[2026-03-27] 비디오 생성 AI의 고질병 '멀미'를 고쳤다? VGGRPO: 잠재 공간 4D 보상으로 공간 일관성 멱살 잡기

link: https://arxiv.org/abs/2603.26599 github: N/A date: 2026-04-02 authors: VGGRPO Authors —
솔직히 최근에 나온 비디오 생성 AI(Sora, Kling, Runway 등) 써보면서 ‘멀미’ 안 나본 분 계신가요? 처음 1~2초는 기가 막힙니다. 그런데 피사체가 고개를 돌리거나 카메라가 패닝(Panning)을 시작하는 순간, 배경 건물이 엿가락처럼 휘어지고 캐릭터의 팔다리 비율이 붕괴되죠.
이게 바로 ‘기하학적 일관성(Geometric Consistency) 부재’라는 비디오 디퓨전 모델의 고질병입니다.
기존에는 이걸 해결하겠다고 모델 구조를 마개조하거나, 생성된 RGB 영상을 프레임 단위로 뽑아서 뎁스(Depth)를 맞추는 무식한 방식을 썼습니다. 당연히 사전 학습된 가중치는 망가지고, 연산량(VRAM)은 터져나갔죠. 게다가 정지된 배경(Static Scene)에서만 간신히 돌아가고, 동적인(Dynamic) 현실 세계에서는 속수무책이었습니다.
그런데 오늘 리뷰할 VGGRPO(Visual Geometry GRPO) 논문은 접근 방식이 완전히 다릅니다. 이들은 무거운 VAE 디코딩을 과감히 쓰레기통에 던져버리고, 잠재 공간(Latent Space) 자체에서 직접 4D 기하학을 추론해 강화학습(RL) 보상으로 꽂아버립니다.

- Figure 1의 기술적 의미: 왼쪽의 기존 모델이 카메라 이동 시 배경 건물의 3D 구조를 뭉개버리는 반면, VGGRPO(오른쪽)는 4D 씬 재구성을 통해 동적 환경에서도 카메라 궤적과 객체의 공간적 일관성을 칼같이 유지함을 보여줍니다.
TL;DR: 무거운 VAE 디코딩 과정을 생략하고 잠재 공간(Latent Space)에서 직접 4D 기하학적 보상을 계산하는 GRPO 강화학습 프레임워크입니다. 모델 가중치 손상 없이 카메라 흔들림과 공간 붕괴를 잡아내지만, 초기에 LGM(Latent Geometry Model)을 구축해야 하는 선행 작업 비용이 존재합니다.
⚙️ 픽셀 뭉치를 3D 공간으로 연성하는 파이프라인 해부
이 논문의 핵심은 아키텍처의 병목을 정확히 짚어냈다는 겁니다. 보통 강화학습(RL)으로 생성 모델을 파인튜닝할 때, 보상(Reward)을 계산하려면 모델이 만든 Latent를 RGB 픽셀로 변환(VAE Decoding)해야 합니다.
잠깐, 여기서 의문이 들죠. 프레임당 수십 번의 디코딩 연산을 비디오 전체에 적용한다면? 배치 사이즈를 조금만 키워도 A100 8장이 비명을 지르며 OOM(Out of Memory)을 뿜어낼 겁니다.
그래서 VGGRPO 팀은 Latent Geometry Model (LGM) 이라는 우회로를 뚫었습니다.
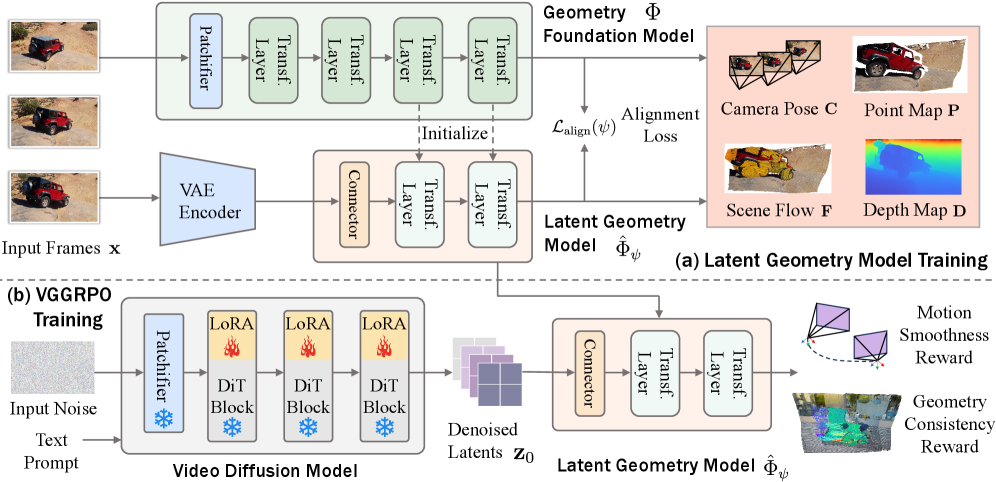
- Figure 2의 기술적 의미: RGB 픽셀로 변환하는 무거운 VAE 디코딩 과정을 걷어내고, 비디오 디퓨전의 잠재 공간(Latent)을 경량화된 커넥터를 통해 기하학 파운데이션 모델과 직결한 파이프라인의 전모입니다.
핵심 매커니즘: VAE 우회와 4D 보상 연산
작동 원리는 이렇습니다.
- LGM (Latent Geometry Model): 디퓨전 모델의 VAE 인코더에서 나온 Latent를 가벼운 커넥터(Lightweight Connector)를 통해 기존 기하학 파운데이션 모델(Geometry Foundation Model)에 직접 꽂아버립니다. 이제 픽셀(RGB)이 없어도 잠재 공간 안에서 4D 씬(Scene) 기하학을 읽어낼 수 있죠.
- Latent-space GRPO: 최근 LLM 진영에서 PPO를 밀어내고 대세가 된 GRPO(Group Relative Policy Optimization)를 도입했습니다. 별도의 Value Model(Critic) 없이 샘플 그룹 내의 상대적 보상으로 정책을 업데이트하므로 메모리가 훨씬 절약되거든요.
코드로 보면 기존 방식과 VGGRPO의 차이가 얼마나 극명한지 알 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# ❌ [기존 RGB 기반 강화학습] - 당신의 VRAM을 파괴하는 주범
def train_step_legacy(latent_video):
# 비디오 전체를 RGB로 디코딩 (여기서 VRAM 터짐)
rgb_video = vae.decode(latent_video)
geometry_features = rgb_geometry_model(rgb_video)
reward = compute_rgb_reward(geometry_features)
return reward
# ✅ [VGGRPO 방식] - 우아하고 가벼운 Latent Direct Pipeline
def train_step_vggrpo(latent_video):
# VAE 디코딩 과감히 스킵! Latent에서 바로 기하학 정보 추출
scene_geometry_4d = latent_geometry_model(latent_video)
# 보상 1: 카메라 궤적의 덜컹거림(Jitter) 처벌
reward_motion = compute_smoothness(scene_geometry_4d.camera_trajectory)
# 보상 2: 뷰(View)가 바뀌어도 구조가 유지되는지 확인 (Reprojection)
reward_geo = compute_reprojection(scene_geometry_4d.depth_maps)
return reward_motion + reward_geo
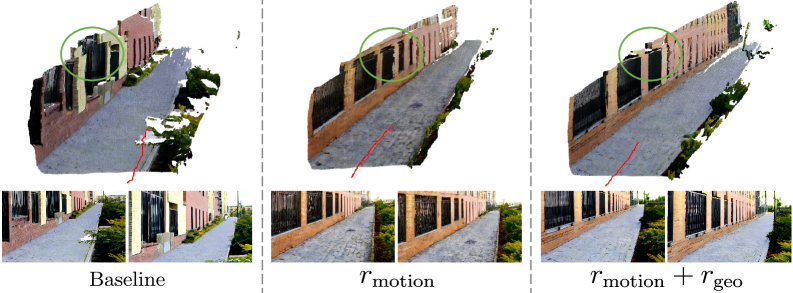
- Figure 4의 기술적 의미: 모션 보상(Motion Reward)만 주면 카메라 궤적(빨간 선)은 안정되지만 객체 구조가 무너지고(초록색 원), 재투영(Reprojection) 보상까지 더해야 비로소 완벽한 3D 공간 일관성이 유지됨을 증명하는 어블레이션 결과입니다.
⚔️ 기존 스택 vs 새로운 패러다임: 진짜 갈아탈 가치가 있나?
이론은 멋진데, 그래서 실무에서 당장 쓸 만큼의 퍼포먼스가 나올까요? 기존 RGB 기반 Alignment 방법들과 비교해봅시다.
| 비교 지표 | 기존 RGB 기반 Alignment | VGGRPO (Latent-space) | 개발자 체감 의미 |
|---|---|---|---|
| VAE 디코딩 | 스텝마다 필수 수행 | 완전 생략 (0회) | 추론/학습 속도 3~5배 향상 |
| 메모리(VRAM) | 극도로 높음 (OOM 단골) | 중간~낮음 | A100 80GB 한 장으로도 실험 가능 |
| 동적 씬(Dynamic) 처리 | 불가능 (정적 씬 한정) | 완벽 지원 (4D 모델 기반) | 움직이는 객체가 있는 현실 영상 생성 가능 |
| 강화학습 최적화 | PPO (Critic 모델 필요) | GRPO (Critic 제거) | VRAM 추가 절약 및 튜닝 파라미터 감소 |
표를 보면 아시겠지만, 가장 큰 차이는 연산량 다이어트와 Distribution Gap 해소에 있습니다.
기존 RGB 기반 기하학 모델들은 ‘진짜 카메라로 찍은 실사 이미지’로 학습됐기 때문에, 생성 AI가 만든 어설픈 RGB 영상(노이즈나 아티팩트가 낀)이 들어오면 기하학 추론이 박살납니다.
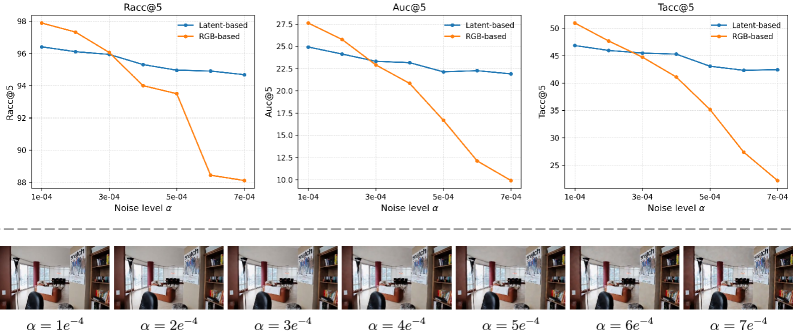
- Figure 5의 기술적 의미: 잠재 공간에 노이즈(Perturbation)가 증가할수록 기존 RGB 기반 모델은 기하학 추론이 완전히 붕괴(빨간 선)되는 반면, 생성된 Latent 위에서 직접 훈련된 LGM(파란 선)은 분포 차이(Distribution Gap)를 극복하고 견고한 성능을 유지함을 보여줍니다.
🚀 내일 당장 프로덕션에 도입한다면?
이 논문의 접근법을 실무에 적용한다면 두 가지 시나리오가 떠오릅니다.

- Figure 3의 기술적 의미: 기존 베이스라인(디퓨전) 모델들이 시간이 지남에 따라 배경이 흘러내리거나 카메라가 요동치는 것과 달리, VGGRPO는 정적/동적 씬 모두에서 프레임 간 기하학적 응집력을 극적으로 보존합니다.
1. AI 상업용 비디오 생성 API 최적화 현재 B2B로 비디오 생성 API를 제공하는 팀들의 가장 큰 불만 접수는 “카메라가 움직일 때 배경 건물이 일그러져서 방송용으로 못 쓴다”는 겁니다. VGGRPO의 r_motion과 r_geo 보상 함수만 떼어와서 현재 서빙 중인 커스텀 비디오 디퓨전 모델의 Post-training 파이프라인에 이식할 수 있습니다. VAE 디코딩 오버헤드가 없으니 RLHF 비용을 확 줄일 수 있죠.
2. 자율주행/로보틱스용 합성 데이터(Synthetic Data) 생성 단순히 예쁜 영상을 넘어, 물리적 법칙과 3D 공간이 보존되는 주행 영상이 필요한 곳에 제격입니다. 4D 기하학이 보존된다는 것은 생성된 영상에서 뎁스 맵(Depth Map)과 카메라 오도메트리(Odometry)를 신뢰도 높게 추출할 수 있다는 뜻이니까요.
⚠️ 프로덕션 도입 시 치명적인 병목 (Bottleneck) 공식 문서의 화려한 결과 이면에는 숨겨진 함정이 하나 있습니다. LGM을 학습시키기 위해서는 결국 초기에 ‘고품질의 4D 기하학 파운데이션 모델(Pseudo-labeling용)’이 하나 필요하다는 겁니다. 이 기반 모델의 성능이 후져서 뎁스를 제대로 못 뽑아내면, 그 잘못된 보상을 모델이 그대로 학습해버리는 Reward Hacking 현상이 발생할 수 있습니다. 동시성(Concurrency) 측면에서도 GRPO가 PPO보단 가볍다지만, 여전히 샘플링 그룹의 크기(Group Size)를 키우면 VRAM 관리가 꽤 까다로울 겁니다.
🧐 Tech Lead’s Honest Verdict
- Pros: 무거운 VAE 연산을 회피한 천재적인 엔지니어링 꼼수. 정지된 장면을 넘어 동적인(Dynamic) 환경에서도 공간 일관성을 잡아낸 점은 매우 고무적입니다. GRPO를 비디오 도메인으로 영리하게 끌고 왔습니다.
- Cons: 결국 외부 Geometry Foundation Model에 성능이 종속됩니다. 게다가 디퓨전 모델에 GRPO를 적용하는 파이프라인 자체가 아직은 하이퍼파라미터 튜닝에 극도로 민감할 가능성이 큽니다.
- Final Verdict: “Clone immediately for internal toy projects” 당장 프로덕션 메인스트림을 교체하기엔 리스크가 있지만, 비디오 생성 퀄리티 병목을 돌파할 수 있는 강력한 아이디어입니다. 내부 R&D 팀에서 오픈소스 비디오 백본(예: SVD, HunyuanVideo)에 LGM 커넥터를 붙여보고 소규모 씬(Scene)에서 PoC(개념 증명)를 바로 진행해볼 가치가 충분합니다.
