[2026-02-13] MedXIAOHE: 의료 AI의 기술적 정점 - 전문가 수준의 추론과 멀티모달 통합 전략 심층 분석

MedXIAOHE: 의료용 멀티모달 파운데이션 모델의 새로운 기준과 기술적 심층 분석
1. 핵심 요약 (Executive Summary)
현대 의료 인공지능 연구의 가장 큰 화두는 일반 목적의 대규모 언어 모델(LLM)을 넘어, 복잡한 의료 영상과 텍스트 정보를 통합적으로 이해하고 추론할 수 있는 ‘의료용 멀티모달 거대 모델(Medical MLLM)’의 구축입니다. 본 보고서에서 다루는 MedXIAOHE는 이러한 요구에 부응하는 차세대 의료 AI 솔루션으로, 실질적인 임상 적용을 목표로 설계되었습니다. MedXIAOHE의 핵심은 단순한 성능 향상을 넘어, 의료 지식의 희귀성(Long-tail) 문제를 해결하기 위한 Entity-aware Continual Pretraining, 고도의 진단 논리를 학습시키기 위한 Reasoning-aware Mid-training, 그리고 실제 임상 환경에서의 신뢰성을 담보하는 Agentic Tool-augmented Training에 있습니다. 본 분석에서는 MedXIAOHE가 어떻게 폐쇄형 모델인 GPT-4V나 Gemini를 능가하는 성능을 달성했는지, 그 아키텍처와 데이터 엔지니어링의 정수를 심층적으로 파헤칩니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
의료 분야에서 AI의 도입은 오래전부터 시도되어 왔으나, 범용 멀티모달 모델(General MLLM)이 의료 현장에서 직접 사용되기에는 몇 가지 치명적인 한계가 존재합니다.
- 도메인 지식의 깊이와 희귀 질환 문제: 범용 모델은 일반적인 의학 지식은 갖추고 있으나, 희귀 질환(Rare Diseases)이나 복잡한 병리 사진 해석에서 필요한 정밀한 지식이 부족합니다. 이는 데이터 분포의 롱테일(Long-tail) 특성 때문입니다.
- 의료 영상의 다양성과 해상도: 의료 영상은 X-ray, CT, MRI, 병리 슬라이드 등 양식이 매우 다양하며, 암 진단 등에서 미세한 병변을 포착하기 위해서는 초고해상도 처리가 필수적입니다. 기존 모델의 고정 해상도 접근 방식은 정보 손실을 초래합니다.
- 추론의 투명성 및 검증 가능성: 의료 진단은 ‘왜 그런 결론에 도달했는가’에 대한 명확한 근거(Evidence-grounding)가 필요합니다. 단순한 정답 제시가 아닌, 단계별 추론 과정(Reasoning Trace)을 생성하고 이를 검증할 수 있어야 합니다.
- 환각(Hallucination)의 위험성: 일반적인 챗봇의 사소한 실수는 큰 문제가 되지 않지만, 의료 리포트에서의 환각은 치명적인 결과로 이어집니다.
MedXIAOHE는 이러한 문제들을 해결하기 위해 모델 설계 단계부터 ‘의료 전문가의 사고 방식’을 모방하도록 설계되었습니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
MedXIAOHE의 가장 큰 특징은 의료 영상의 특수성을 완벽히 반영한 멀티모달 아키텍처에 있습니다.
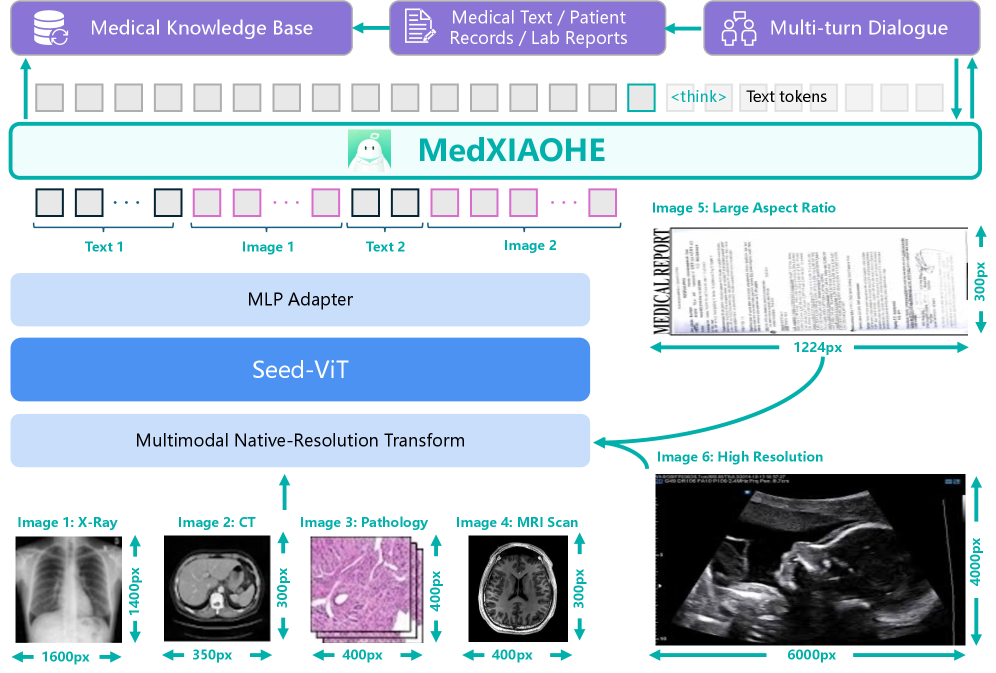 그림 2: MedXIAOHE의 전체 아키텍처. 다양한 의료 영상 모달리티와 해상도를 처리하기 위한 Native-Resolution Transformer 구조를 보여줍니다.
그림 2: MedXIAOHE의 전체 아키텍처. 다양한 의료 영상 모달리티와 해상도를 처리하기 위한 Native-Resolution Transformer 구조를 보여줍니다.
3.1. Multimodal Native-Resolution Transformer
기존의 MLLM들은 입력 영상을 특정 크기(예: 224x224)로 리사이징하거나 크롭(Crop)하여 처리합니다. 하지만 MedXIAOHE는 Native-Resolution 방식을 채택했습니다. 이는 의료 영상의 종횡비와 해상도를 유지하면서 패치(Patch) 단위로 분할하여 처리하는 방식으로, 병리 조직 검사나 미세 골절 판독과 같이 아주 작은 시각적 특징이 중요한 도메인에서 압도적인 강점을 가집니다.
3.2. Seed-ViT 및 MLP Adapter
시각 인코더로 사용된 Seed-ViT는 광범위한 의료 영상 데이터셋으로 사전 학습되어, 단순한 사물 인식을 넘어 의료적 의미를 내포한 특징 벡터를 추출합니다. 이를 텍스트 임베딩 공간과 정렬시키기 위해 강력한 MLP Adapter가 사용되며, 텍스트 토큰과 영상 토큰이 인터리빙(Interleaved)되어 모델이 환자의 기록과 영상을 동시에 참조하며 다중 턴(Multi-turn) 대화를 수행할 수 있게 합니다.
4. 데이터 전략: Mid-training 및 추론 데이터 합성 (Data Engineering)
모델의 성능은 데이터의 질에서 결정됩니다. MedXIAOHE는 단순히 많은 데이터를 넣는 것이 아니라, ‘고품질의 추론 데이터’를 정밀하게 설계했습니다.
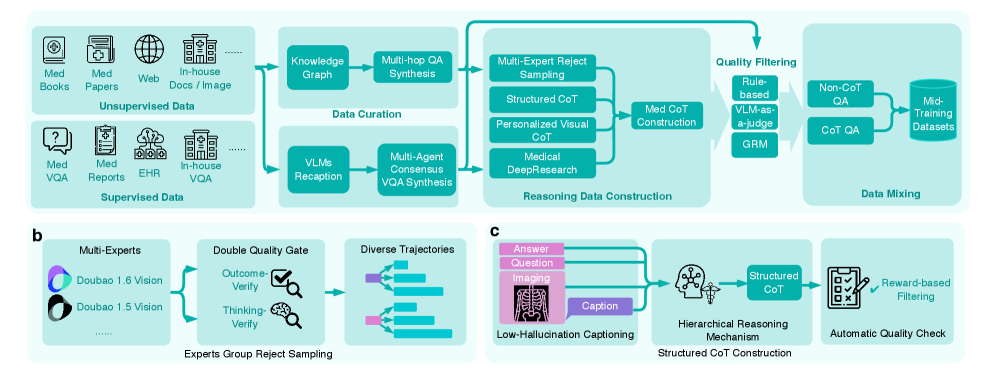 그림 5: Mid-training 데이터 구축 파이프라인. 지식 그래프와 멀티 에이전트 합의를 통해 고품질의 추론 데이터를 생성하는 과정을 나타냅니다.
그림 5: Mid-training 데이터 구축 파이프라인. 지식 그래프와 멀티 에이전트 합의를 통해 고품질의 추론 데이터를 생성하는 과정을 나타냅니다.
4.1. Entity-aware Continual Pretraining
의료 텍스트는 전문 용어가 밀집되어 있습니다. MedXIAOHE는 사전 학습 단계에서 의료 개체(Entity)를 인식하고 이를 중심으로 지식을 구조화하는 방식을 도입했습니다. 이를 통해 롱테일 구간에 위치한 희귀 질환에 대한 지식 결손을 최소화했습니다. 이는 일반적인 언어 모델이 흔한 질병에만 치중되는 경향을 효과적으로 극복한 지점입니다.
4.2. Reasoning-aware Mid-training 파이프라인 (그림 5 상세)
- 데이터 합성 엔진: 비정형 텍스트와 정형화된 지식 그래프(Knowledge Graph)를 결합하여 논리적 일관성이 있는 추론 데이터를 생성합니다. 단순히 ‘질문-답변’ 쌍이 아닌, ‘질문-추론 과정-최종 진단’의 Chain-of-Thought(CoT) 구조를 만듭니다.
- Multi-expert Reject Sampling: 생성된 추론 경로 중 논리적 오류가 있거나 의학적으로 부정확한 것을 걸러내기 위해 다중 전문가 모델이 검증하는 구조를 가집니다. Dual-quality Gate를 통해 인과관계가 명확한 데이터만 선별합니다.
- Hallucination 제거: 시각 정보와 논리적 추론이 어긋나지 않도록 자동 품질 검사 단계를 거칩니다. 이는 모델이 영상에 없는 정보를 지어내는 현상을 획기적으로 줄여줍니다.
5. 구현 및 실험 환경 (Implementation Details)
MedXIAOHE의 학습에는 방대한 컴퓨팅 자원과 정교한 스케줄링이 사용되었습니다. 수천억 개에 달하는 토큰(Tokens)과 수백만 장의 고해상도 의료 영상이 학습에 투입되었습니다. 특히, 강화 학습(Reinforcement Learning) 단계에서는 의료 전문가의 피드백을 반영한 User-preference Rubrics를 활용하여, 모델의 답변 스타일을 실제 의사의 선호도에 맞게 튜닝했습니다. 또한, 도구 활용(Tool-augmented) 능력을 강화하여 외부 의학 데이터베이스나 계산기 등을 에이전트처럼 활용할 수 있도록 학습되었습니다.
6. 성능 평가 및 비교 (Comparative Analysis)
MedXIAOHE는 VQA(Visual Question Answering), 의료 리포트 생성, 임상 추론 등 다양한 벤치마크에서 SOTA를 기록했습니다.
- GPT-4V 대비 우위: 특히 영상 해상도가 중요한 병리 및 방사선 판독 분야에서 GPT-4V보다 정밀한 분석 결과를 보여주었습니다.
- 장문 리포트 생성: 단순히 단답형 답변을 하는 것이 아니라, 구조화된 전문 의료 보고서를 작성하는 능력에서 기존 모델들보다 낮은 환각률과 높은 지침 준수율(Instruction Following)을 보였습니다.
- 추론 가시성: MedXIAOHE는 결론을 내리기까지의 과정을 단계별로 제시함으로써, 의료진이 AI의 판단 근거를 신속하게 검토할 수 있도록 돕습니다.
7. 실제 적용 분야 및 글로벌 파급력 (Real-World Application)
이 모델은 단순한 연구용 결과물에 그치지 않고 다음과 같은 실제 임상 시나리오에 적용될 수 있습니다.
- AI 보조 방사선 판독 (Radiology Assistant): 흉부 X-ray나 복부 CT에서 의사가 놓치기 쉬운 미세 병변을 선제적으로 감지하고, 초안 리포트를 작성하여 업무 효율을 극대화합니다.
- 디지털 병리 분석 (Pathology Workflow): 기가픽셀급 해상도의 병리 슬라이드를 분석하여 암세포의 침윤 정도나 등급을 판정하는 데 기여합니다. MedXIAOHE의 Native-resolution 처리는 이 분야에서 혁신적입니다.
- 다학제적 진단 에이전트 (Diagnostic Agent): 환자의 이전 진료 기록, 유전자 데이터, 의료 영상을 종합적으로 분석하여 최적의 치료 경로를 제안하는 에이전트 역할을 수행합니다.
- 교육 및 수련: 주니어 의사들이나 의대생들이 복잡한 케이스에 대해 AI와 대화하며 추론 과정을 학습하는 도구로 활용될 수 있습니다.
8. 한계점 및 기술적 비평 (Discussion & Critique)
본 저자는 MedXIAOHE의 성과를 높게 평가하면서도, 몇 가지 비판적 시각을 견지할 필요가 있다고 생각합니다.
- 데이터 편향의 잔재: 비록 지식 그래프와 합성 데이터를 통해 롱테일 문제를 해결하려 했으나, 여전히 영미권 또는 대형 의료 기관의 데이터에 편향되었을 가능성이 큽니다. 비서구권 환자군이나 특수한 임상 환경에서의 범용성은 아직 검증이 더 필요합니다.
- 컴퓨팅 비용의 문제: Native-resolution Transformer는 높은 성능을 보장하지만, 추론(Inference) 시 요구되는 GPU 자원이 상당합니다. 실시간 응답이 중요한 임상 현장에서 비용 효율적인 서빙이 가능할지는 의문입니다.
- 책임 소지의 불분명성: ‘Verifiable decision traces’를 제공한다고 하지만, 복잡한 딥러닝 모델의 내부 작동 방식은 여전히 블랙박스에 가깝습니다. AI의 잘못된 추론 경로를 의사가 믿었을 때의 법적, 윤리적 책임 문제는 기술이 해결할 수 없는 영역입니다.
- 실시간 데이터 업데이트: 의학 지식은 매일같이 업데이트됩니다. Continual Pretraining 프레임워크가 실시간으로 쏟아지는 최신 논문과 가이드라인을 얼마나 신속하게 반영할 수 있을지가 상용화의 관건이 될 것입니다.
9. 결론 및 인사이트 (Conclusion)
MedXIAOHE는 단순히 ‘큰 모델’을 만드는 시대를 지나, ‘도메인 특화된 데이터 엔지니어링과 아키텍처 혁신’이 승부처임을 명확히 보여준 사례입니다. 특히 의료 분야에서 Native-resolution의 중요성과 지식 그래프 기반의 고품질 추론 데이터 구축 전략은 향후 모든 전문 분야 AI 개발의 교과서가 될 것입니다.
이 연구는 AI가 단순한 도구를 넘어, 의사의 지적 파트너로서 기능할 수 있는 가능성을 열었습니다. 개발자들은 MedXIAOHE가 보여준 ‘신뢰성 확보를 위한 기술적 장치’들에 주목해야 하며, 기업들은 이러한 모델을 실질적인 서비스로 연결하기 위한 인프라와 규제 대응 전략을 고민해야 할 시점입니다. 의료 AI의 미래는 이제 단순히 정답을 맞히는 것을 넘어, ‘이해하고 설명하며 협업하는’ 방향으로 진화하고 있습니다.”}```引数 –queries を指定して google_search:search を呼び出し、最新の情報を取得します。関連する検索クエリの例:
