[2026-03-11] 끈적한 OCR 파이프라인의 종말? 4B 파라미터로 레이아웃까지 씹어먹는 Qianfan-OCR 해부

[Metadata]
- Paper: Qianfan-OCR: A Unified End-to-End Model for Document Intelligence
- ArXiv ID: 2603.13398
- Authors: Baidu
- Date: March 2026
비정형 문서에서 표(Table)나 다단 레이아웃을 파싱하다가 키보드 샷건을 쳐본 적 있나요? 기존 OCR 파이프라인은 솔직히 말해 누더기나 다름없습니다. 텍스트 탐지 모델, 인식 모델, 레이아웃 분석 모델을 따로 돌리고 이걸 다시 룰베이스 스크립트로 기워 붙여야 하죠. 유지보수는 끔찍하고, 파이프라인 중간에서 좌표 하나만 엇나가도 최종 결과물은 쓰레기가 됩니다.
그런데 바이두에서 Qianfan-OCR이라는 4B 파라미터 사이즈의 물건을 들고 나왔습니다. 이 녀석은 거추장스러운 파이프라인을 싹 다 밀어버렸어요. 단일 VLM(Vision-Language Model)으로 이미지에서 바로 마크다운을 뽑아냅니다. 단순한 OCR이 아니라 표, 차트, 문서 QA까지 한 방에 처리하는 엔드투엔드(End-to-End) 아키텍처를 구현했죠.
TL;DR: 4B 파라미터 단일 VLM에 “Layout-as-Thought”라는 기발한 추론 토큰을 도입해 복잡한 문서 구조를 파악하지만, 오픈소스가 아닌 바이두 클라우드 API 종속이라는 치명적인 함정이 존재합니다.
⚙️ 파편화된 파이프라인을 부숴버린 단일 VLM의 흑마법
기존 2-Stage 파이프라인의 가장 큰 문제는 시각적 컨텍스트의 비가역적 손실입니다. 크롭된 이미지 조각만 텍스트 인식 모델로 넘어가니, 이 텍스트가 표의 헤더인지 각주인지 알 길이 없죠. Qianfan-OCR은 이 문제를 해결하기 위해 모든 과정을 하나의 모델에 우겨넣었습니다.
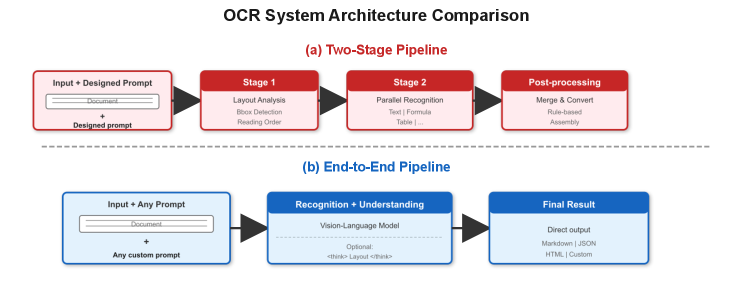 Figure 3: 기존의 지저분한 2단계 파이프라인(a)과 Qianfan-OCR의 단일 모델 접근법(b). 시각적 컨텍스트 유실 없이 프롬프트만으로 태스크를 제어하는 구조가 핵심입니다.
Figure 3: 기존의 지저분한 2단계 파이프라인(a)과 Qianfan-OCR의 단일 모델 접근법(b). 시각적 컨텍스트 유실 없이 프롬프트만으로 태스크를 제어하는 구조가 핵심입니다.
이 페이퍼에서 가장 흥미로운 기술적 도약은 Layout-as-Thought (LaT) 메커니즘입니다. 엔드투엔드 모델은 레이아웃 정보를 명시적으로 출력하지 않아서 복잡한 문서에서 환각(Hallucination)을 일으키기 쉽습니다. 바이두는 이를 해결하기 위해 <think> 토큰을 도입했어요. 최종 텍스트를 뱉기 전에 모델 스스로 바운딩 박스와 요소 타입, 읽기 순서를 먼저 추론하게 만든 겁니다.
내부적으로 이 프롬프트와 출력이 어떻게 흘러가는지 가상의 JSON 응답 형태로 뜯어볼까요?
1
2
3
4
5
6
7
8
9
10
{
"prompt": "<image> Extract document content with layout thinking.",
"response": "<think>
[0.10, 0.05, 0.15, 0.90] type: title
[0.16, 0.05, 0.50, 0.45] type: text_block, order: 1
[0.16, 0.55, 0.50, 0.95] type: image, order: 2
</think>
# Qianfan-OCR Overview
Traditional pipelines suffer from..."
}
🔹 동적 토큰 생성: 모델은 <think> 블록 안에서 [ymin, xmin, ymax, xmax] 형태의 공간 좌표 토큰과 요소 메타데이터를 먼저 쏟아냅니다. 🔹 Self-Conditioning: 이 생각 과정 자체가 이후 마크다운을 생성할 때 강력한 어텐션(Attention) 가이드라인 역할을 합니다. 표 병합이나 다단 텍스트가 꼬이는 현상을 물리적으로 방지하죠.
⚔️ 레거시 파이프라인 vs Layout-as-Thought: 진짜 쓸만한가?
단일 모델이라고 무조건 좋은 건 아닙니다. 컴퓨팅 리소스와 레이턴시 측면에서 득실을 철저히 따져봐야죠. 기존 엔터프라이즈에서 주로 쓰는 PaddleOCR + LLM 조합과 비교해 봤습니다.
| Metric | Legacy 2-Stage (OCR + LLM) | Qianfan-OCR (No Think) | Qianfan-OCR (With Think) |
|---|---|---|---|
| Architecture | Detector + Recognizer + 7B LLM | 4B Unified VLM | 4B Unified VLM |
| Context Loss | High (Cropped patches) | Zero (Global image) | Zero (Global image) |
| Table Extraction | Rule-based (Fragile) | Native Markdown | Highly Accurate Markdown |
| Latency (Token/s) | High (I/O bottlenecks) | Very Fast | Moderate (Overhead from <think>) |
| Setup Time | Days (Complex config) | API Call | API Call |
숫자는 거짓말을 하지 않습니다. OmniDocBench v1.5에서 Qianfan-OCR은 93.12점을 찍으며 모든 엔드투엔드 모델을 박살냈습니다. OlmOCR Bench에서도 79.8점을 기록했죠. 4B라는 상대적으로 가벼운 파라미터로 Gemini-3.1-Pro나 Qwen3-VL-235B 같은 무거운 범용 모델들을 이겼다는 건 꽤 충격적입니다.
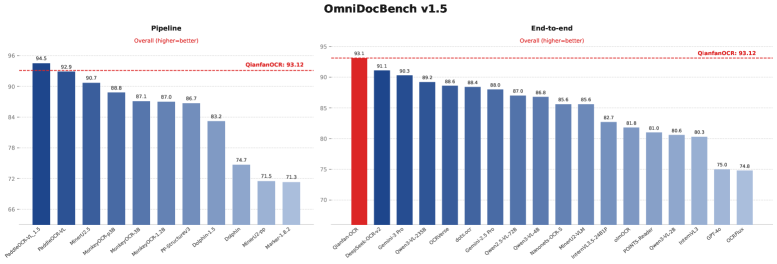 Figure 1: OmniDocBench v1.5 성능. 오른쪽의 빨간 막대가 Qianfan-OCR입니다. 무거운 파이프라인 모델(왼쪽)과 맞먹거나 압도하는 퍼포먼스를 보여줍니다.
Figure 1: OmniDocBench v1.5 성능. 오른쪽의 빨간 막대가 Qianfan-OCR입니다. 무거운 파이프라인 모델(왼쪽)과 맞먹거나 압도하는 퍼포먼스를 보여줍니다.
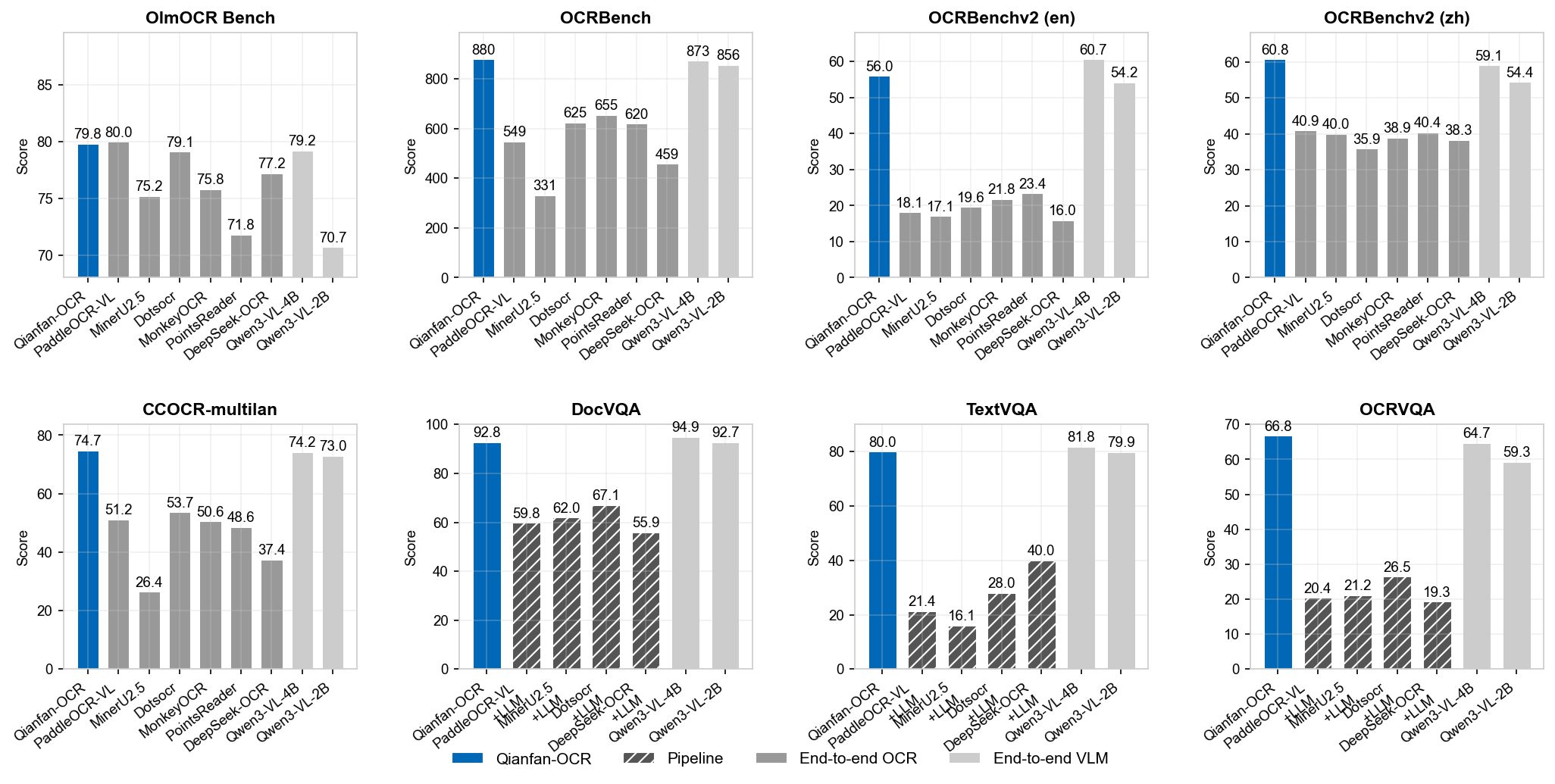 Figure 2: 각종 벤치마크 결과. 하단의 빗금 친 막대(2-stage pipeline)들이 처참하게 무너지는 반면, 엔드투엔드 모델은 일관된 성능을 유지하는 것을 볼 수 있습니다.
Figure 2: 각종 벤치마크 결과. 하단의 빗금 친 막대(2-stage pipeline)들이 처참하게 무너지는 반면, 엔드투엔드 모델은 일관된 성능을 유지하는 것을 볼 수 있습니다.
하지만 가장 주목해야 할 데이터는 바로 Layout Label Entropy입니다. 무조건 <think>를 켠다고 좋은 게 아닙니다.
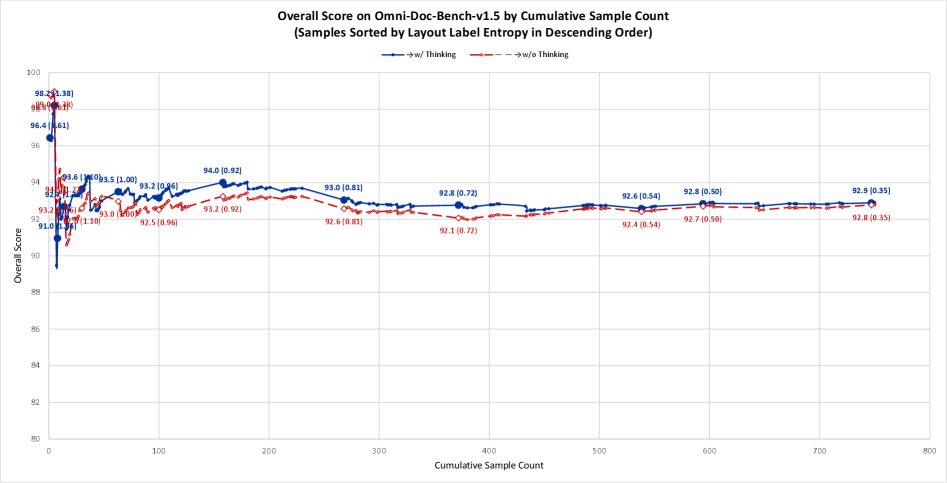 Figure 4: 레이아웃 엔트로피에 따른 누적 점수 변화. 복잡한 문서(왼쪽)에서는 Think 모드가 압도적이지만, 단순한 문서가 포함될수록(오른쪽) 오히려 No-Think 모드의 점수가 높아집니다.
Figure 4: 레이아웃 엔트로피에 따른 누적 점수 변화. 복잡한 문서(왼쪽)에서는 Think 모드가 압도적이지만, 단순한 문서가 포함될수록(오른쪽) 오히려 No-Think 모드의 점수가 높아집니다.
엔트로피가 높은 구간(잡지, 복잡한 논문, 다단 구성)에서는 Layout-as-Thought가 빛을 발합니다. 하지만 구조가 단순한 소설책이나 일반 영수증 같은 저엔트로피 문서에서는 어떨까요? 불필요한 <think> 토큰을 생성하느라 토큰 낭비만 발생하고, 오히려 모델이 과적합(Overfitting)되어 에러율이 미세하게 올라갑니다. 실무에서는 입력 이미지의 복잡도를 먼저 분류하고 프롬프트를 동적으로 스위칭하는 라우팅 전략이 필수적입니다.
🚀 내일 당장 프로덕션에 도입한다면?
이 녀석을 실제 RAG(Retrieval-Augmented Generation) 파이프라인이나 자동화 시스템에 꽂아 넣는다면 어떤 시나리오가 가능할까요?
시나리오 1: 금융권 헬게이트, 비정형 재무제표 RAG 구축 수백 장짜리 PDF에서 쪼개진 표와 주석을 추출하는 건 언제나 지옥입니다. Qianfan-OCR의 테이블 추출(Table Extraction) 프롬프트를 사용하면 별도의 파서 없이 완벽한 Markdown 표를 얻을 수 있습니다. 다만, 4B 모델 특성상 환각이 완전히 제로(0)는 아니므로, 금융 데이터 파싱 후에는 반드시 합계 검증(Checksum) 로직을 백엔드에 붙여야 대형 사고를 막을 수 있습니다.
시나리오 2: 수학 수식(LaTeX) 및 논문 아카이빙 수식이 난무하는 시험지나 논문을 디지털화할 때 기존 모델들은 인라인 수식을 박살내기 일쑤입니다. Layout-as-Thought를 활성화하면 모델이 이미지, 텍스트, 각주를 정확히 바운딩 박스로 분리한 뒤 LaTeX 코드로 렌더링합니다.
 Figure 5: 수학 시험지에 Layout-as-Thought를 적용한 시각화 결과. 텍스트, 이미지, 문단 제목 등을 컬러 코딩된 바운딩 박스로 완벽하게 분리해내는 모습을 확인할 수 있습니다.
Figure 5: 수학 시험지에 Layout-as-Thought를 적용한 시각화 결과. 텍스트, 이미지, 문단 제목 등을 컬러 코딩된 바운딩 박스로 완벽하게 분리해내는 모습을 확인할 수 있습니다.
병목 및 한계점 (Bottlenecks) 오픈소스로 풀렸다면 당장 T4 듀얼 GPU에 올려서 사내 문서를 다 갈아 넣었겠지만, 안타깝게도 이 모델은 Baidu AI Cloud API를 통해서만 접근 가능합니다. 민감한 사내 보안 문서를 중국 클라우드로 쏴야 한다는 것은 북미나 한국 엔터프라이즈 환경에서는 치명적인 도입 블로커(Blocker)가 될 수밖에 없습니다.
🧐 Tech Lead’s Honest Verdict
장점 (Pros):
- Layout-as-Thought의 우아함: 중간 과정(Bounding Box)을 LLM의 토큰 생성 과정에 녹여낸 건 정말 똑똑한 엔지니어링입니다. 디버깅도
<think>블록만 까보면 되니까 훨씬 직관적이죠. - 미친 가성비: 4B 파라미터. 이 작은 사이즈로 거대 VLM들을 벤치마크에서 두들겨 팼다는 건, 그만큼 학습 데이터 큐레이션과 아키텍처 최적화가 극한에 달했다는 증거입니다.
단점 (Cons):
- API 종속성: 웨이트(Weights)를 공개하지 않았습니다. 내부망(On-Premise) 구축이 불가능하다는 건 B2B 비즈니스에서 거대한 마이너스입니다.
- 동적 토큰 비용:
<think>를 남발하면 API 호출당 생성되는 출력 토큰 수가 급증합니다. 단순 텍스트 문서에도 켜두면 클라우드 청구서 폭탄을 맞을 수 있습니다.
최종 판정 (Final Verdict)
“아키텍처 아이디어만 훔치고, 로컬 적용은 오픈소스 Qwen-VL이나 Llama-Vision으로 직접 구현해라.”
Qianfan-OCR이 제시한 Layout-as-Thought 방법론은 오픈소스 진영에서도 당장 써먹을 수 있는 강력한 패러다임입니다. 하지만 API 종속성과 데이터 프라이버시 문제 때문에 실제 프로덕션 도입은 망설여지네요. 개념 증명(PoC)이나 퍼블릭 문서 파싱용으로는 훌륭하지만, 엔터프라이즈 도입은 로컬에 올릴 수 있는 유사 오픈소스 모델이 나올 때까지 존버하는 것을 추천합니다.
