[2026-03-26] ShotStream 딥다이브: 단일 GPU로 16 FPS 실시간 멀티샷 비디오를 뽑아내는 인과적 아키텍처의 비밀

[Paper Metadata]
- Title: ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling
- ArXiv ID: 2603.25746
멀티샷 비디오 생성 파이프라인을 구축해본 개발자라면 다들 뼈저리게 공감하실 겁니다. 기존의 비디오 생성 모델들은 너무 게으르고, 무겁고, 답답하죠. 사용자가 실시간으로 스토리를 바꾸고 싶어도, 기존의 양방향(Bidirectional) 아키텍처들은 전체 타임라인의 컨텍스트를 다 쥐고 있어야만 비로소 렌더링을 시작합니다.
사용자가 프롬프트를 입력할 때마다 수십 초, 길게는 몇 분을 대기시켜야 한다면 그게 무슨 ‘인터랙티브 스토리텔링’일까요? 그냥 예쁜 로딩 화면 감상기일 뿐이죠. 우리가 진짜 원하는 건 LLM이 토큰을 뱉어내듯, 비디오 프레임도 스트리밍으로 쏟아지는 환경입니다.
오늘 뜯어볼 ShotStream은 바로 이 지독한 레이턴시 문제를 박살 낸 아키텍처입니다. 양방향 텍스트-비디오(T2V) 모델을 인과적(Causal) 모델로 강제 개조해서, 단일 GPU 환경에서도 무려 16 FPS의 속도로 멀티샷 비디오를 실시간으로 뽑아냅니다.
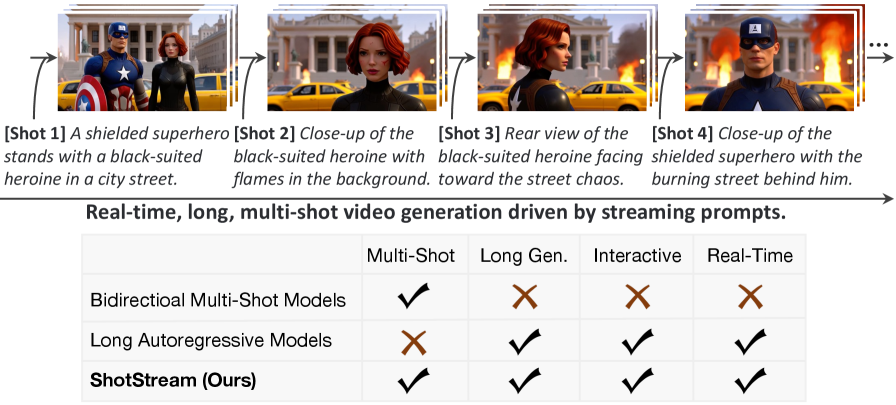
- 이 다이어그램이 핵심입니다. 스트리밍 프롬프트를 받자마자 실시간으로 다음 샷을 끊임없이 생성해내는 인과적(Causal) 워크플로우를 명확하게 보여주죠.
TL;DR: 기존 양방향 비디오 생성의 살인적인 지연 시간을 버리고, 인과적(Causal) 스트리밍 구조와 듀얼 캐시 메모리를 도입해 단일 GPU에서 16 FPS 실시간 멀티샷 비디오를 생성합니다. 단, 자기 회귀(Autoregressive) 특유의 오차 누적을 잡기 위한 2단계 증류(Distillation) 파이프라인이 꽤나 무겁게 설계되었다는 게 핵심 관전 포인트입니다.
⚙️ 픽셀 뭉치를 3D 공간으로 연성하는 파이프라인 해부
ShotStream의 진짜 매력은 논문의 껍데기 포장이 아니라 그 밑단에 깔린 엔지니어링 묘수에 있습니다. 도대체 어떻게 느려터진 양방향 모델을 실시간 스트리밍 머신으로 바꿨을까요?
이들은 다짜고짜 처음부터 모델을 학습시키지 않았습니다. 대신 아주 영리한 우회로를 탔죠. 우선 기존의 텍스트-비디오(T2V) 모델을 양방향 넥스트샷 교사(Bidirectional Next-Shot Teacher) 모델로 파인튜닝합니다.
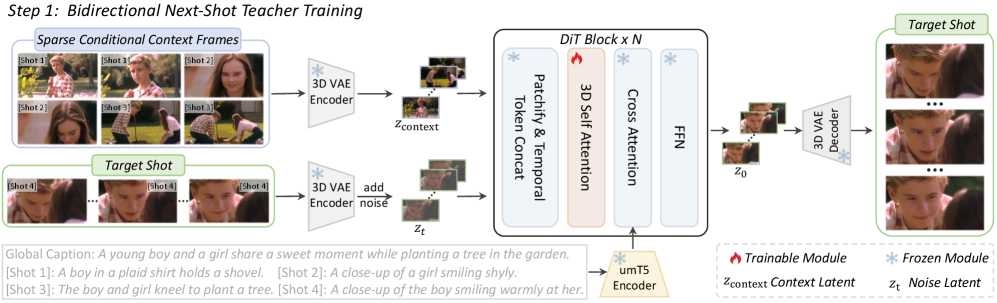
- 기존 T2V 모델을 양방향 넥스트샷 교사(Teacher) 모델로 파인튜닝하는 과정입니다. 3D VAE로 압축한 컨텍스트 프레임을 노이즈와 시간 축(Temporal dimension)으로 연결하는 무식하지만 확실한 방법을 씁니다.
하지만 이 교사 모델은 여전히 느립니다. 그래서 이 무거운 지식을 가볍고 빠른 인과적 학생(Causal Student) 모델로 밀어 넣기 위해 DMD(Distribution Matching Distillation) 기법을 사용합니다.
잠깐, 여기서 치명적인 문제가 발생합니다. 인과적(Causal) 생성 방식, 즉 이전 프레임만 보고 다음 프레임을 예측하는 방식은 필연적으로 샷 간의 일관성(Inter-shot consistency)을 박살 냅니다. 카메라 앵글이 바뀌거나 씬이 전환될 때 캐릭터의 옷 색깔이 변해버리는 끔찍한 현상이 생기죠. 이를 해결하기 위해 ShotStream은 듀얼 캐시 메모리(Dual-Cache Memory)라는 무기를 꺼내 듭니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# [Mock PyTorch Pseudo-code] ShotStream의 듀얼 캐시 어텐션 메커니즘
class DualCacheAttention(nn.Module):
def forward(self, current_hidden_state, global_cache, local_cache, rope_indicator):
# global_cache: 이전 샷(Shot)들의 조건부 프레임 (샷 간 일관성 유지)
# local_cache: 현재 샷 내부에서 방금 생성된 프레임들 (샷 내부 일관성 유지)
# RoPE (Rotary Position Embedding) 불연속성 지시자로 두 캐시를 명시적으로 분리
q = apply_rope(self.q_proj(current_hidden_state), rope_indicator.current)
# 글로벌 캐시와 로컬 캐시의 Key, Value 생성
k_global = apply_rope(self.k_proj(global_cache), rope_indicator.global_mask)
k_local = apply_rope(self.k_proj(local_cache), rope_indicator.local_mask)
# 캐시 결합 연산 (이때 VRAM 폭발을 막기 위한 최적화가 필수적임)
K = torch.cat([k_global, k_local], dim=1)
V = torch.cat([self.v_proj(global_cache), self.v_proj(local_cache)], dim=1)
# Flash Attention-2 등을 통한 인과적(Causal) 어텐션 수행
out = flash_attn_func(q, K, V, causal=True)
return out
글로벌 캐시는 이전 샷의 핵심 프레임을 쥐고 있고, 로컬 캐시는 지금 렌더링 중인 샷의 프레임들을 기억합니다. 흥미로운 건 이 두 캐시가 섞이면서 발생할 수 있는 위치 정보의 혼란을 막기 위해 RoPE 불연속성 지시자(RoPE discontinuity indicator)를 도입했다는 점입니다. 어텐션 레이어가 과거와 현재를 헷갈리지 않게 멱살을 잡고 가이드하는 역할을 하죠.
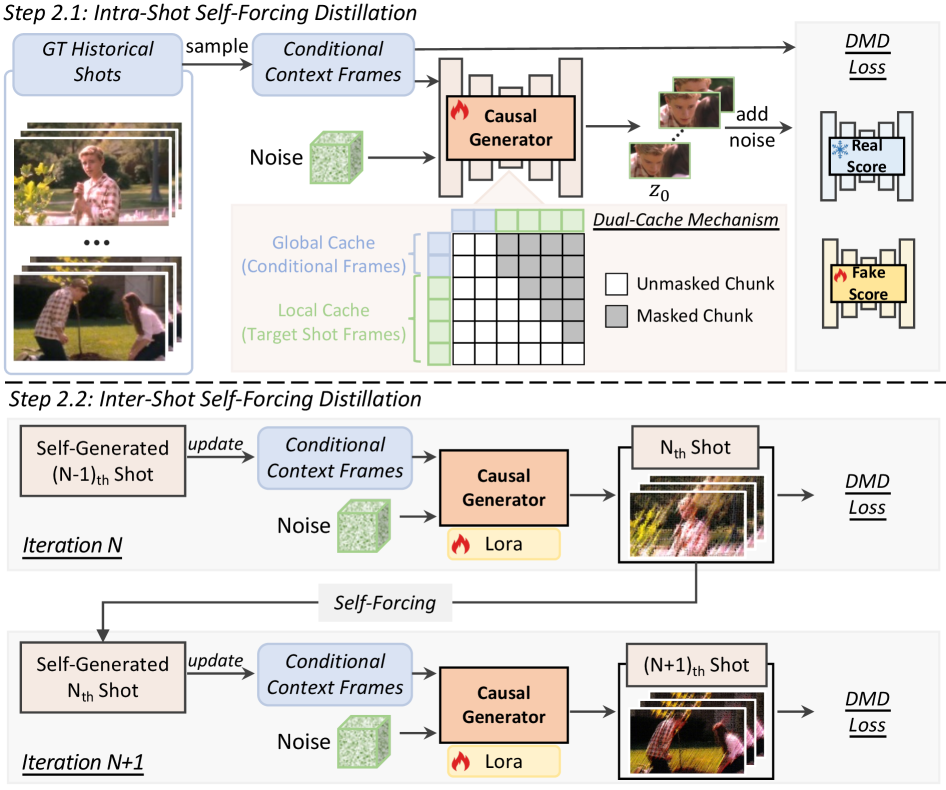
- 인과적 생성의 고질병인 ‘오차 누적’을 막기 위한 2단계 증류(Distillation) 파이프라인과 글로벌/로컬 듀얼 캐시 아키텍처의 민낯입니다.
그리고 증류 과정도 예술입니다. 단순히 교사의 아웃풋을 따라 하는 게 아니라 2단계 증류 전략을 씁니다. 1단계(Intra-shot)에서는 완벽한 정답 역사(Ground-truth)를 주고 훈련시키다가, 2단계(Inter-shot)에서는 모델 스스로가 만든 엉망진창인 과거 프레임을 기반으로 다음 샷을 만들게 강제합니다. 실무에서 뼈저리게 겪는 Train-Test Gap(학습과 실제 추론 시의 환경 차이)을 기가 막히게 메워버리는 거죠.
⚔️ 기존 스택 vs 새로운 패러다임: 진짜 갈아탈 가치가 있나?
그렇다면 현업에서 구르고 있는 우리 입장에서, 기존의 파이프라인을 다 갈아엎고 이 녀석을 도입할 가치가 있을까요? 숫자로 한번 비교해 보죠.
| 비교 지표 | 기존 Bidirectional T2V (예: 초기 Sora 류, 전통적 Multi-shot) | ShotStream (Causal Student) |
|---|---|---|
| 아키텍처 구조 | 양방향 (미래 프레임 정보 필수) | 인과적 (이전 프레임만으로 스트리밍) |
| 지연 시간 (Latency) | 샷 전체 렌더링 후 응답 (수십 초~분 단위) | Sub-second (1초 미만 즉각 반응) |
| 초당 프레임 (FPS) | 1~3 FPS (무거운 확산 모델 기준) | 16 FPS (단일 GPU 기준) |
| 인터랙티비티 | 사실상 불가능 (생성 중 프롬프트 개입 불가) | 완전 가능 (On-the-fly 프롬프트 변경) |
| VRAM 사용량 | 샷의 길이가 길어질수록 기하급수적 증가 | 듀얼 캐시 관리로 선형적 증가 (최적화 됨) |
기존 방식은 비디오 클립 하나를 다 구워낼 때까지 사용자가 아무것도 할 수 없습니다. API 비용은 시간당으로 줄줄 새고, 사용자는 로딩 스피너만 보다가 이탈해 버리죠.
반면 ShotStream은 첫 프레임이 나오는 데 걸리는 시간(Time-to-First-Frame)을 극단적으로 줄였습니다. 16 FPS라는 수치는 단일 GPU에서 뽑아냈다는 점을 감안하면 경이로운 수준입니다. 개발자 입장에선 이 정도면 당장 웹 소켓(WebSocket) 열어두고 클라이언트랑 실시간으로 비디오 스트림을 주고받는 구조를 짤 수 있다는 뜻입니다.

- 경쟁 모델들과의 비교인데, 프롬프트 반영도와 샷 간의 자연스러운 전환(Consistency)에서 압도적인 차이를 보여줍니다.
🚀 내일 당장 프로덕션에 도입한다면?
이론은 훌륭하지만, 이걸 당장 우리 서비스 백엔드에 붙인다고 상상해 봅시다. 어떤 시나리오가 가능할까요?
1. 실시간 TRPG & 무한 분기형 인터랙티브 게임 사용자의 텍스트 선택지에 따라 다음 씬이 실시간으로 렌더링되는 웹 게임을 만들 수 있습니다. 유저가 “갑자기 드래곤이 난입한다”라고 채팅을 치면, 로딩 화면 없이 현재 재생 중인 씬 다음 샷으로 드래곤이 튀어나오는 비디오가 바로 스트리밍되는 겁니다. ShotStream의 듀얼 캐시 덕분에 배경의 성곽이나 캐릭터의 외형은 그대로 유지되겠죠.
2. 사용자 맞춤형 동적 광고 (Dynamic Video Ads) 생성기 유저의 실시간 체류 데이터나 스크롤 반응에 맞춰 광고 영상의 스토리를 온더플라이(On-the-fly)로 비틀어버릴 수 있습니다. 이전 샷까지는 평범한 커피 광고였다가, 유저가 ‘할인’ 태그에 마우스를 올리는 순간 커피잔에서 할인 쿠폰이 튀어나오는 다음 샷을 즉시 이어붙여 버리는 거죠.
하지만 병목(Bottleneck)이 없는 건 아닙니다. 솔직히 이 부분은 짚고 넘어가야 합니다. 글로벌 캐시와 로컬 캐시를 계속 쌓아두면서 무한정 샷을 생성한다면 어떻게 될까요? 결국 KV 캐시가 비대해져서 VRAM에 아웃오브메모리(OOM)가 날 수밖에 없습니다. 논문에서는 효율적이라고 말하지만, 실제 프로덕션에서 무한 스트리밍을 구현하려면 오래된 글로벌 캐시를 지능적으로 쳐내는(Eviction) 메모리 관리 로직을 개발자가 직접 짜넣어야 할 겁니다.
🧐 Tech Lead’s Honest Verdict
결론을 내려보죠. ShotStream, 이거 쓸만한가요?
- Pros: 기존 비디오 생성의 미쳐버린 레이턴시를 박살 냈습니다. 16 FPS 스트리밍은 당장 실무에 적용해보고 싶을 정도로 섹시한 수치입니다. 특히 2단계 증류로 오차 누적을 잡으려 한 엔지니어링 접근은 매우 훌륭합니다.
- Cons: 무한에 가까운 스트리밍에서는 결국 VRAM 한계와 장기적 컨텍스트 상실(Long-term context loss)이 발생할 확률이 높습니다. 그리고 교사 모델을 만들고 DMD로 증류하는 초기 훈련 파이프라인의 컴퓨팅 비용은 스타트업 입장에서 꽤나 부담스러울 겁니다.
🔥 Final Verdict: “장난감 프로젝트나 짧은 인터랙티브 캠페인용으로는 당장 Clone해서 써볼 것. 단, 24시간 돌아가는 무한 스트리밍 프로덕션 도입은 캐시 최적화 전략이 확보된 이후로 미루시길.”
생성형 AI 시대에 접어들면서 비디오 쪽은 늘 ‘속도’가 발목을 잡았습니다. ShotStream은 그 족쇄를 끊어낸 아주 의미 있는 첫걸음입니다. 비디오 렌더링의 패러다임이 배치(Batch)에서 스트리밍(Streaming)으로 넘어가는 이 변곡점, 개발자라면 절대 놓쳐선 안 될 흐름이네요.
Additional Figures
 Figure 6:Qualitative Ablation Results for the Causal Student Model. Please refer toproject pagefor video comparisons.
Figure 6:Qualitative Ablation Results for the Causal Student Model. Please refer toproject pagefor video comparisons.
