발 위험 (이미지 토큰이 Sequence Length를 미친듯이 잡아먹음) |
| Time Complexity | $O(N^2)$ (LLM) + $O(T \cdot H \cdot W)$ (Diffusion) | 순수 $O(N^2)$ (단, N이 어마어마하게 큼) |
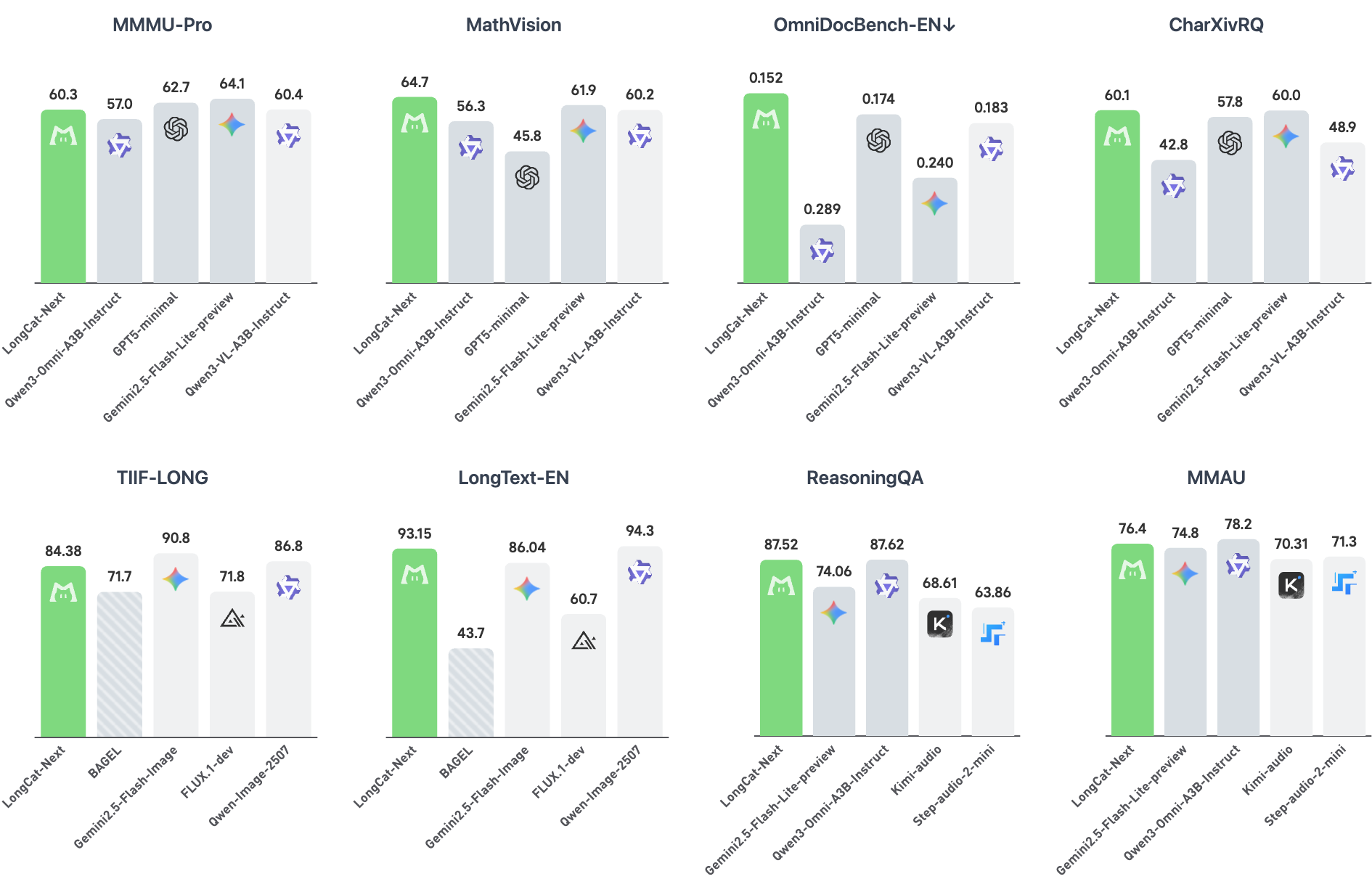
- 기술적 의미: LongCat-Next가 기존 분절된 멀티모달 모델이나 초기 네이티브 모델들을 상대로 시각적 이해(Understanding) 및 생성 벤치마크에서 보여준 압도적 우상향 그래프. 성능의 ‘천장’을 뚫어버렸습니다.
표를 보면 장단점이 명확하죠. 인프라 관리자 입장에서는 모델 3개를 띄우고 서빙해야 하는 지옥에서 벗어나 1개의 파운데이션 모델만 관리하면 되니 환호성을 지를 일입니다.
하지만 개발자라면 Time Complexity와 VRAM 부분에서 등골이 서늘해져야 합니다. 이미지를 이산형 토큰으로 쪼개서 컨텍스트에 넣는다는 건, 고해상도 이미지 한 장이 수천~수만 개의 토큰을 소비한다는 뜻입니다. KV Cache 터지는 소리가 여기까지 들리지 않나요?
🚀 내일 당장 프로덕션에 도입한다면? (그리고 터질만한 곳들)
이 모델을 실무에 올린다면 어떤 그림이 나올지 구체적인 시나리오 2가지를 그려보죠.
시나리오 1: 실시간 음성/비전 기반 로보틱스 에이전트
지금까지 로봇에 탑재되는 비전 언어 모델은 카메라 프레임을 초당 몇 장씩 캡처해서 CLIP으로 임베딩한 뒤 LLM에 쏘는 방식이었습니다. 딜레이가 엄청나죠. LongCat-Next를 경량화해서 엣지 디바이스에 올린다면, 로봇은 들어오는 비전 스트림과 음성 명령을 ‘스트리밍 텍스트 읽듯’ 실시간 오토레그레시브로 처리할 수 있습니다. 중간 변환 병목이 사라져 반응 속도가 비약적으로 상승합니다.
시나리오 2: 초개인화된 대화형 UI/UX 실시간 생성기
유저가 “이 버튼 색깔을 파란색으로 바꾸고 경고음을 넣어줘”라고 말하면, 텍스트 코드를 뱉는 게 아니라 직접 수정된 UI 픽셀(비전 토큰)과 오디오 파형(오디오 토큰)을 동시에 생성해서 반환합니다. 별도의 에셋 파이프라인이 필요 없어집니다.

- 기술적 의미: 가벼운 픽셀 디코더와 Residual connection만으로도 원본 이미지의 Low-level 디테일을 완벽하게 복원해내는 모습. 디토크나이징 과정에서 정보 손실이 극도로 적다는 것을 증명합니다.
💣 치명적인 병목 현상 (Scale Issues)
하지만 당장 프로덕션에 올리기엔 무서운 지뢰들이 숨어있습니다.
- KV Cache 폭발: 앞서 말했듯 컨텍스트 윈도우(Context Window) 소비량이 상상을 초월할 겁니다. FlashAttention-2나 PagedAttention 같은 메모리 최적화 기법을 멀티모달 토큰 길이에 맞춰 극한으로 튜닝하지 않으면 OOM(Out of Memory)으로 서버가 뻗어버릴 겁니다.
- 해상도와 토큰 수의 트레이드오프: dNaViT가 임의 해상도를 지원한다지만, 프로덕션에서 4K 이미지를 그대로 들이밀었다간 추론 비용(API Cost)이 감당 안 될 수준으로 치솟을 겁니다. 입력 전단에서 해상도와 RVQ 레벨을 동적으로 조절하는 라우팅 로직이 필수적입니다.
🧐 Tech Lead’s Honest Verdict
솔직히 말씀드리면, 논문을 읽는 내내 아키텍처의 아름다움에 감탄했습니다. 이해와 생성을 하나의 공간(Discrete Space)에 밀어 넣고 Next-Token Prediction으로 통일해버린 이 무식하면서도 강력한 접근은 향후 3년 내에 업계 표준이 될 확률이 높습니다.
👍 Pros:
- 지긋지긋한 모달리티 간 Alignment, Cross-Attention 튜닝에서 해방.
- 이해(Vision)와 생성(Painting)을 하나의 트랜스포머에서 완벽하게 처리.
- 오픈소스로 풀린 dNaViT 토크나이저 생태계의 무한한 커스텀 가능성.
👎 Cons:
- 시퀀스 길이 폭증으로 인한 추론 단가의 압박 (스타트업에겐 꽤나 부담될 듯).
- 아직 생태계 초창기라 vLLM 같은 고성능 서빙 프레임워크에서의 최적화 지원이 미비할 수 있음.
🔥 Final Verdict: “당장 내부 R&D용으로 클론하되, 프로덕션 서빙은 vLLM 최적화 패치가 나올 때까지 관망하라.”
기존의 Diffusion-LLM 스파게티 코드에 지친 엔지니어라면 이 레포지토리(GitHub: LongCat-Next)를 당장 클론받아서 토크나이저부터 뜯어보시길 권합니다. 패러다임이 변하는 소리가 들리거든요.
