[2026-02-02] 코드 이해의 새로운 지평: MLLM과 이미지 모달리티를 통한 'CodeOCR' 기술 심층 분석

1. 핵심 요약 (Executive Summary)
현대 대규모 언어 모델(LLM)은 소스 코드 이해 영역에서 비약적인 발전을 이루었으나, 소프트웨어 시스템의 규모가 커짐에 따라 계산 효율성(Computational Efficiency)이라는 거대한 벽에 직면해 있습니다. 기존의 텍스트 기반 패러다임은 코드를 선형적인 토큰 시퀀스로 처리하며, 이는 컨텍스트 길이가 늘어날수록 비용이 기하급수적으로 증가하는 문제를 야기합니다.
최근 발표된 “CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding” 논문은 이러한 한계를 극복하기 위해 코드를 ‘텍스트’가 아닌 ‘렌더링된 이미지’로 처리하는 혁신적인 접근법을 제시합니다. 본 분석에서는 멀티모달 LLM(MLLM)이 코드 이해에 있어 어떻게 8배 이상의 토큰 압축률을 달성하면서도 높은 성능을 유지하는지, 그리고 시각적 보조 지표(구문 강조 등)가 모델의 추론에 어떤 영향을 미치는지 기술적으로 심층 분석합니다. 특히, 클론 탐지(Clone Detection)와 같은 태스크에서 시각적 모달리티가 갖는 독보적인 탄력성과 향후 실무 적용 가능성을 진단합니다.
2. 연구 배경 및 문제 정의 (Introduction & Problem Statement)
2.1. 텍스트 기반 코드 모델의 한계
전통적인 코드 언어 모델(Code LLM)은 소스 코드를 단어 혹은 서브워드 단위의 토큰으로 분절하여 처리합니다. 이 방식은 문법적 정확성을 높이는 데 기여했으나, 대규모 프로젝트나 수만 라인에 달하는 레거시 코드를 분석할 때 다음과 같은 치명적인 단점을 노출합니다.
- 컨텍스트 윈도우의 압박: 토큰 수가 늘어남에 따라 Self-Attention 메커니즘의 연산 복잡도와 KV 캐시(Key-Value Cache) 메모리 점유율이 선형 또는 제곱 단위로 증가합니다.
- 의미적 압축의 어려움: 텍스트 데이터에서 토큰을 무작위로 제거하거나 요약할 경우, 코드의 실행 논리나 구문 구조가 완전히 파괴될 위험이 큽니다.
- 시각적 구조 정보의 소실: 개발자는 코드를 읽을 때 들여쓰기(Indentation), 구문 강조(Syntax Highlighting), 코드 블록의 배치 등 시각적 레이아웃을 통해 구조를 파악합니다. 텍스트 모델은 이러한 ‘2차원적 공간 정보’를 1차원 시퀀스로 변환하는 과정에서 정보 손실을 겪습니다.
2.2. 이미지 모달리티로의 패러다임 전환
본 연구는 “이미지는 텍스트보다 훨씬 효율적으로 압축 가능하다”는 가설에서 출발합니다. 이미지 해상도를 조절함으로써 정보의 밀도를 제어할 수 있으며, 최신 MLLM(GPT-4o, Claude 3.5 등)은 이미 이미지 내의 텍스트와 구조를 파악하는 OCR(Optical Character Recognition) 능력이 탁월합니다. 연구진은 이를 ‘CodeOCR’이라 명명하고, 코드를 이미지로 변환하여 입력했을 때의 효율성과 효과성을 검증하고자 합니다.
 Figure 1: 텍스트 기반 표현과 시각적(이미지) 기반 표현의 대비. 텍스트는 수많은 토큰을 소모하지만, 이미지는 해상도 조절을 통해 고정된 혹은 훨씬 적은 수의 시각적 패치로 변환될 수 있습니다.
Figure 1: 텍스트 기반 표현과 시각적(이미지) 기반 표현의 대비. 텍스트는 수많은 토큰을 소모하지만, 이미지는 해상도 조절을 통해 고정된 혹은 훨씬 적은 수의 시각적 패치로 변환될 수 있습니다.
3. 핵심 기술 및 아키텍처 심층 분석 (Core Methodology)
3.1. 시각적 코드 표현 프로세스
CodeOCR의 핵심은 소스 코드를 모델이 이해하기 가장 적합한 형태의 이미지로 렌더링하는 것입니다. 이 과정은 크게 세 단계로 나뉩니다.
- 렌더링(Rendering): 소스 코드를 특정 폰트, 크기, 테마(Light/Dark) 및 구문 강조(Syntax Highlighting) 규칙에 따라 이미지로 변환합니다.
- 해상도 스케일링(Resolution Scaling): 토큰 압축률을 결정하는 단계입니다. 고해상도 이미지는 더 많은 시각적 패치(Patch)를 생성하여 정확도를 높이지만, 저해상도 이미지는 토큰 비용을 획기적으로 낮춥니다.
- 멀티모달 인코딩(Multimodal Encoding): 시각적 인코더(예: CLIP 기반 Vision Encoder)를 통해 이미지를 임베딩 벡터로 변환하고, 이를 LLM 백본에 주입합니다.
3.2. MLLM 처리 파이프라인
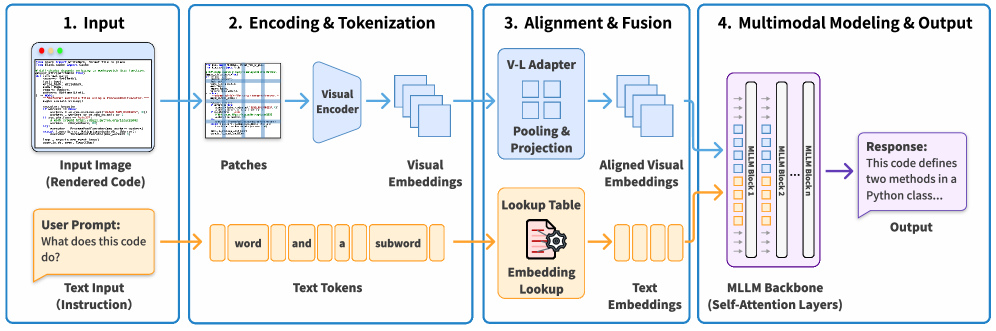 Figure 2: 코드가 이미지로 변환되어 MLLM에 입력되는 전체 파이프라인. 텍스트 토큰 방식과 달리 이미지 패치 단위로 연산이 이루어짐을 알 수 있습니다.
Figure 2: 코드가 이미지로 변환되어 MLLM에 입력되는 전체 파이프라인. 텍스트 토큰 방식과 달리 이미지 패치 단위로 연산이 이루어짐을 알 수 있습니다.
이 파이프라인에서 주목할 점은 ‘Token Reduction Ratio(TRR)’입니다. 연구팀은 텍스트 모델이 사용하는 토큰 수 대비 MLLM이 사용하는 비주얼 토큰(Visual Token)의 수를 조절하며 실험을 설계했습니다. 예를 들어, 1,000개의 텍스트 토큰이 필요한 코드를 단 125개의 비주얼 패치로 표현한다면 8배의 압축률을 달성하게 됩니다.
3.3. 시각적 단서(Visual Cues)의 역할
본 논문은 단순한 픽셀 정보를 넘어, 구문 강조(Syntax Highlighting)가 모델의 주의 집중(Attention)에 미치는 영향을 심도 있게 다룹니다. 색상 정보는 함수명, 키워드, 문자열 등을 시각적으로 분리해주며, 이는 모델이 저해상도 환경에서도 핵심 의미를 포착하는 데 결정적인 도움을 줍니다. 이는 인간 개발자가 코드의 대략적인 형태만 보고도 로직을 유추하는 과정과 유사한 ‘Inductive Bias’를 제공합니다.
4. 구현 및 실험 환경 (Implementation Details & Experiment Setup)
4.1. 실험 설계 개요
연구진은 체계적인 검증을 위해 세 가지 핵심 질문(Research Questions)을 설정했습니다.
- RQ1: MLLM은 시각적으로 렌더링된 코드를 얼마나 잘 이해하는가? (압축 한계 측정)
- RQ2: 구문 강조와 같은 시각적 요소가 성능에 기여하는가?
- RQ3: 코드 이해 태스크별로 시각적 압축에 대한 탄력성이 다른가?
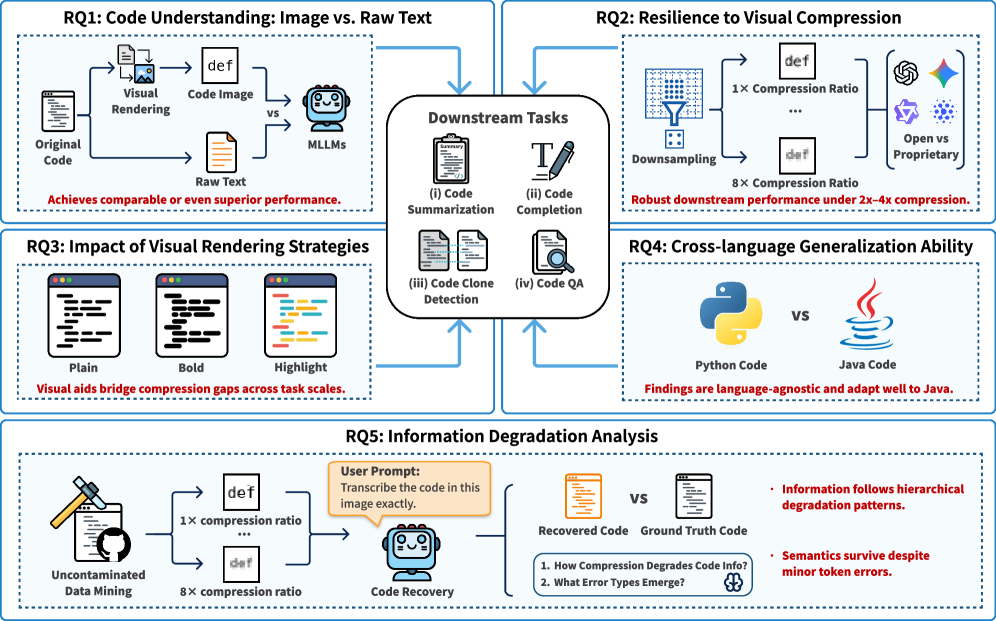 Figure 3: 실험 설계 및 주요 결과 요약. 다양한 태스크(Completion, Summarization, Clone Detection)에 걸친 모델 성능 변화를 보여줍니다.
Figure 3: 실험 설계 및 주요 결과 요약. 다양한 태스크(Completion, Summarization, Clone Detection)에 걸친 모델 성능 변화를 보여줍니다.
4.2. 데이터셋 및 벤치마크
- Code Completion: HumanEval, MBPP를 활용하여 코드 생성 및 완성 능력 평가.
- Code Summarization: 설명 생성 능력을 통해 의미론적 파악 능력 측정.
- Clone Detection: BigCloneBench 등을 사용하여 두 코드 간의 기능적 유사성 판단 능력 측정.
4.3. 사용 모델
실험에는 GPT-4o, Claude 3.5 Sonnet과 같은 폐쇄형 모델뿐만 아니라 LLaVA, InternVL 등 오픈소스 멀티모달 모델들이 폭넓게 활용되었습니다. 이를 통해 특정 모델의 성능이 아닌 이미지 모달리티 자체의 유효성을 검증했습니다.
5. 성능 평가 및 비교 (Comparative Analysis)
5.1. 압축률 대 성능의 트레이드오프
실험 결과, 8x 압축률까지는 대다수의 모델이 텍스트 기반 모델과 경쟁할 수 있는 수준의 성능을 유지했습니다. 특히, 컨텍스트가 매우 긴 프로젝트 단위의 코드에서 MLLM은 텍스트 모델이 겪는 ‘Lost in the Middle’ 현상(긴 시퀀스의 중간 정보를 잊어버리는 문제)을 시각적 레이아웃 보존을 통해 완화하는 경향을 보였습니다.
5.2. 태스크별 특이점: 클론 탐지의 탄력성
가장 놀라운 결과는 클론 탐지(Clone Detection) 태스크에서 나타났습니다. 이 태스크는 코드의 세부적인 오타보다는 전체적인 구조와 흐름의 유사성을 판단하는 것이 중요합니다. 실험 결과, 4x 이상의 압축 환경에서도 MLLM은 텍스트 모델과 거의 대등하거나, 심지어 특정 케이스에서는 더 높은 정확도를 기록했습니다. 이는 이미지 모달리티가 코드의 ‘추상적 패턴’을 포착하는 데 매우 효율적임을 시사합니다.
5.3. 구문 강조의 효용성
구문 강조를 적용한 이미지는 흑백(Monochrome) 이미지에 비해 특히 Code Completion 태스크에서 15~20% 이상의 성능 향상을 보였습니다. 색상 정보가 토큰 간의 경계를 명확히 하고, 제어 흐름(Control Flow) 관련 키워드에 가중치를 두도록 모델을 유도하기 때문인 것으로 분석됩니다.
6. 실제 적용 분야 및 글로벌 파급력 (Real-World Application & Impact)
이 연구가 산업계에 미칠 영향은 지대합니다. 단순한 벤치마크 점수를 넘어 실무적인 관점에서의 활용안은 다음과 같습니다.
- 초대규모 레거시 코드베이스 분석: 수백만 라인의 코드를 텍스트로 읽으려면 수만 개의 토큰 비용이 발생합니다. 이를 스크린샷 형태의 이미지 뭉치로 처리하면 비용을 1/10 수준으로 절감하면서도 아키텍처 수준의 분석이 가능해집니다.
- IDE 통합형 실시간 코드 리뷰: 개발자가 코드를 작성하는 동안 화면에 보이는 뷰포트(Viewport)를 그대로 MLLM에 전송하여 실시간 버그 탐지 및 가이드를 제공할 수 있습니다. 텍스트 추출 과정이 생략되므로 응답 속도가 향상됩니다.
- UI/UX 기반 프런트엔드 개발: 코드가 브라우저에 렌더링된 결과와 소스 코드를 동시에 이미지로 입력받아, 시각적 불일치(Visual Regression)를 찾아내거나 디자인 가이드라인 준수 여부를 판단하는 데 최적입니다.
- 보안 및 난독화 코드 분석: 텍스트 분석기가 읽기 힘들게 난독화된 코드라도, 시각적 패턴(루프 구조, 데이터 흐름)은 이미지 상에서 드러나는 경우가 많습니다. 이를 이용한 보안 취약점 분석이 가능합니다.
7. 한계점 및 기술적 비평 (Discussion: Limitations & Critical Critique)
본 시니어 과학자의 관점에서 이 논문은 매우 고무적이지만, 몇 가지 비판적 검토가 필요합니다.
첫째, 렌더링 오버헤드 문제입니다. 코드를 이미지로 변환하는 과정 자체에 컴퓨팅 자원이 소모됩니다. 특히 대량의 파일을 처리할 때 CPU/GPU 기반 렌더링 속도가 병목 현상이 될 수 있습니다. 논문에서는 이 비용과 추론 시 절감되는 토큰 비용 사이의 명확한 손익분기점을 다루지 않았습니다.
둘째, 미세 정보의 소실(Fine-grained Information Loss)입니다. 8배 압축 시 작은 변수명(예: i와 l)이나 미세한 연산자(+와 ++)가 픽셀 뭉침 현상으로 인해 오인될 가능성이 큽니다. 이는 정밀함이 생명인 컴파일러 수준의 작업에는 치명적일 수 있습니다.
셋째, 가변 해상도 대응 능력입니다. 고정된 패치 크기를 사용하는 현재의 MLLM 아키텍처에서 코드의 길이에 따라 해상도를 유동적으로 조절하는 방식은 모델 학습 단계에서의 정교한 정렬(Alignment)을 요구합니다. 현재는 기학습된 범용 MLLM에 의존하고 있어, ‘코드 전용 시각적 토크나이저’가 부재하다는 점이 아쉽습니다.
8. 결론 및 인사이트 (Conclusion)
CodeOCR 연구는 코드 이해를 단순히 언어 모델링의 영역에서 시각적 인지(Visual Perception)의 영역으로 확장시켰다는 점에서 패러다임의 전환을 의미합니다. “텍스트는 선형적이지만, 코드는 구조적이다”라는 명제를 이미지 모달리티를 통해 증명해냈습니다.
향후 이 기술은 텍스트 토큰과 비주얼 패치를 혼합하여 사용하는 하이브리드 모달리티(Hybrid Modality) 방향으로 발전할 것으로 보입니다. 중요한 로직은 텍스트로 정밀하게 읽고, 반복되는 구조나 방대한 컨텍스트는 이미지로 압축하여 처리하는 방식입니다.
결론적으로, 본 논문은 MLLM이 단순한 이미지 설명을 넘어 복잡한 공학적 논리 구조를 가진 코드까지 시각적으로 해석할 수 있음을 보여주었으며, 이는 차세대 AI 기반 소프트웨어 공학(AISE)의 핵심 초석이 될 것입니다. 개발자라면 이제 자신의 코드가 모델에게 어떻게 ‘보이는지’에도 관심을 가져야 할 시점입니다.
