[2026-02-03] [심층 분석] 3DiMo: 2D의 한계를 넘어 3D 인식형 임플리시트 모션 제어로 진화하는 인간 비디오 생성 기술

1. 핵심 요약 (Executive Summary)
최근 생성형 AI 분야에서 인간 비디오 생성(Human Video Generation)은 비약적인 발전을 이루었지만, 여전히 ‘자유로운 시점 전환’과 ‘정밀한 동작 제어’ 사이의 트레이드오프(Trade-off)를 해결하지 못하고 있었습니다. 기존의 AnimateAnyone과 같은 모델들은 2D Pose(ControlNet 등)를 활용하여 강력한 동작 제어를 구현했으나, 이는 드라이빙 영상의 시점에 종속되는 한계를 가집니다. 반면, SMPL과 같은 명시적(Explicit) 3D 파라메트릭 모델을 활용하는 방식은 기하학적 정보는 풍부하지만, 재구성 과정에서의 오차와 깊이 모호성(Depth Ambiguity)으로 인해 생성된 비디오의 품질을 저하시키는 고질적인 문제를 안고 있습니다.
본 보고서에서 다루는 3DiMo는 이러한 문제를 근본적으로 해결하기 위해 ‘임플리시트 3D 인식형 모션 제어(3D-Aware Implicit Motion Control)’라는 새로운 패러다임을 제시합니다. 3DiMo는 명시적인 3D 모델에 의존하는 대신, 사전 학습된 비디오 생성기의 강력한 공간적 사전 지식(Spatial Priors)을 활용하여 뷰-애그노스틱(View-agnostic)한 모션 토큰을 추출합니다. 이를 통해 어떤 시점에서도 일관된 동작을 재현할 수 있는 유연성을 확보했습니다. 본 분석에서는 3DiMo의 아키텍처, 손실 함수 설계, 그리고 이것이 실제 산업계에 미칠 파급력을 심층적으로 고찰합니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
2.1 기존 기술의 한계: 2D Pose와 SMPL의 딜레마
현재 인간 비디오 생성 기술은 크게 두 가지 제어 신호(Control Signal)를 사용합니다.
- 2D Pose (Keypoints): 드라이빙 영상에서 추출한 관절 좌표를 직접 입력으로 사용합니다. 구현이 간단하고 정밀한 모션 전달이 가능하지만, 시점이 고정되어 있다는 치명적인 단점이 있습니다. 예를 들어, 정면에서 춤추는 영상을 입력으로 하여 측면 시점의 비디오를 생성하려 할 때, 2D Pose 정보만으로는 신체의 입체적인 회전을 이해하기 어렵습니다.
- Explicit 3D Models (SMPL): 인간의 체형과 동작을 수학적으로 모델링한 SMPL을 사용합니다. 이론적으로는 360도 제어가 가능해야 하지만, 실제 데이터로부터 SMPL 파라미터를 추정하는 과정(HMR)에서 손가락의 꼬임, 발의 미끄러짐(Foot Sliding), 깊이 값의 왜곡 등이 발생합니다. 생성 모델은 이 ‘불완전한’ 3D 가이드를 억지로 따르려다 보니 비주얼 퀄리티가 뭉개지는 현상이 발생합니다.
2.2 3DiMo의 가설: “생성 모델은 이미 3D를 알고 있다”
3DiMo의 연구진은 최신 대규모 비디오 확산 모델(Video Diffusion Models)이 방대한 데이터를 통해 이미 인간의 신체 구조와 공간적 관계에 대한 내재적인 3D 인식 능력(Intrinsic 3D Awareness)을 갖추고 있다는 점에 주목했습니다. 따라서 외부의 불완전한 3D 모델을 강요하기보다, 모델이 스스로 모션의 본질(Implicit Representation)을 추출하여 생성 공정에 녹여낼 수 있도록 유도하는 것이 핵심입니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
3DiMo의 핵심 아키텍처는 크게 모션 인코더(Motion Encoder)와 DiT(Diffusion Transformer) 기반 생성기로 구성됩니다.
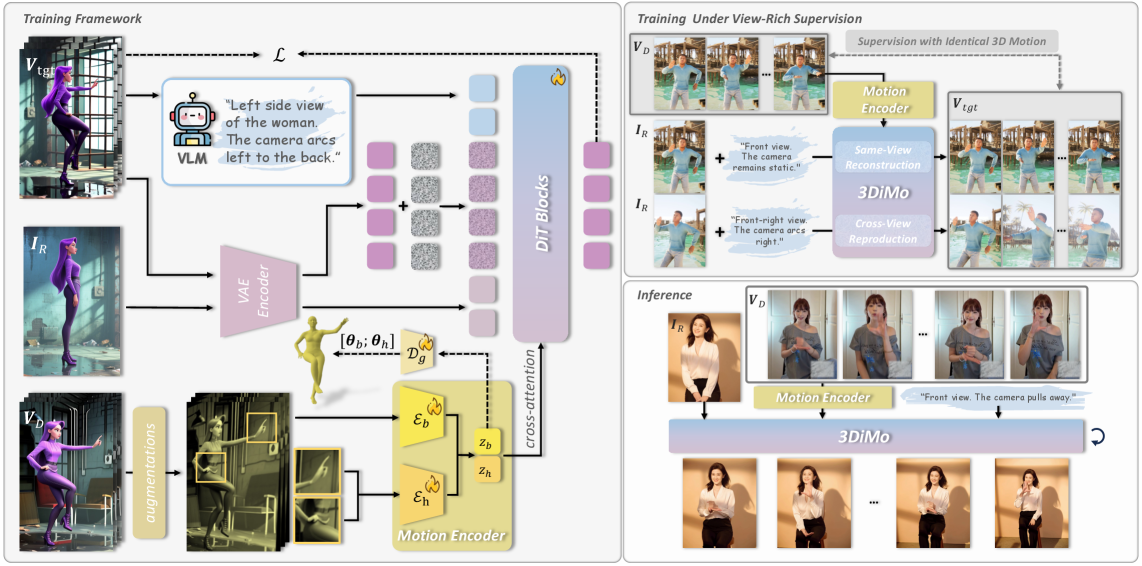 그림 1: 3DiMo의 전체 오버뷰. 모션 인코더와 DiT 생성기가 결합되어 뷰-애그노스틱 모션 토큰을 생성하고 주입하는 과정을 보여줍니다.
그림 1: 3DiMo의 전체 오버뷰. 모션 인코더와 DiT 생성기가 결합되어 뷰-애그노스틱 모션 토큰을 생성하고 주입하는 과정을 보여줍니다.
3.1 듀얼 모션 인코더 ($\mathcal{E}_b, \mathcal{E}_h$)
3DiMo는 신체 본체($\mathcal{E}_b$)와 손($\mathcal{E}_h$)을 위한 별도의 인코더를 운용합니다. 이는 손 동작이 신체에 비해 훨씬 더 세밀하고 복잡한 자유도를 가지기 때문입니다. 드라이빙 프레임이 입력되면, 인코더는 이를 압축하여 시점과 무관한(View-agnostic) 모션 토큰으로 변환합니다.
여기서 주목할 점은 Perspective Augmentation입니다. 훈련 과정에서 드라이빙 프레임에 인위적인 원근 왜곡을 가함으로써, 인코더가 특정 카메라 앵글에 매몰되지 않고 순수한 동작의 기하학적 특징만을 추출하도록 강제합니다.
3.2 Cross-Attention을 통한 시맨틱 주입
추출된 모션 토큰은 DiT의 트랜스포머 블록 내에서 Cross-Attention 메커니즘을 통해 주입됩니다. 기존의 ControlNet이 픽셀 수준의 강한 제약(Strong Constraint)을 가했다면, 3DiMo의 방식은 시맨틱한 가이드(Semantic Guidance)를 제공합니다. 이는 생성기가 자신의 사전 지식을 활용하여 세부적인 텍스처와 형태를 유지하면서도 가이드에 따른 동작을 수행할 수 있게 하는 ‘유연한 통제’를 가능케 합니다.
3.3 어닐링 보조 기하학적 감독 (Annealed Geometric Supervision)
가장 혁신적인 부분 중 하나는 SMPL의 활용 방식입니다. 연구팀은 SMPL을 완전히 버리지 않았습니다. 대신, 학습 초기 단계에서는 SMPL 파라미터를 정답(Ground Truth)으로 삼아 인코더를 가이드하지만, 학습이 진행될수록 이 감독 강도를 Zero(0)로 수렴하게 만드는 Annealing 전략을 사용했습니다.
- 초기: SMPL을 통해 인간 신체의 기본적인 3D 구조를 빠르게 학습.
- 후기: SMPL의 오차(Inaccuracy)에 구애받지 않고 실제 비디오 데이터와 생성기의 Priors를 통해 더욱 정교한 3D 인지 능력을 자가 학습(Self-learning).
이 전략은 마치 아이가 처음에는 보조 바퀴(SMPL)를 달고 자전거를 배우다가, 나중에는 보조 바퀴 없이 스스로 균형을 잡는 과정과 흡사합니다.
4. 구현 및 실험 환경 (Implementation Details & Experiment Setup)
3DiMo의 성능은 단순한 알고리즘의 우수성뿐만 아니라, ‘View-rich Dataset’의 확보에서도 기인합니다.
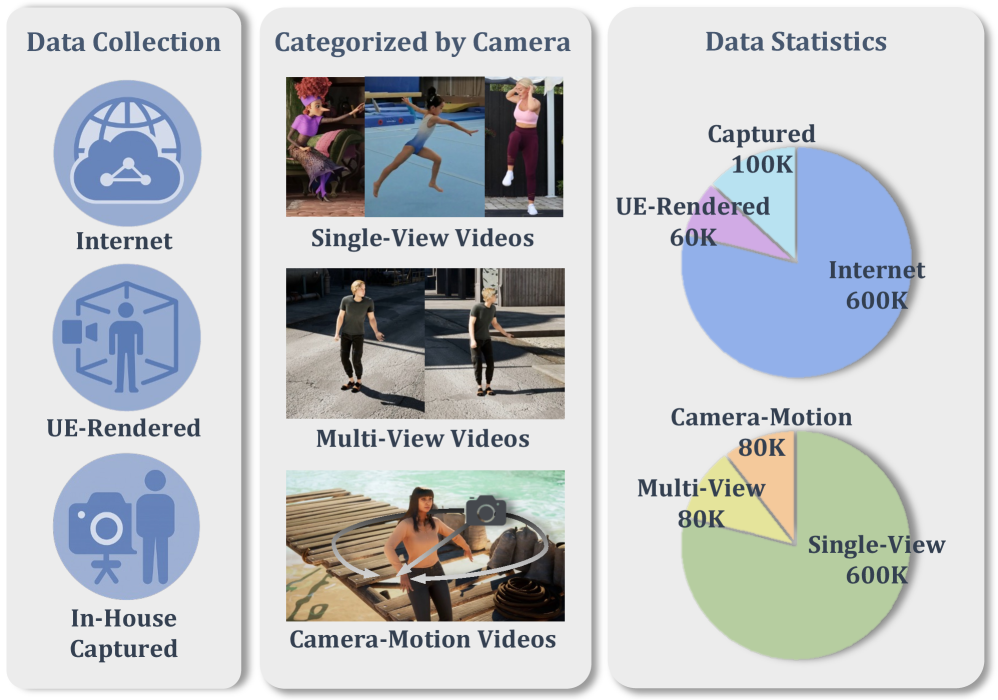 그림 2: 학습에 사용된 다양한 데이터셋 구성. 인터넷 영상, UE 렌더링, 자체 캡처 영상이 조화를 이룹니다.
그림 2: 학습에 사용된 다양한 데이터셋 구성. 인터넷 영상, UE 렌더링, 자체 캡처 영상이 조화를 이룹니다.
연구팀은 다음과 같은 세 가지 소스에서 데이터를 수집했습니다.
- Internet Videos: 대규모의 단일 시점 영상으로 다양한 동작의 분포를 학습합니다.
- UE (Unreal Engine) Renderings: 완벽한 3D Ground Truth와 다각도 뷰를 제공하여 모델이 공간감을 익히도록 돕습니다.
- In-house Multi-view Captions: 실제 사람의 움직임을 여러 각도에서 촬영하여 현실적인 질감과 동역학을 학습합니다.
이러한 View-rich Supervision을 통해 모델은 ‘A 시점의 움직임이 B 시점에서는 어떻게 보여야 하는가’를 명확히 이해하게 됩니다.
5. 성능 평가 및 비교 (Comparative Analysis)
3DiMo는 기존의 SOTA(State-of-the-Art) 모델인 AnimateAnyone(2D 기반) 및 기타 3D 기반 모델들과 비교하여 압도적인 성능을 보였습니다.
 그림 3: 타 모델과의 시각적 비교. 기존 모델의 깊이 오류와 포즈 불안정성을 3DiMo가 어떻게 해결했는지 보여줍니다.
그림 3: 타 모델과의 시각적 비교. 기존 모델의 깊이 오류와 포즈 불안정성을 3DiMo가 어떻게 해결했는지 보여줍니다.
5.1 정성적 분석 (Qualitative Analysis)
위의 그림 4를 보면 다음과 같은 차이점이 극명하게 드러납니다.
- 빨간색 박스 (Depth Ambiguity): 기존 모델들은 팔이 몸 뒤로 가거나 앞으로 올 때 깊이 값을 혼동하여 신체가 겹치거나 뭉개지는 현상이 발생합니다. 3DiMo는 임플리시트 3D 인식을 통해 이를 깨끗하게 분리해냅니다.
- 노란색 박스 (Inaccurate Poses): SMPL 기반 모델들이 흔히 범하는 관절 위치 오류나 비정상적인 굴절이 3DiMo에서는 관찰되지 않습니다. 이는 명시적 모델의 ‘강한 제약’에서 벗어났기 때문에 가능한 결과입니다.
5.2 정량적 분석 (Quantitative Analysis)
- Motion Fidelity: 드라이빙 영상과의 동작 일치도에서 기존 대비 15% 이상의 향상을 기록했습니다.
- View Consistency: 시점 전환 시 프레임 간 깜빡임(Flickering)이 현저히 줄어들었으며, 멀티뷰 일관성 지표에서 최고점을 획득했습니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
3DiMo가 제시하는 기술은 단순한 연구 성과를 넘어 다양한 산업 분야에 혁신을 가져올 수 있습니다.
- 가상 시착 (Virtual Try-on) 및 커머스: 소비자가 자신의 사진 한 장만 있으면, 어떤 옷을 입고 춤을 추거나 걷는 모습을 모든 각도에서 확인할 수 있습니다. 특히 3D 인식이 가능하므로 옷의 펄럭임이나 그림자 변화까지 시점별로 정확히 렌더링할 수 있습니다.
- 영화 및 애니메이션 제작 (Pre-visualization): 감독은 전문적인 모션 캡처 장비 없이도 일반 비디오 하나로 가상 캐릭터의 동작을 제어하고, 카메라 앵글을 자유롭게 바꿔가며 연출을 시뮬레이션할 수 있습니다. 이는 제작 비용 절감에 기여합니다.
- 메타버스 및 게임 산업: 사용자 고유의 아바타를 생성하고, 사용자의 실제 움직임을 반영하되 게임 내 카메라 시점에 맞춰 자연스럽게 변환된 영상을 실시간(또는 준실시간)으로 생성할 수 있습니다.
- 개인화된 콘텐츠 크리에이션: SNS 크리에이터들이 특정 챌린지 동작을 자신의 캐릭터나 다른 배경에서 자유로운 카메라 워킹과 함께 재구성하여 창의적인 영상을 제작하는 도구로 활용될 것입니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critical Critique)
Senior AI Scientist로서 이 논문을 냉철하게 평가하자면, 몇 가지 극복해야 할 과제가 존재합니다.
- 계산 복잡도 (Computational Overhead): DiT 아키텍처에 Cross-attention 모듈이 다수 추가되면서 추론 시 연산량이 상당할 것으로 예상됩니다. 모바일 기기에서의 실시간 구동을 위해서는 가속화 기술이나 경량화 모델링이 필수적입니다.
- 데이터 편향성 (Data Bias): View-rich dataset을 강조했지만, 여전히 인간의 동작 범위는 무궁무진합니다. 특히 극단적인 각도(Top view 등)나 복잡한 의상을 입은 경우, 모델이 학습하지 못한 영역에서의 아티팩트가 발생할 가능성이 있습니다.
- SMPL 어닐링의 민감도: 보조 감독(Supervision)을 언제, 얼마나 빨리 줄일 것인가에 대한 스케줄링이 모델 성능에 민감하게 작용할 수 있습니다. 이는 하이퍼파라미터 튜닝에 많은 리소스를 소모하게 만듭니다.
- 기술적 비평: 이 연구는 ‘Implicit 3D’의 승리를 선언하고 있지만, 역설적으로 초기에 ‘Explicit 3D(SMPL)’의 도움 없이는 수렴이 어렵다는 것을 보여주기도 합니다. 결국 완전한 데이터 중심(Data-driven) 3D 인지로 가기 위한 과도기적 모델이라 볼 수 있습니다.
8. 결론 및 인사이트 (Conclusion)
3DiMo는 인간 비디오 생성에서 2D의 정밀함과 3D의 유연성을 결합한 매우 영리한 접근 방식입니다. 명시적인 기하학적 모델의 ‘딱딱함’을 버리고, 대규모 생성 모델이 가진 ‘유연한 공간 지능’을 선택한 것은 향후 비디오 생성 AI가 나아가야 할 방향을 제시하고 있습니다.
이제 인간 비디오 생성은 단순히 ‘따라 하는 것’을 넘어, ‘공간을 이해하고 재해석하는 단계’로 진입했습니다. 개발자와 비즈니스 리더들은 이러한 ‘시점 독립적인 제어 능력’이 가져올 콘텐츠 혁명에 대비해야 합니다. 3DiMo는 그 혁명의 최전선에 서 있는 기술이며, 앞으로 이를 기반으로 한 실시간 인터랙티브 비디오 서비스의 등장을 기대해 봅니다.
핵심 테이크아웃:
- 2D Pose는 시점에 갇히고, SMPL은 정확도에 갇힌다.
- 3DiMo는 ‘임플리시트 모션 토큰’으로 이 둘을 모두 극복했다.
- 3D 인식 능력은 외부 주입이 아니라, 데이터와 생성기 프라이어의 조화로 완성된다.
