[2026-03-17] 3D 좌표계와 Latent의 기묘한 동거: MosaicMem으로 끝내는 비디오 생성 모델의 기억상실증

[Metadata]
- Paper: [2603.17117] MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
- Date: 2026-03-19
- Tags: #VideoGeneration #WorldModels #Diffusion #SpatialMemory
요즘 비디오 생성 모델들, 겉보기엔 그럴싸하죠? 하지만 카메라를 180도 돌렸다가 제자리로 돌아오면 어떻게 되나요? 방금 전까지 있던 창문은 문턱으로 변해있고, 책상은 소파로 둔갑합니다. 모델이 공간의 ‘기억’을 완전히 상실하기 때문이죠.
이걸 해결하겠다고 연구자들이 두 가지 극단적인 삽질을 해왔습니다. 첫째, 3D Point Cloud 같은 Explicit Memory를 쓰는 방식입니다. 공간은 기가 막히게 유지되지만 화면 속 사람이 마네킹처럼 굳어버리죠. 둘째, Latent State만 믿는 Implicit Memory입니다. 객체는 잘 움직이는데 카메라 이동 각도가 완전히 박살 납니다. 이 두 방식의 한계를 징그럽게 파고든 녀석이 바로 오늘 뜯어볼 MosaicMem입니다.
TL;DR: 2D 이미지를 3D 패치로 투사해 메모리에 저장하고, 새로운 시점에서 패치들을 모자이크처럼 기워 붙여 Diffusion의 조건부 입력으로 던지는 끔찍하게 영리한 하이브리드 파이프라인.
⚙️ 2D 픽셀을 3D 좌표계에 박아넣는 모자이크 연성진
이 모델의 핵심은 이름 그대로 패치를 뜯어서 3D 공간에 모자이크처럼 재배치하는 겁니다. 기존처럼 무식하게 전체 공간을 3D 렌더링으로 돌리지 않아요. 아주 정교한 ‘Patch-and-Compose’ 인터페이스를 설계했습니다.
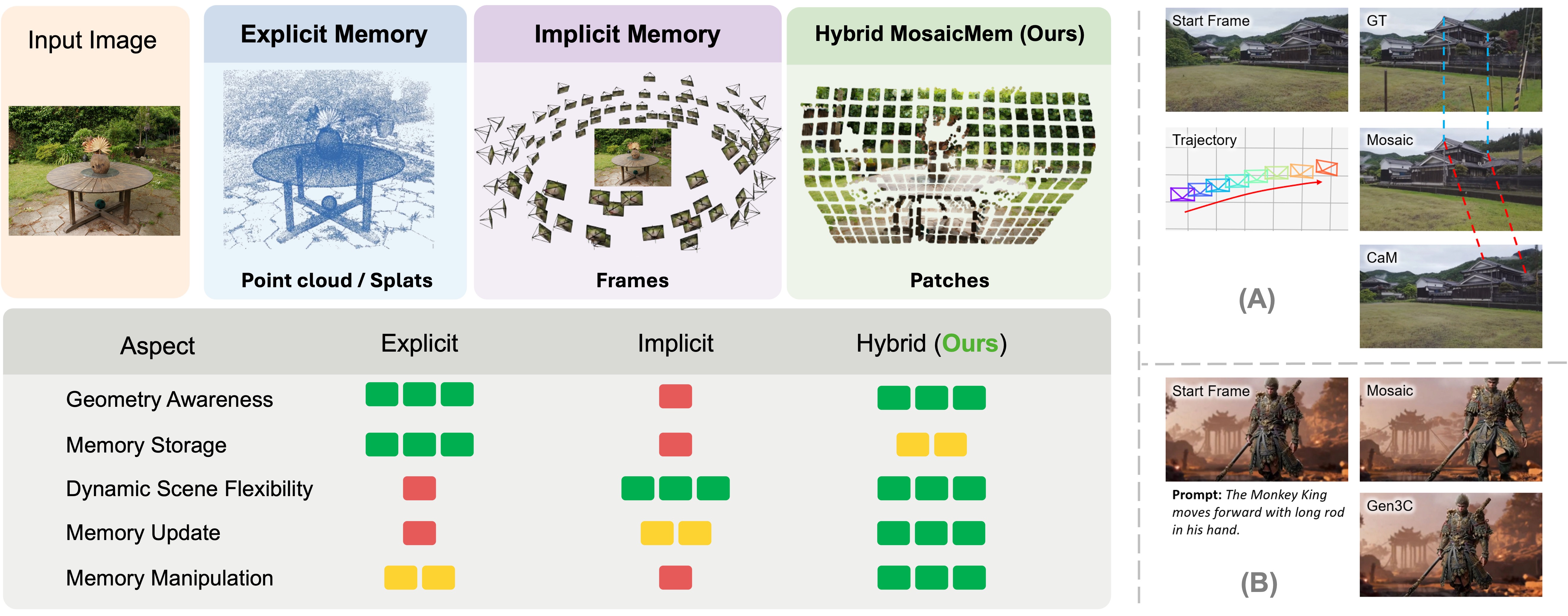 그림 1: Explicit 3D의 경직성과 Implicit Latent의 환각을 정확히 섞어놓은 구조입니다. 정적 배경은 3D로 유지하고, 동적 객체는 Diffusion이 유연하게 그리게 만듭니다.
그림 1: Explicit 3D의 경직성과 Implicit Latent의 환각을 정확히 섞어놓은 구조입니다. 정적 배경은 3D로 유지하고, 동적 객체는 Diffusion이 유연하게 그리게 만듭니다.
작동 방식은 크게 3단계의 데이터 파이프라인을 거치게 됩니다. 내부 로직이 생각보다 훨씬 우아합니다.
🔹 Lift to 3D (공간화): 현재 프레임의 이미지 패치들을 뎁스(Depth) 맵과 카메라 포즈를 이용해 3D 공간 좌표로 통째로 끌어올립니다. 🔹 Retrieve & Warp (타겟 시점 렌더링): 다음 생성할 프레임의 새로운 카메라 시점에서, 아까 저장해둔 3D 패치들을 불러옵니다(Retrieval). 이때 발생하는 미세한 픽셀 정렬 오차는 Warping을 통해 물리적으로 찌그러뜨려 맞춥니다. 🔹 Concatenation with PRoPE: 이렇게 타겟 시점에 맞게 조합된 ‘모자이크 패치’를 납작하게 펴서 기존 토큰 시퀀스에 이어 붙입니다.
이해를 돕기 위해 이 파이프라인이 코드 레벨에서 어떻게 돌아갈지 추상화해 봅시다. 내부 로직은 정확히 이 데이터 흐름을 탑니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# MosaicMem Core Pipeline (Mock Pseudo-Code)
class MosaicMemPipeline:
def __init__(self, diffusion_model):
self.spatial_memory = PointCloudDB() # 3D lifted patches
self.model = diffusion_model
def forward(self, current_frame, target_pose, prompt):
# 1. Lift and Store (Cache the world)
depth_map = estimate_depth(current_frame)
patches_3d = lift_to_3d(current_frame, depth_map)
self.spatial_memory.update(patches_3d)
# 2. Retrieve for Target View (Query the camera)
raw_mosaic = self.spatial_memory.query_view(target_pose)
# 3. Align & Warp (Crucial for eliminating artifacts)
aligned_mosaic = warp_to_fix_alignment(raw_mosaic, target_pose)
# 4. Inject into Diffusion with PRoPE conditioning
cond_tokens = flatten_and_concat(aligned_mosaic)
output = self.model.generate(
prompt=prompt,
camera_cond=PRoPE(target_pose),
memory_cond=cond_tokens
)
return output
이게 진짜 무서운 점은 모델을 처음부터 다시 학습시킬 필요 없이(Training-free) 메모리 주입만으로도 어느 정도 돌아간다는 겁니다. 공간적 일관성은 메모리에서 뼈대를 잡아주고, 비어있는 픽셀을 채우는 건 Diffusion 본연의 Inpainting 능력을 100% 믿고 맡기는 방식이죠.
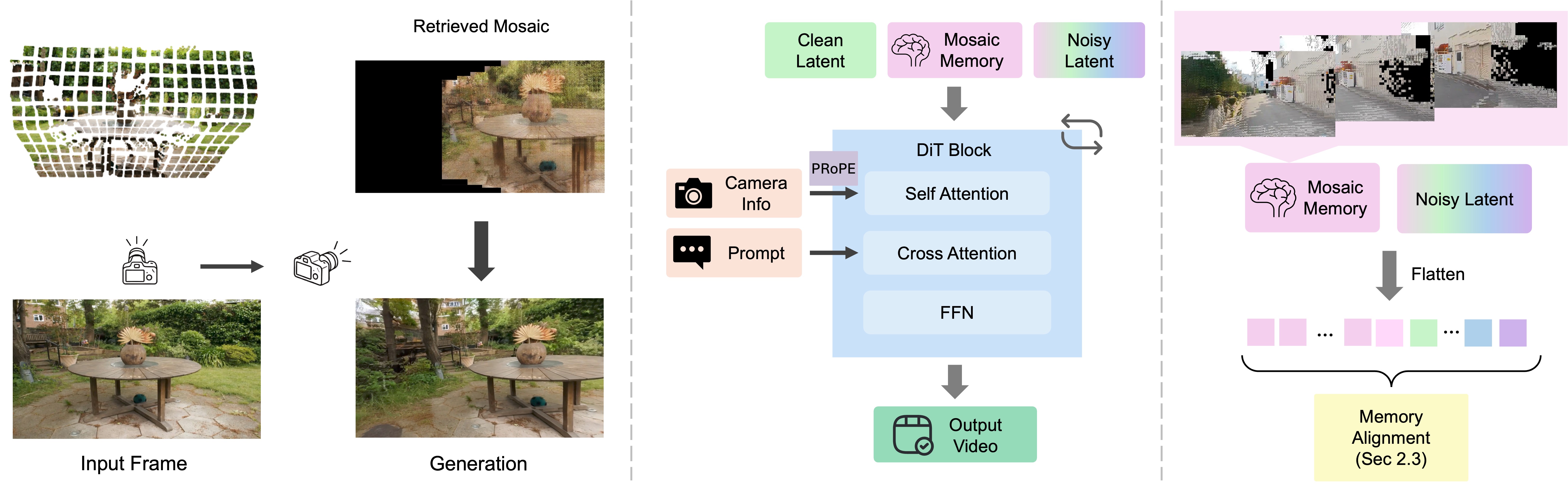 그림 2: 타겟 시점에서 추출된 모자이크 패치들이 토큰 시퀀스에 직접 결합되는 아키텍처 흐름도입니다. 빈틈을 모델이 스스로 채우는 데이터 플로우가 핵심입니다.
그림 2: 타겟 시점에서 추출된 모자이크 패치들이 토큰 시퀀스에 직접 결합되는 아키텍처 흐름도입니다. 빈틈을 모델이 스스로 채우는 데이터 플로우가 핵심입니다.
 그림 3: 파인튜닝 없이 기존 모델에 메모리 조건만 들이부어도, 공간의 뼈대가 유지된 채로 텍스처만 살짝 다듬어지는 무서운 결과를 보여줍니다.
그림 3: 파인튜닝 없이 기존 모델에 메모리 조건만 들이부어도, 공간의 뼈대가 유지된 채로 텍스처만 살짝 다듬어지는 무서운 결과를 보여줍니다.
⚔️ 극단적 양극화의 종말: 기존 스택 vs 새로운 패러다임
과연 이 복잡한 파이프라인을 구축할 가치가 있을까요? 기존의 SOTA(State-of-the-Art) 모델들과 스펙을 대조해 보면 이 녀석이 어느 포지션을 노리고 있는지 아주 명확해집니다.
| Metric | GEN3C (Explicit 3D) | VWM (Implicit Latent) | MosaicMem (Hybrid) |
|---|---|---|---|
| 동적 객체 처리 | 불가능 (배경과 함께 굳어버림) | 가능 (단, 모션 붕괴 잦음) | 가능 + 배경 일관성 유지 |
| 카메라 제어 정확도 | 매우 높음 | 낮음 (Pose 파라미터 무시) | 매우 높음 (PRoPE 활용) |
| 메모리 오버헤드 | 극악 (O(N^3) Voxel Grid) | 최소 (O(1) 고정 Latent) | 준수함 (O(N) Patch 캐싱) |
| Revisit 일관성 | 높음 (정적일 경우만) | 박살남 (금붕어 기억력) | 높음 (Patch Retrieval) |
| Setup Complexity | 극상 (NeRF/GS 렌더러 필수) | 하 (단순 API 콜 수준) | 중상 (Warping 연산 추가) |
표를 보시면 알겠지만, Explicit 방식의 장점인 장기 일관성과 Implicit 방식의 장점인 동적 객체 생성을 타협점 없이 합쳤습니다. 개발자 입장에서 가장 골치 아픈 게 “카메라가 한 바퀴 돌고 왔을 때 아까 그 사과가 그대로 있느냐” 하는 Revisit 문제죠. MosaicMem은 3D 공간에 패치를 캐싱해 두기 때문에 이 문제를 물리적으로 회피합니다.
 그림 4: GEN3C는 세상이 멈춰있고, VWM은 아티팩트가 터지지만, MosaicMem은 배경은 고정하고 피사체만 자연스럽게 움직이게 만듭니다.
그림 4: GEN3C는 세상이 멈춰있고, VWM은 아티팩트가 터지지만, MosaicMem은 배경은 고정하고 피사체만 자연스럽게 움직이게 만듭니다.
 그림 5: PRoPE라는 새로운 카메라 컨디셔닝 모듈이 빠지면 시점 변환 시 참고할 모자이크가 없을 때 렌더링이 처참하게 붕괴되는 것을 볼 수 있습니다.
그림 5: PRoPE라는 새로운 카메라 컨디셔닝 모듈이 빠지면 시점 변환 시 참고할 모자이크가 없을 때 렌더링이 처참하게 붕괴되는 것을 볼 수 있습니다.
🚀 내일 당장 프로덕션에 도입한다면?
이 녀석을 장난감이 아니라 실제 서비스 백엔드에 붙인다면 어떤 시나리오가 가능할까요? 현실적인 병목 현상과 함께 두 가지를 꼽아봤습니다.
1. 분 단위(Minute-level) 무한 맵 탐험 버추얼 투어 현재 생성형 AI로 방 안을 돌아다니는 영상을 만들면, 거실에서 주방으로 갔다가 다시 오면 인테리어가 바뀌어 있습니다. MosaicMem을 공간 캐싱 DB와 연결하면, 유저의 카메라 조작에 따라 완전히 일관된 롱테이크 버추얼 투어가 가능해집니다. 🚨 Bottleneck: 문제는 사용자가 모델이 한 번도 보지 못한 극단적인 사각지대(예: 소파 밑동)로 카메라를 쑤셔 넣을 때입니다. PRoPE가 없다면 이전 패치 데이터가 없어서 모델이 심각한 환각을 일으킬 수 있습니다. 추론 시점의 VRAM 캐시 터지는 소리가 벌써 들리네요.
2. 메모리 기반의 타겟팅 비디오 씬 에디팅 (Scene Editing) 기존 비디오 편집 모델은 프롬프트로 “배경에 강아지를 추가해 줘”라고 하면 전체 영상의 톤앤매너가 미세하게 흔들립니다. 하지만 MosaicMem은 특정 3D 좌표에 해당하는 메모리 패치만 교체해서 모델에 다시 먹일 수 있죠. 나머지 영역의 픽셀은 완벽하게 보존하면서요. 🚨 Bottleneck: 뎁스(Depth) 추정과 Warping 연산이 프레임 단위로 무겁게 들어가야 합니다. 실시간(Real-time) 렌더링은 현재의 H100 GPU 한두 장으로는 어림도 없습니다. 비동기 배치 처리 파이프라인으로 빼야만 프로덕션 레벨의 레이턴시를 맞출 수 있을 겁니다.
🧐 Tech Lead’s Honest Verdict
자, 이제 뽕을 좀 빼고 차갑게 아키텍처를 평가해 보죠.
👍 Pros (이건 진짜 훌륭하다):
- Patch-and-Compose 아키텍처: 무거운 3D 렌더링 엔진을 통째로 올리는 대신, 타겟 시점의 패치만 뜯어서 Diffusion의 토큰으로 던지는 발상은 아키텍처적으로 매우 우아하고 경제적입니다.
- PRoPE 컨디셔닝의 재발견: 기존 Implicit 모델들이 카메라 포즈 파라미터를 얼마나 대충 씹어먹었는지 뼈저리게 반성하게 만드는 강력한 통제력을 보여줍니다.
👎 Cons (현실은 녹록지 않다):
- 파이프라인 복잡도 폭발: 뎁스 뽑고, 3D로 올리고, 카메라 포즈 맞춰서 쿼리하고, Warping까지 해야 합니다. 엔지니어링 실패 포인트(SPOF)가 너무 많아서 인프라 터지기 딱 좋은 끔찍한 연쇄 구조입니다.
- 누적 오차(Drift) 문제: 긴 비디오를 생성할 때 뎁스 추정이 1%만 어긋나도, 3D 메모리에 노이즈가 복리로 쌓입니다. 결국 후반부 프레임이 지저분해질 물리적 위험이 큽니다.
🔥 Final Verdict: "사내 토이 프로젝트나 R&D 용으로 즉시 Clone 하세요. 단, 실시간 B2C 서비스 도입은 최적화가 끝난 v2를 기다리는 게 정신 건강에 좋습니다."
아이디어 자체는 현재 비디오 월드 모델이 뚫어야 할 가장 정확한 혈을 짚었습니다. 영상 생성의 지독한 일관성 문제로 밤새워본 엔지니어라면, 이 하이브리드 파이프라인의 코드는 반드시 한 번 뜯어보고 넘어가야 합니다.
