[2026-03-26] 5초 학습해서 120초 뽑는다고? KV 캐시의 저주를 푼 PackForcing 기술 해부

비디오 생성 모델, 5초 넘어가면 VRAM 박살나는 거 저만 겪었나요?
비디오 생성 AI 하시는 분들, 다들 아시죠? 처음 2~3초는 그럴싸하게 나오다가 10초 넘어가면 슬슬 KV Cache가 메모리를 다 잡아먹고, 어느 순간 영상이 무한 반복되거나 주인공 얼굴이 괴물로 변하는 그 끔찍한 경험 말입니다. 자율 주행 데이터셋이나 긴 튜토리얼 영상을 만들고 싶은데, 현실은 H100 수십 대를 이어 붙여도 선형적으로 늘어나는 컨텍스트 길이를 감당할 수 없었거든요.
그런데 이번에 등장한 PackForcing은 좀 다릅니다. 고작 5초짜리 짧은 영상으로 학습했는데, 추론할 때는 120초(2분)짜리 일관성 있는 영상을 뽑아냅니다. 그것도 단 한 장의 GPU(H200 기준)에서 KV 캐시를 단 4GB로 묶어둔 채로요. 도대체 어떤 마법을 부렸길래 24배나 되는 템포럴 엑스트라폴레이션(Temporal Extrapolation)이 가능한 건지, 코드를 뜯어보는 느낌으로 딥하게 파헤쳐 보죠.
한 줄 요약: KV 캐시를 Sink(앵커), Mid(32x 압축), Recent(로컬) 세 부분으로 쪼개고, 중요도 낮은 ‘중간 과거’를 실시간으로 갖다 버리면서 메모리 폭주를 막는 역대급 효율의 프레임워크입니다.
⚙️ 3단 분리 KV 관리: 메모리 다이어트의 핵심 파이프라인
PackForcing의 핵심은 Three-Partition KV Management입니다. 모든 과거 프레임을 다 들고 있는 게 아니라, 인간의 기억력처럼 전략적으로 정보를 보존합니다.
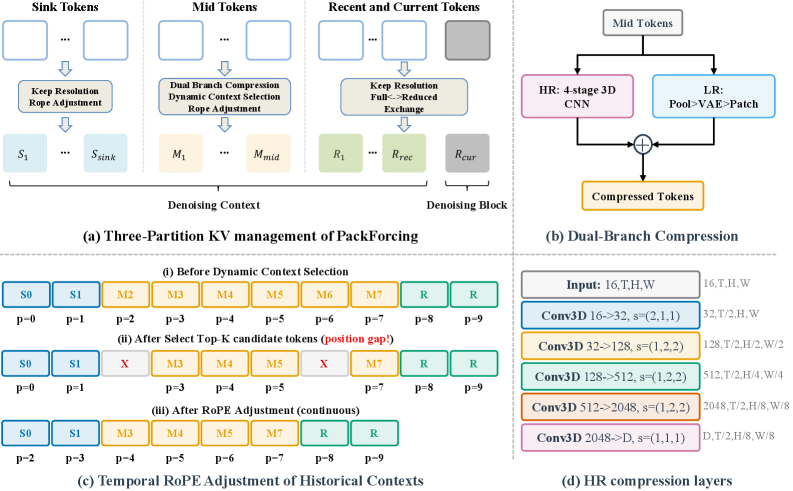 이 다이어그램은 PackForcing이 어떻게 컨텍스트를 계층적으로 압축하고, RoPE를 통해 위치 정보를 재정렬하는지 보여주는 기술적 청사진입니다.
이 다이어그램은 PackForcing이 어떻게 컨텍스트를 계층적으로 압축하고, RoPE를 통해 위치 정보를 재정렬하는지 보여주는 기술적 청사진입니다.
- Sink Tokens (고정 앵커): 영상의 극초반 프레임입니다. 왜 이걸 들고 있냐고요? 초반의 분위기와 주인공 설정을 잊어버리면 영상이 산으로 가거든요. 전체 해상도로 유지합니다.
- Mid Tokens (초압축 과거): 여기가 기술의 정수입니다. Dual-branch compression을 통해 토큰 수를 32배로 줄입니다. 3D CNN으로 시공간 특징을 뽑고, 저해상도 VAE로 다시 인코딩해서 합치는 방식이죠.
- Recent Tokens (쌩쌩한 현재): 바로 직전 프레임들입니다. 템포럴 일관성을 위해 압축 없이 그대로 유지합니다.
여기서 재미있는 건 Dynamic Top-K Context Selection입니다. 압축된 Mid 토큰 중에서도 ‘현재 프레임 생성에 도움 안 되는 놈’들은 과감히 버립니다. 아래는 이 과정을 구현할 때의 핵심 로직을 추상화한 코드입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class PackForcingKVManager:
def __init__(self, k_bound=1024, compression_ratio=32):
self.k_bound = k_bound
self.compressor = DualBranchCompressor(ratio=compression_ratio)
def update_kv_cache(self, current_kv, history_kv):
# 1. Recent 토큰은 그대로 유지
recent = current_kv[:, -RECENT_SIZE:]
# 2. 오래된 토큰은 Dual-branch로 32배 압축
compressed_mid = self.compressor.encode(history_kv)
# 3. Dynamic Top-K Selection: 어텐션 스코어 기반으로 중요 토큰만 선별
# 메모리 상한선(k_bound)을 절대 넘지 않게 조절
scores = torch.matmul(query, compressed_mid.transpose(-1, -2))
topk_indices = scores.mean(dim=1).topk(self.k_bound).indices
selected_mid = compressed_mid.gather(index=topk_indices)
# 4. Temporal RoPE Adjustment: 토큰이 빠진 자리를 메꾸기 위해 포지션 인덱스 재정렬
adjusted_kv = apply_temporal_rope(selected_mid, topk_indices)
return torch.cat([sink, adjusted_kv, recent], dim=1)
이 과정에서 발생하는 ‘위치 인덱스 구멍’ 문제는 Temporal RoPE Adjustment로 해결합니다. 토큰을 중간중간 버리면 타임스탬프가 꼬이는데, 이를 연속적인 인덱스로 강제 매핑해서 어텐션 메커니즘이 혼란에 빠지지 않게 만듭니다.
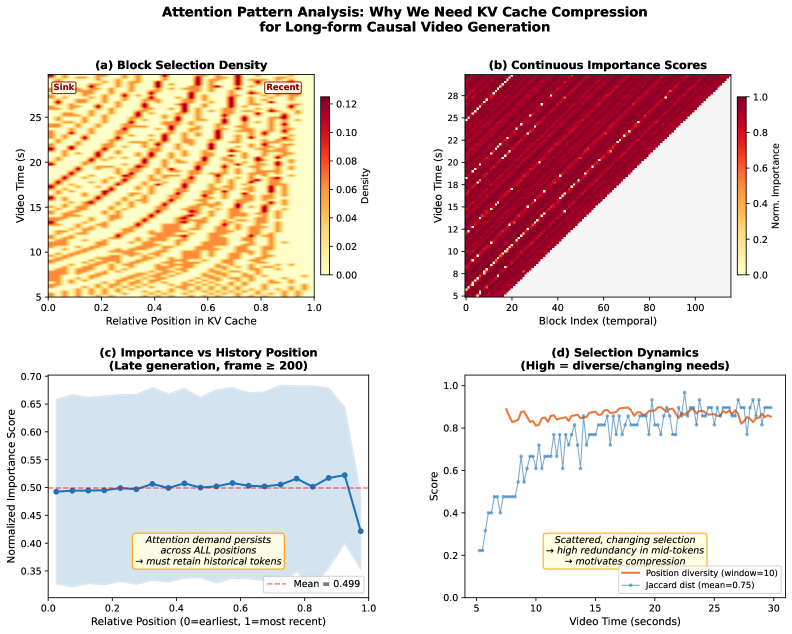 어텐션 밀도 맵과 중요도 점수를 보면, FIFO 방식으로 단순히 오래된 걸 버리는 게 얼마나 멍청한 짓인지(c번 지표 참고) 데이터가 말해주고 있습니다.
어텐션 밀도 맵과 중요도 점수를 보면, FIFO 방식으로 단순히 오래된 걸 버리는 게 얼마나 멍청한 짓인지(c번 지표 참고) 데이터가 말해주고 있습니다.
⚔️ 기존 스택 vs PackForcing: 진짜 갈아탈 가치가 있나?
기존의 Rolling-Forcing이나 DeepForcing 같은 방식들은 컨텍스트가 길어질수록 화질이 뭉개지거나, 결정적으로 KV 캐시가 무한정 늘어나는 문제를 해결 못 했습니다. PackForcing은 이걸 수학적으로 닫힌(Bounded) 메모리 구조로 바꿨습니다.
| 비교 항목 | Rolling-Forcing | DeepForcing | PackForcing (Ours) |
|---|---|---|---|
| KV Cache 메모리 사용량 | 선형 증가 (O(N)) | 고정 (High VRAM) | 고정 (Low, ~4GB) |
| 최대 생성 길이 (16 FPS) | ~20s (품질 저하) | ~60s | 120s+ (Stable) |
| 학습 데이터 요구량 | 긴 영상 필수 | 긴 영상 필수 | 5초 내외 짧은 영상만으로 충분 |
| VBench 일관성 점수 | 22.45 | 24.12 | 26.07 (SOTA) |
| 추론 속도 (H200) | 컨텍스트 길수록 급감 | 일정하지만 느림 | 일정하고 빠름 |
솔직히 수치만 봐도 압권입니다. 특히 5초 학습으로 120초를 생성한다는 건, 데이터셋 구축 비용을 수십 배 아낄 수 있다는 뜻이죠.
 120초 지점의 결과물을 보세요. Self-Forcing은 이미 형태를 잃었고, DeepForcing은 주인공이 사라졌습니다. PackForcing만 끝까지 버티죠.
120초 지점의 결과물을 보세요. Self-Forcing은 이미 형태를 잃었고, DeepForcing은 주인공이 사라졌습니다. PackForcing만 끝까지 버티죠.
🚀 내일 당장 프로덕션에 도입한다면?
이 기술은 단순히 ‘연구용’으로 끝날 물건이 아닙니다. 실무적으로 소름 돋는 포인트가 두 곳 있어요.
1. ‘무한 루프’ 홍보 배너 제작 쇼핑몰이나 옥외 광고판에 쓸 1~2분짜리 고화질 루핑 비디오가 필요할 때, 기존에는 수천만 원짜리 렌더링 장비가 필요했습니다. 이제 PackForcing을 쓰면 단일 GPU 서버에서 저렴하게 ‘일관성 있는’ 롱폼 영상을 찍어낼 수 있습니다.
2. 자율 주행 시뮬레이터 데이터 증강 자율 주행 AI를 학습시키려면 수 분 이상의 연속적인 도로 주행 데이터가 필요합니다. 하지만 실제 촬영 데이터는 한계가 있죠. PackForcing의 템포럴 엑스트라폴레이션 기능을 쓰면, 짧은 사고 상황 클립을 수 분짜리 다양한 시나리오로 확장해서 엣지 케이스를 무한 생성할 수 있습니다.
⚠️ 하지만 이런 점은 주의하세요:
- 복잡한 모션의 한계: 32배 압축(Mid tokens)은 강력하지만, 아주 미세한 입자(비, 눈, 연기)의 물리적 움직임까지 완벽하게 보존하기엔 정보 손실이 있을 수 있습니다.
- 16 FPS 제약: 현재 벤치마크는 16 FPS 위주입니다. 60 FPS 이상의 초고주사율 액션 게임 영상을 만들려면 압축 알고리즘을 더 튜닝해야 할 겁니다.
🧐 Tech Lead’s Honest Verdict
“KV 캐시에 고통받던 시대의 종말을 예고하는 깔끔한 한 방”
PackForcing은 단순히 모델 사이즈를 키우는 무식한 방법 대신, ‘메모리를 어떻게 영리하게 관리할 것인가’라는 엔지니어링적 난제에 집중했습니다. 그 결과가 5초 학습-120초 생성이라는 경이로운 효율로 나타난 거고요.
- Pros: 압도적인 VRAM 효율성, 짧은 학습 데이터로도 긴 영상 가능, 템포럴 드리프트(정체성 붕괴) 해결.
- Cons: 압축 과정에서의 미세한 디테일 손실 가능성, RoPE 재정렬 로직 구현의 복잡도.
최종 판결: 비디오 생성 서비스를 준비 중이거나, 로컬에서 롱폼 영상을 뽑고 싶은 해커라면 지금 당장 Github 클론하세요. 이건 논문으로만 남기기엔 너무 아까운, 당장 프로덕션에 때려 박아도 될 수준의 아키텍처입니다.
 결론: Sink 토큰 빼면 세팅이 무너지고, RoPE 조정 안 하면 프레임이 튑니다. 제작진이 하라는 대로 다 써야 이런 퀄리티가 나옵니다.
결론: Sink 토큰 빼면 세팅이 무너지고, RoPE 조정 안 하면 프레임이 튑니다. 제작진이 하라는 대로 다 써야 이런 퀄리티가 나옵니다.
Additional Figures
 Figure 1:Our framework enables the generation of high-quality, temporally coherent videos up to 120 seconds.
Figure 1:Our framework enables the generation of high-quality, temporally coherent videos up to 120 seconds.
