[2026-02-04] OmniSIFT: 모달리티 비대칭형 토큰 압축으로 Omni-modal LLM의 효율성과 성능을 동시에 잡다

OmniSIFT: 모달리티 비대칭형 토큰 압축으로 Omni-modal LLM의 효율성을 재정의하다
최근 인공지능 연구의 최전선은 텍스트를 넘어 오디오와 비디오를 동시에 이해하고 생성하는 Omni-modal Large Language Models (Omni-LLMs)로 빠르게 이동하고 있습니다. Qwen2.5-Omni, GPT-4o와 같은 모델들은 인간에 가까운 멀티모달 추론 능력을 보여주지만, 한 가지 치명적인 병목 현상에 직면해 있습니다. 바로 ‘토큰 폭발(Token Explosion)’ 문제입니다. 비디오와 오디오 데이터가 결합될 때 발생하는 수만 개의 토큰은 LLM의 연산 비용을 기하급수적으로 증가시키고, 실시간 응답성을 저해합니다.
오늘 소개할 연구인 “OmniSIFT: Modality-Asymmetric Token Compression for Efficient Omni-modal Large Language Models”는 이 문제를 해결하기 위해 기존의 대칭적 압축 방식에서 벗어나, 시각 정보를 기반으로 청각 정보를 선별하는 비대칭형 압축(Modality-Asymmetric Compression)이라는 혁신적인 패러다임을 제시합니다.
1. 핵심 요약 (Executive Summary)
OmniSIFT(Omni-modal Spatio-temporal Informed Fine-grained Token compression)는 Omni-LLM의 효율성을 극대화하기 위해 설계된 2단계 토큰 압축 프레임워크입니다.
- 비대칭적 접근: 비디오와 오디오를 동일하게 처리하는 대신, 비디오의 시공간적 중복성을 먼저 제거하고 이를 ‘앵커(Anchor)’로 삼아 관련 있는 오디오 토큰을 선별합니다.
- 압도적인 효율성: 단 4.85M개의 추가 파라미터만으로 전체 토큰의 75%를 제거하면서도, Full-token 모델과 대등하거나 오히려 이를 능가하는 성능을 기록했습니다.
- 미분 가능한 최적화: Straight-Through Estimator(STE)를 통해 토큰 선택 과정을 엔드투엔드(End-to-End)로 학습 가능하게 만들었습니다.
- 검증된 성능: 5개의 주요 벤치마크에서 기존의 학습 기반(Learning-based) 및 비학습 기반(Training-free) 압축 기법들을 모두 압도했습니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
Omni-LLM의 그림자: 계산 복잡도
Omni-LLM은 비디오 프레임과 오디오 샘플을 각각 수백, 수천 개의 토큰으로 변환합니다. 예를 들어, 1분 내외의 짧은 영상이라도 초당 프레임 수와 오디오 샘플링 레이트를 고려하면 LLM이 처리해야 할 컨텍스트 길이는 금세 수천 단계를 넘어섭니다. LLM의 Self-attention 메커니즘이 시퀀스 길이에 대해 이차 복잡도(Quadratic Complexity)를 가진다는 점을 고려할 때, 이는 곧 추론 지연 시간(Latency)과 메모리 점유율(Memory Footprint)의 폭증으로 이어집니다.
기존 토큰 압축 기술의 한계
기존의 토큰 압축 연구들은 크게 두 가지 한계를 가집니다.
- 모달리티 분리형(Modality-decoupled): 시각과 청각을 각각 독립적으로 압축합니다. 이는 두 정보 사이의 긴밀한 상관관계를 무시합니다.
- 모달리티 대칭형(Modality-symmetric): 두 정보를 동일한 비중으로 처리합니다. 하지만 실제 동영상 데이터에서 정보의 밀도는 시각과 청각이 서로 다르며, 특정 상황에서는 시각 정보가 청각 정보의 중요도를 결정하는 지표가 되기도 합니다.
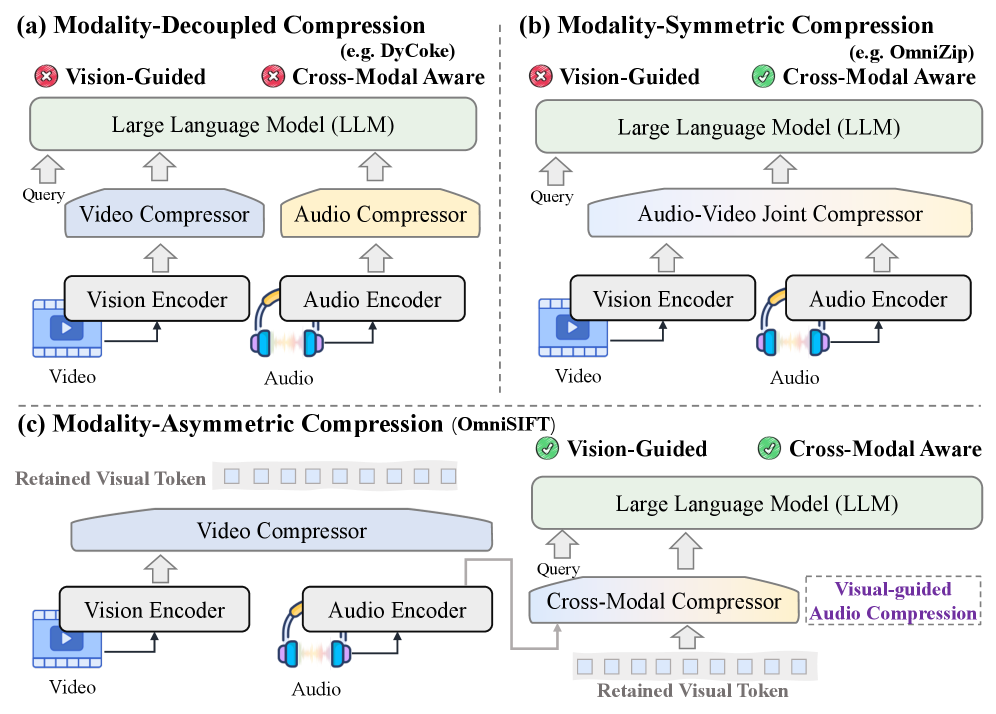 그림 1: Omni-LLM을 위한 압축 패러다임 비교. (a) 분리형, (b) 대칭형, (c) OmniSIFT가 제안하는 비대칭형.
그림 1: Omni-LLM을 위한 압축 패러다임 비교. (a) 분리형, (b) 대칭형, (c) OmniSIFT가 제안하는 비대칭형.
위 그림에서 볼 수 있듯이, OmniSIFT는 비디오를 먼저 압축하여 핵심 시각 정보를 추출하고, 이를 가이드 삼아 오디오를 압축하는 비대칭적 경로를 선택했습니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
OmniSIFT의 아키텍처는 크게 STVP(시공간 비디오 프루닝)와 VGAS(시각 가이드 오디오 선택)의 두 단계로 구성됩니다.
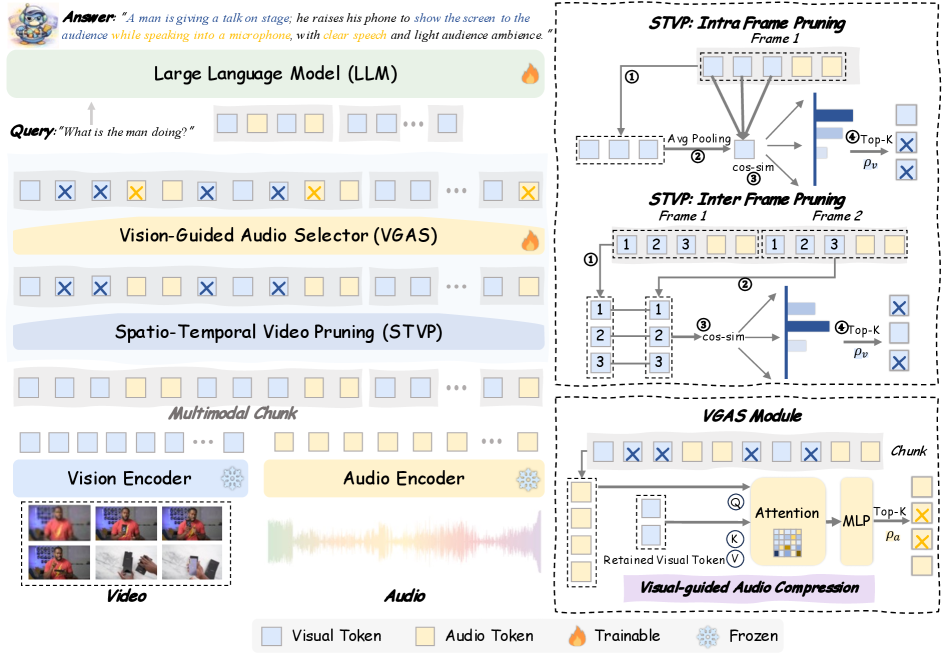 그림 2: OmniSIFT의 전체 아키텍처. 시공간적 중복성을 제거한 후 비각 정보를 앵커로 활용해 오디오를 선택하는 과정을 보여줍니다.
그림 2: OmniSIFT의 전체 아키텍처. 시공간적 중복성을 제거한 후 비각 정보를 앵커로 활용해 오디오를 선택하는 과정을 보여줍니다.
3.1. STVP: Spatio-temporal Video Pruning
비디오 데이터는 두 가지 차원에서 중복성을 가집니다. 첫째는 프레임 내의 배경 등 정적인 부분(공간적 중복), 둘째는 인접한 프레임 간의 유사성(시간적 중복)입니다.
- 공간적 프루닝: 각 프레임의 패치 토큰 중 정보량이 적은 토큰을 제거합니다.
- 시간적 프루닝: 움직임이 적거나 변화가 없는 프레임 시퀀스에서 중복된 토큰을 제거합니다.
- Visual Anchors: 결과적으로 남은 소수의 고밀도 토큰들은 해당 비디오의 핵심 사건을 대표하는 ‘비주얼 앵커’ 역할을 하게 됩니다.
3.2. VGAS: Vision-guided Audio Selection
이 연구의 가장 독창적인 부분입니다. 단순히 오디오 신호 자체의 세기나 주파수만을 보는 것이 아니라, 앞서 추출된 비주얼 앵커와의 상관관계를 계산합니다.
- Cross-modal Attention: 비디오 토큰을 Query로, 오디오 토큰을 Key/Value로 사용하여 시각적으로 중요한 시점에 발생하는 청각 정보에 더 높은 가중치를 부여합니다.
- 현실적 타당성: 우리가 스포츠 경기를 볼 때, 골을 넣는 ‘장면’에 맞춰 터져 나오는 ‘함성’이 중요한 것과 같은 이치입니다. OmniSIFT는 이 메커니즘을 수학적으로 모델링했습니다.
3.3. Differentiable Compression (STE)
토큰을 ‘선택’하거나 ‘버리는’ 행위는 기본적으로 불연속적(Discrete)이어서 미분이 불가능합니다. OmniSIFT는 Straight-Through Estimator(STE)를 도입하여, 순전파(Forward) 시에는 하드 임계값을 적용해 토큰을 선택하고, 역전파(Backward) 시에는 그라디언트가 흐를 수 있도록 설계하여 모델 전체가 압축 효율을 극대화하는 방향으로 학습되도록 했습니다.
4. 성능 평가 및 비교 (Comparative Analysis)
연구진은 Qwen2.5-Omni-7B 모델을 백본으로 하여 다섯 가지 벤치마크(WorldSense, Video-MME, EgoSchema 등)에서 실험을 진행했습니다.
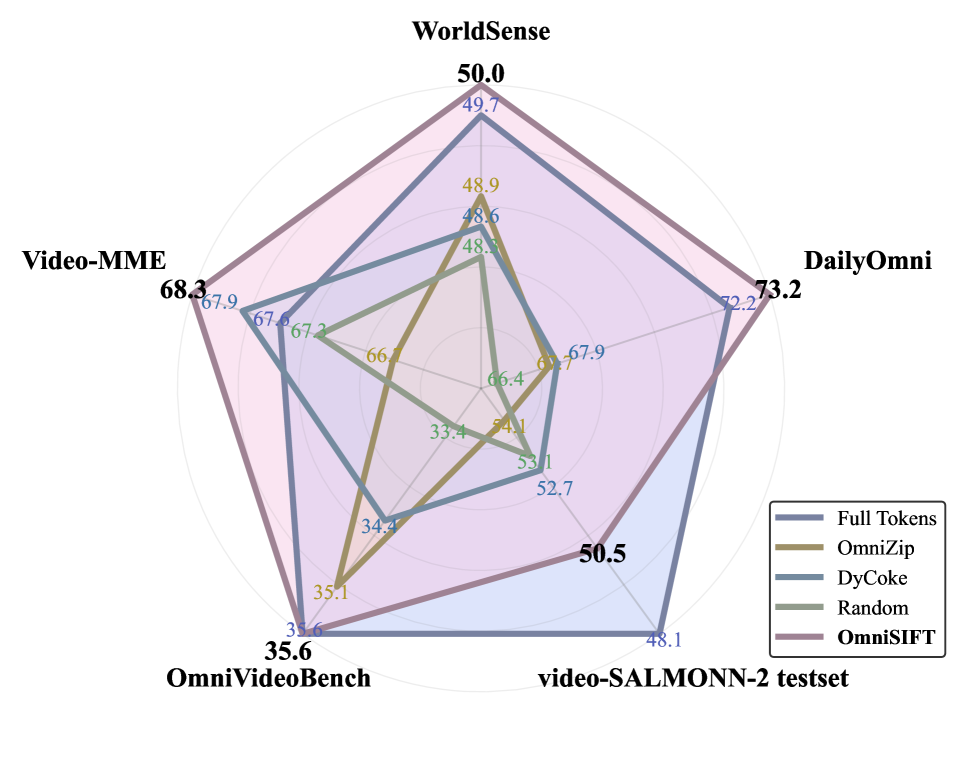 그림 3: 5개 벤치마크에서의 성능 비교. OmniSIFT는 35%의 토큰만 사용하고도 Full-token 모델을 능가하는 성적을 거두었습니다.
그림 3: 5개 벤치마크에서의 성능 비교. OmniSIFT는 35%의 토큰만 사용하고도 Full-token 모델을 능가하는 성적을 거두었습니다.
주목할 만한 결과
- 압축률 대비 성능: 토큰의 75%를 제거(Retention Ratio 25%)했음에도 불구하고, Video-MME와 같은 고난도 벤치마크에서 Full-token 모델보다 높은 점수를 기록했습니다. 이는 불필요한 노이즈 토큰이 제거됨으로써 LLM의 집중력이 오히려 향상되었음을 시사합니다.
- 경량화: 추가되는 파라미터는 4.85M에 불과합니다. 이는 7B 모델 전체 파라미터의 약 0.07% 수준으로, 매우 경제적인 튜닝이 가능함을 보여줍니다.
- 지연 시간 단축: 비학습 기반인 OmniZip보다도 낮은 Latency를 기록하며 실시간 서비스 가능성을 입증했습니다.
 그림 4: 비디오(좌) 및 오디오(우) 압축률 변화에 따른 성능 변화. 특정 지점까지는 압축을 할수록 오히려 성능이 상승하는 구간이 발견됩니다.
그림 4: 비디오(좌) 및 오디오(우) 압축률 변화에 따른 성능 변화. 특정 지점까지는 압축을 할수록 오히려 성능이 상승하는 구간이 발견됩니다.
5. 실제 적용 분야 및 글로벌 파급력 (Real-World Application)
Senior AI Scientist로서 저는 OmniSIFT가 다음과 같은 실제 산업 현장에서 ‘게임 체인저’가 될 것이라 확신합니다.
- 지능형 CCTV 및 보안 시스템: 수시간 분량의 보안 영상을 실시간으로 분석할 때, 모든 토큰을 처리하는 것은 불가능합니다. OmniSIFT의 시공간 프루닝은 침입이나 사고와 같은 ‘사건’ 중심의 토큰만을 남겨 서버 비용을 80% 이상 절감할 수 있습니다.
- 자율주행 자동차의 센서 퓨전: 시각(카메라)과 청각(사이렌 소리 등) 정보를 결합해야 하는 자율주행 환경에서, 중요도가 낮은 배경 데이터를 즉각 쳐내고 핵심 위험 요소에 연산을 집중할 수 있게 합니다.
- 개인용 AI 에이전트(스마트 글래스): 기기 자체의 연산 능력이 제한적인 온디바이스 AI 환경에서, 효율적인 토큰 압축은 배터리 수명 연장과 빠른 응답 속도를 보장하는 핵심 기술입니다.
- 대규모 영상 아카이브 검색: YouTube나 Netflix 같은 플랫폼에서 영상의 내용을 정교하게 검색할 때, 인덱싱 비용을 획기적으로 낮출 수 있습니다.
6. 한계점 및 기술적 비평 (Discussion & Critique)
물론 모든 기술에는 이면이 있습니다. OmniSIFT의 논리 구조에서 비판적으로 살펴볼 지점은 다음과 같습니다.
- 시각 정보 편향성 (Visual Dominance Bias): OmniSIFT는 비디오를 가이드로 오디오를 선택합니다. 하지만 ‘화면 밖에서 들려오는 목소리’나 ‘어두운 밤 중의 소리’처럼 오디오가 주된 정보를 담고 있는 경우, 시각 앵커가 오디오의 중요도를 잘못 판단할 위험이 있습니다. 실험 결과에서도 오디오 압축률이 지나치게 높을 때 성능 하락이 발생하는 것이 관찰되었습니다.
- STE의 불안정성: Straight-Through Estimator는 학습 과정에서 그라디언트 불일치(Gradient Mismatch) 문제를 야기할 수 있습니다. 보다 정교한 Gumbel-Softmax 등의 기법과 비교 분석이 부족한 점은 아쉽습니다.
- 벤치마크의 한계: 현재의 벤치마크들은 대부분 짧은 클립 위주입니다. 수십 분에서 수 시간 단위의 롱-폼(Long-form) 컨텐츠에서도 OmniSIFT의 비대칭적 선택 로직이 여전히 유효할지는 추가 검증이 필요합니다.
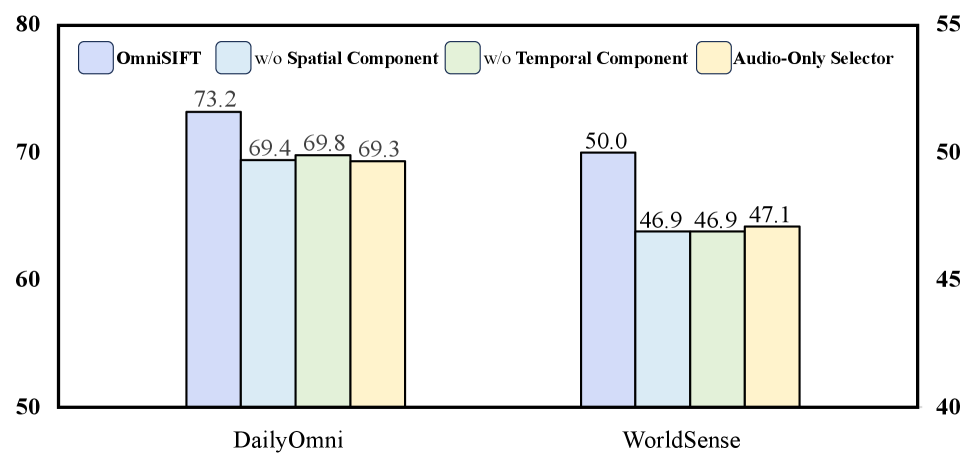 그림 5: 아키텍처 구성 요소별 어블레이션 연구. 시각 가이드가 없는 ‘Audio-only Selector’의 성능이 가장 낮다는 점이 이 연구의 핵심 논리를 뒷받침합니다.
그림 5: 아키텍처 구성 요소별 어블레이션 연구. 시각 가이드가 없는 ‘Audio-only Selector’의 성능이 가장 낮다는 점이 이 연구의 핵심 논리를 뒷받침합니다.
7. 결론 및 인사이트 (Conclusion)
OmniSIFT는 “모든 데이터가 동등하게 중요하다”는 고정관념을 깨고, “정보의 비대칭성을 활용해 효율을 극대화한다”는 실용적인 철학을 성공적으로 구현했습니다. 특히 비디오 토큰을 앵커로 삼아 오디오를 선별하는 구조는 인간의 인지 체계와도 닮아 있어 설득력이 높습니다.
이 연구는 단순한 성능 개선을 넘어, 앞으로 나올 Omni-LLM들이 거대해지는 모델 사이즈에 대응하기 위해 어떤 ‘다이어트’를 거쳐야 하는지에 대한 명확한 이정표를 제시하고 있습니다. 토큰 압축은 이제 선택이 아닌 필수이며, OmniSIFT는 그 중에서도 가장 선구적인 해결책 중 하나로 자리매김할 것입니다.
전문가 의견: 향후 연구는 시각이 오디오를 가이드 하는 것을 넘어, 두 모달리티가 서로의 중요도를 상호 보완적으로 평가하는 ‘상호 가이드형(Mutually-guided)’ 구조로 발전할 것으로 보입니다. OmniSIFT는 그 여정의 강력한 출발점입니다.
