[2026-02-13] RynnBrain: 물리적 지능을 향한 도약, 오픈 소스 Embodied Foundation Model의 심층 기술 분석

1. 핵심 요약 (Executive Summary)
최근 대형 언어 모델(LLM)과 멀티모달 모델(VLM)의 발전은 눈부시지만, 이를 실제 물리적 환경에서 움직이는 로봇이나 에이전트에 적용하는 ‘Embodied AI(체화된 인공지능)’ 분야는 여전히 큰 간극을 가지고 있습니다. RynnBrain은 이러한 간극을 메우기 위해 제안된 혁신적인 오픈 소스 시공간 파운데이션 모델(Spatiotemporal Foundation Model)입니다.
이 모델은 단순한 텍스트-이미지 정렬을 넘어, 물리적 세계의 시공간적 역학을 이해하고 이를 바탕으로 계획(Planning) 및 행동(Action)을 도출하도록 설계되었습니다. 2B에서 30B MoE(Mixture of Experts)에 이르는 다양한 스케일을 제공하며, 자율 주행, 로봇 조작, 시공간 추론 등 특수 목적에 맞춘 4가지 사후 학습(Post-trained) 변종을 포함합니다. 본 분석에서는 RynnBrain이 어떻게 기존의 한계를 극복하고 Embodied AI의 새로운 표준을 제시하는지 기술적으로 심층 분석합니다.
 그림 1: RynnBrain의 네 가지 핵심 역량: 1인칭 시점 인지, 시공간적 국지화, 물리 기반 추론, 물리 인식 계획.
그림 1: RynnBrain의 네 가지 핵심 역량: 1인칭 시점 인지, 시공간적 국지화, 물리 기반 추론, 물리 인식 계획.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
인공지능의 마지막 퍼즐: Embodied Intelligence
인공지능 연구가 디지털 세계(인터넷 데이터)에서 물리적 세계로 확장됨에 따라, ‘지능’의 정의 또한 변화하고 있습니다. 단순한 논리적 추론을 넘어, 환경과의 상호작용을 통해 결과를 도출하는 ‘Embodied Intelligence’는 다음과 같은 고유한 도전 과제를 안고 있습니다.
- 시공간적 정합성 (Spatio-temporal Grounding): 모델은 정적 이미지뿐만 아니라 비디오 스트림에서 객체의 이동 경로와 시간적 변화를 이해해야 합니다.
- 물리적 상호작용 이해 (Physically Grounded Reasoning): 객체의 무게, 마찰력, 중력 등 물리적 법칙이 작용하는 환경 내에서 논리적 판단을 내려야 합니다.
- 다양한 시점의 통합 (Egocentric Understanding): 로봇의 카메라(1인칭 시점)와 외부 감시 카메라(3인칭 시점) 등 다각도의 시각 데이터를 통합적으로 처리해야 합니다.
기존의 VLM(예: GPT-4o, LLaVA)은 뛰어난 일반 인지 능력을 보여주지만, 물리적 좌표(Coordinate)나 궤적(Trajectory)을 생성하는 데 있어 정밀도가 떨어지는 문제를 보였습니다. RynnBrain은 이러한 문제들을 해결하기 위해 ‘Unified Framework’를 제안하며, 인지(Cognition)와 위치(Location)를 결합한 통합 아키텍처를 선보였습니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
3.1 옴니 비전(Omni-Vision) 입력 및 디코더 아키텍처
RynnBrain은 단일 이미지, 다중 뷰 이미지, 그리고 비디오 입력을 모두 수용하는 유연한 아키텍처를 채택했습니다.
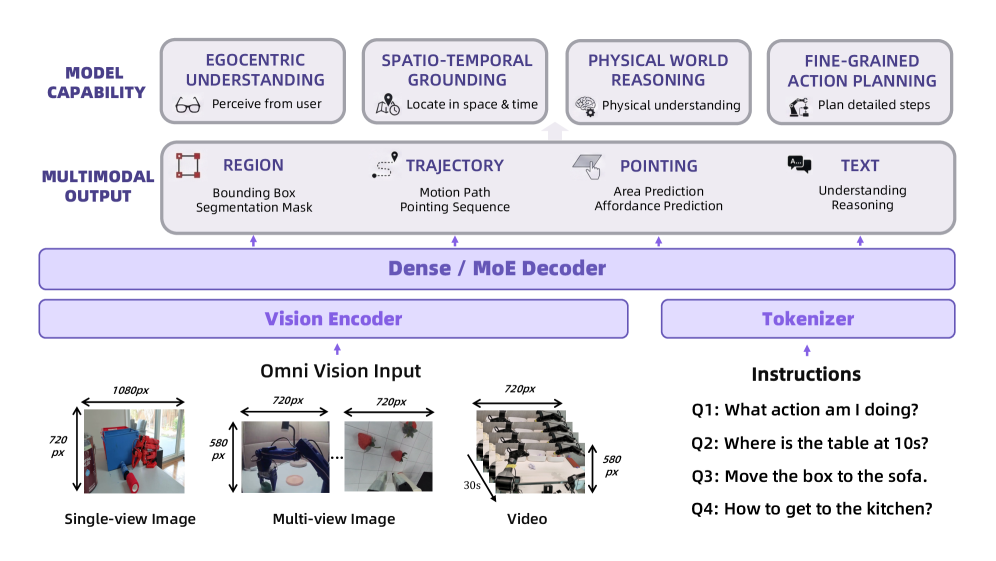 그림 2: RynnBrain의 전체 아키텍처. 텍스트, 리전(Region), 궤적(Trajectory) 등 다양한 멀티모달 출력을 정렬하여 생성함.
그림 2: RynnBrain의 전체 아키텍처. 텍스트, 리전(Region), 궤적(Trajectory) 등 다양한 멀티모달 출력을 정렬하여 생성함.
모델의 핵심은 Mixture of Experts (MoE) 기술의 적용입니다. 30B-A3B 모델의 경우, 전체 파라미터는 30B이지만 추론 시에는 단 3B의 활성 파라미터만 사용합니다. 이는 로봇과 같은 엣지 디바이스 또는 실시간성이 중요한 환경에서 연산 효율성을 극대화하는 전략입니다. 전문가 네트워크(Experts)는 서로 다른 태스크(예: 시각 추론 vs. 행동 계획)에 특화되도록 학습되어 성능 최적화를 이룹니다.
3.2 통합 출력 공간 (Unified Output Space)
RynnBrain의 혁신은 출력 형식에 있습니다. 단순히 자연어 텍스트만 뱉는 것이 아니라, 다음과 같은 Grounding Primitives를 직접 생성합니다.
- Points & Bounding Boxes: 객체의 정확한 위치 파악.
- Trajectories (궤적): 미래의 이동 경로를 시각적 토큰으로 생성.
- Pointing Signals: 특정 행동의 대상이 되는 객체를 지칭.
이러한 출력들은 언어 토큰과 동일한 임베딩 공간에서 관리되므로, “오른쪽 컵을 집어서 왼쪽으로 옮겨라”라는 명령에 대해 컵의 위치 좌표와 이동 경로를 동시에 추론할 수 있게 됩니다.
3.3 RynnBrain-VLA (Vision-Language-Action)
로봇 제어를 위한 핵심 모델인 RynnBrain-VLA는 비전과 언어를 직접 행동(Action)으로 연결합니다.
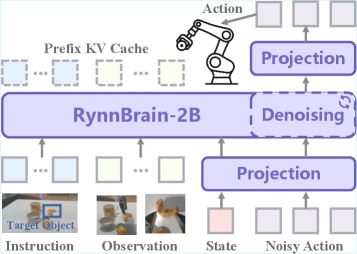 그림 3: 로봇 팔 조작 및 이동 제어를 위한 RynnBrain-VLA 아키텍처.
그림 3: 로봇 팔 조작 및 이동 제어를 위한 RynnBrain-VLA 아키텍처.
기존의 RT-2나 OpenVLA와 비교했을 때, RynnBrain-VLA는 더 강력한 시공간적 사전 학습 데이터를 바탕으로 미세한 동작 제어가 가능합니다. 특히 Physics-aware Planning 모듈은 물리 법칙을 고려하여 장애물을 피하거나 최적의 경로를 설정하는 능력이 탁월합니다.
4. 구현 및 실험 환경 (Implementation Details)
데이터셋 구성
RynnBrain은 약 20여 개의 Embodied 벤치마크와 8개의 일반 비전 이해 벤치마크를 통해 학습되었습니다. 여기에는 로봇 시뮬레이션 데이터(Isaac Gym, SAPIEN), 실제 로봇 조작 비디오, 그리고 방대한 양의 텍스트-이미지 페어가 포함됩니다. 특히 모델이 ‘시간적 연속성’을 학습할 수 있도록 프레임 간의 인과 관계를 파악하는 태스크에 가중치를 두었습니다.
모델 스케일링
- 2B / 8B (Dense): 리소스가 제한된 모바일 로봇용.
- 30B-A3B (MoE): 복잡한 추론과 정교한 계획이 필요한 고성능 에이전트용.
이러한 계층적 라인업은 개발자들이 하드웨어 사양에 맞춰 모델을 선택할 수 있는 넓은 선택지를 제공합니다.
5. 성능 평가 및 비교 (Comparative Analysis)
RynnBrain-Bench 성능 측정
연구진은 모델의 성능을 정밀하게 평가하기 위해 RynnBrain-Bench를 제안했습니다. 이는 인지(Cognition)와 위치(Location)라는 두 가지 큰 축 아래 21가지 세부 능력을 평가합니다.
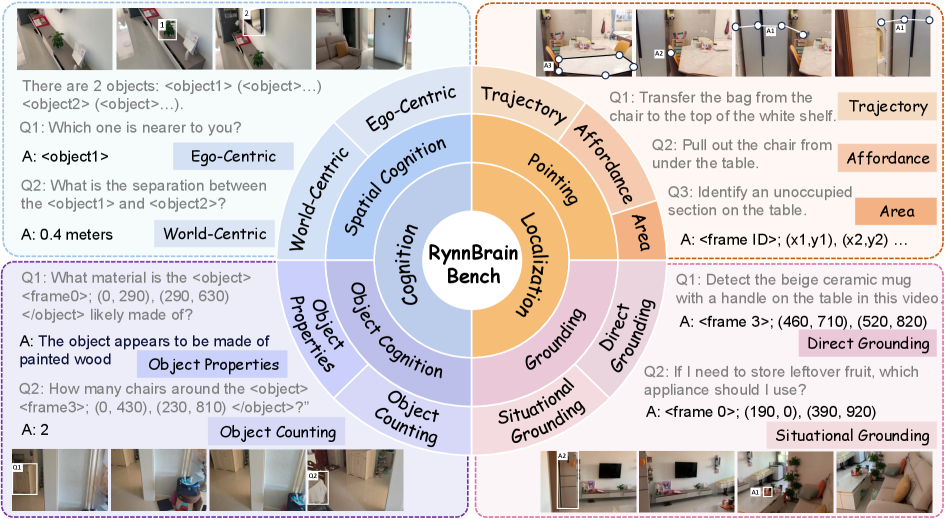 그림 4: 21가지 시공간 미세 능력을 측정하는 RynnBrain-Bench의 평가 차원.
그림 4: 21가지 시공간 미세 능력을 측정하는 RynnBrain-Bench의 평가 차원.
실험 결과, RynnBrain은 기존의 SOTA(State-of-the-Art) 모델들을 상당한 격차로 앞질렀습니다. 특히 ‘시공간적 국지화(Spatio-temporal Localization)’ 항목에서는 기존 모델들이 영상 속 객체의 이동을 놓치는 반면, RynnBrain은 매우 높은 정밀도로 궤적을 예측해 냈습니다.
전문가 소견: 이는 RynnBrain이 단순히 다음 토큰을 예측하는 통계적 언어 모델을 넘어, 가상 세계 내에서 ‘세계 모델(World Model)’의 일부 기능을 수행하고 있음을 시사합니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application)
6.1 스마트 팩토리 및 협동 로봇
RynnBrain-VLA는 공장 자동화에서 핵심적인 역할을 할 수 있습니다. 비정형화된 환경에서 부품을 인식하고, 장애물을 피해 조립하는 과정은 높은 수준의 시공간 인지가 필요합니다. RynnBrain의 물리 인식 계획 능력은 산업 현장에서 사고를 줄이고 생산성을 높이는 데 기여할 것입니다.
6.2 자율 주행 및 배송 로봇
복잡한 도심 환경에서 보행자의 궤적을 예측하고, 좁은 골목길을 통과하는 배송 로봇에게 RynnBrain의 Spatiotemporal Grounding 능력은 필수적입니다. 특히 1인칭 시점(Egocentric)의 비디오 분석에 최적화되어 있어 차량용 AI로서의 잠재력도 매우 큽니다.
6.3 가정용 비서 로봇
“부엌에 가서 빨간색 컵을 찾아 냉장고 옆으로 옮겨줘”와 같은 자연어 명령을 복잡한 좌표값으로 변환하여 실행하는 능력은 실버 케어나 가사 노동 자동화 분야에서 게임 체인저가 될 것입니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critique)
본 연구가 놀라운 성과를 거두었음에도 불구하고, 몇 가지 비판적 시각을 유지할 필요가 있습니다.
- 실시간성 및 지연 시간 (Latency): 30B MoE 모델이 효율적이라 할지라도, 로봇의 센서-액추에이터 루프는 밀리초(ms) 단위의 반응 속도를 요구합니다. 복잡한 추론 과정을 거치는 동안 로봇이 실시간 변화에 대응하지 못할 위험이 여전히 존재합니다.
- 데이터 편향성: Embodied 데이터의 특성상 시뮬레이션 비중이 높을 수밖에 없습니다. 시뮬레이션에서는 물리 법칙이 단순화되는 경우가 많아, ‘Sim-to-Real’ 전이 과정에서의 불확실성이 해결되었는지에 대한 더 많은 실증 연구가 필요합니다.
- 오픈 소스의 완전성: 논문에서는 오픈 소스를 강조하고 있지만, 방대한 학습 데이터셋 전체와 데이터 정제 파이프라인이 투명하게 공개되지 않는다면 후속 연구자들이 이를 재현하거나 확장하는 데 어려움을 겪을 수 있습니다.
- 윤리적 및 안전성 문제: 물리적 액션을 수행하는 모델인 만큼, 잘못된 계획(Planning)이 인간에게 물리적 해를 끼칠 수 있는 상황에 대한 안전장치(Safety Guardrail)가 아키텍처 수준에서 충분히 논의되지 않았습니다.
8. 결론 및 인사이트 (Conclusion)
RynnBrain은 Embodied AI 분야에서 ‘파운데이션 모델’이 가야 할 이정표를 명확히 제시했습니다. 인지, 국지화, 추론, 계획을 하나의 통합된 프레임워크로 묶음으로써, 로봇이 단순한 기계가 아닌 ‘생각하는 행위자’로 거듭날 수 있는 기술적 토대를 마련했습니다.
특히 MoE 아키텍처를 통한 효율적인 스케일링과 오픈 소스 생태계를 지향한다는 점은 학계와 산업계 모두에 큰 긍정적 영향을 미칠 것입니다. 향후 RynnBrain이 더 다양한 실제 물리적 데이터(Real-world Interaction Data)와 결합된다면, 우리는 공상과학 영화에서 보던 수준의 고도화된 지능형 로봇을 일상에서 곧 마주하게 될 것입니다.
AI 개발자라면 RynnBrain의 통합 출력 공간(Unified Output Space) 개념을 주목하십시오. 이는 텍스트와 물리적 좌표를 어떻게 효과적으로 융합할지에 대한 가장 세련된 답변 중 하나입니다.
